









太多公式,只能发图,全英版提高逼格~







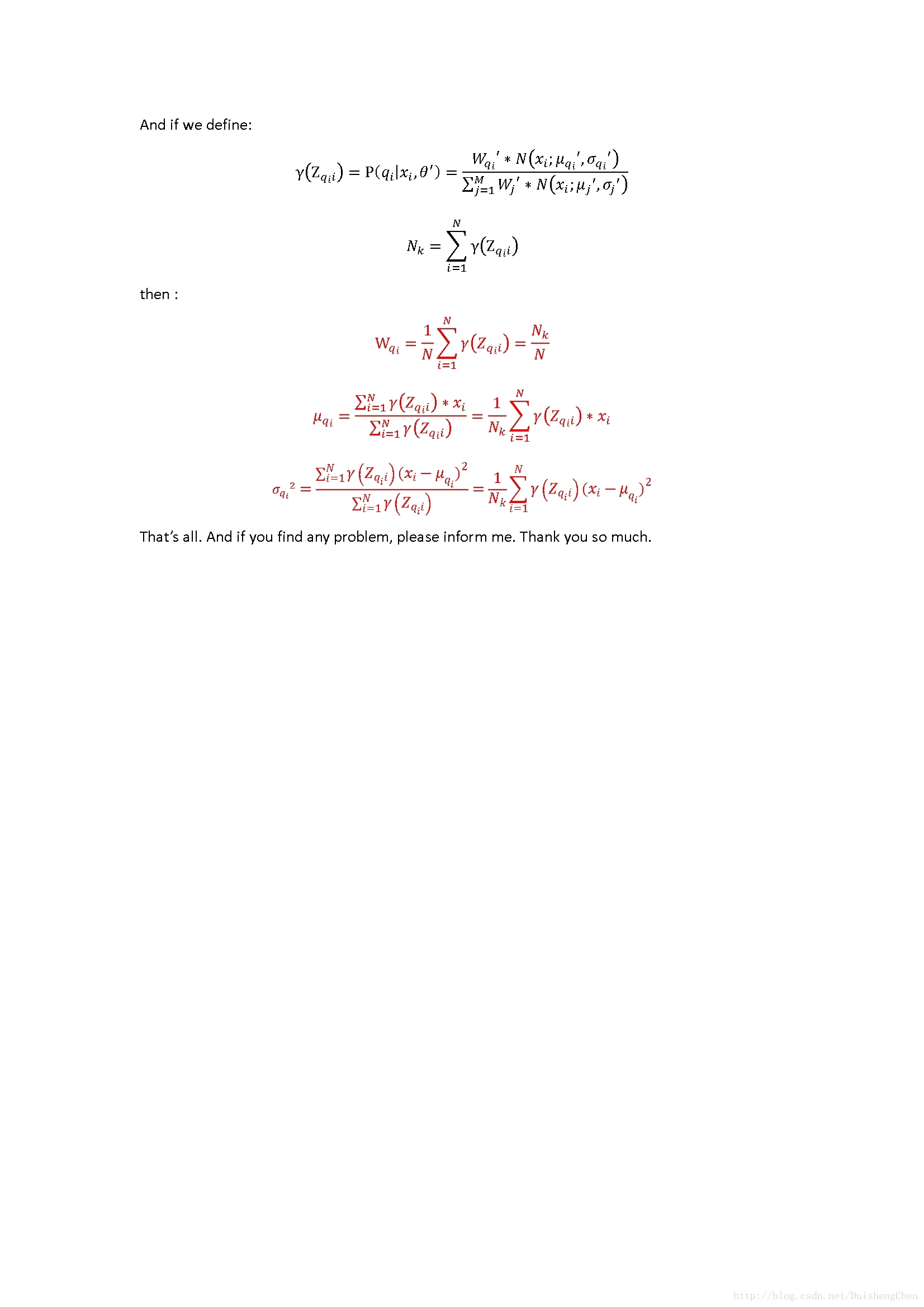
以下是GMM训练的matlab代码,为了加快收敛的速度,在训练之前加入了K-means聚类算法,初步估计聚类的means,weights,variences;
function TrainGMM()
clear;
Sample=getGMMSample(10000);
%利用K_Means方法现对样本进行聚类,减少GMM的计算次数,加快GMM的训练速度
[weights0,means0,conv0]=K_Means(Sample,3);%利用K-means方法加快收敛
[weights,means,conv]=estimateGMM(Sample,3,weights0,means0,conv0);
function Sample=getGMMSample(SampleNum)
%符合混合高斯分布的数据生成函数
weight1=0.2;
miu1=30; %第一个分布的参数
sigma1=10;%第一个分布的参数 标准差
weight2=0.5;
miu2=100;%第二个分布的参数
sigma2=25;%第二个分布的参数 标准差
weight3=0.3;
miu3=190;%第二个分布的参数
sigma3=20;%第二个分布的参数 标准差
x=0:1:255;
y1=normcdf(x,miu1,sigma1);
y2=normcdf(x,miu2,sigma2);
y3=normcdf(x,miu3,sigma3);
y=weight1*y1+weight2*y2+weight3*y3;
u=0.002+0.996*rand(1,SampleNum);
Sample=round(interp1(y,x,u,'linear'));
function [weights,means,conv]=estimateGMM(Sample,numOfGaussiant,weights0,means0,conv0)
numOfSample=size(Sample,2);
weights=weights0;
means=means0;
conv=conv0;
qiutThread=1e-5;
%calculate the P(q|X,weights,means,conv)
while(1)
GaussianOutput=zeros(numOfGaussiant,numOfSample);
for i=1:1:numOfGaussiant
%在现有假设的高斯模型下,对当前样本的概率进行计算
% weight(i)*N(xj|(i)th compose of the old model ) j=[0:1:numOfSample];
singleGaussiant=normpdf(Sample,means(i),conv(i));
GaussianOutput(i,:)=weights(i).*singleGaussiant;
end
%E-step calculate the expatation
%计算P(xi|old model)
oldGMMForOutput=sum(GaussianOutput,1);
eachComposeContributeToOutput=zeros(numOfGaussiant,numOfSample);
for i=1:1:numOfGaussiant
%计算P(q|xj,old model)
% =weight(i)*P(xj|(i)th compose of the old model)/P(xj|old model)
eachComposeContributeToOutput(i,:)=GaussianOutput(i,:)./oldGMMForOutput;
end
%M-step maxmize the estimation
%计算sum(P(q|xi,old model))
Nq=sum(eachComposeContributeToOutput,2)';
%计算xi*P(q|xi,old model)
tempmartixForMeans=zeros(numOfGaussiant,1);
for j=1:1:numOfGaussiant
tempmartixForMeans(j,:)=eachComposeContributeToOutput(j,:)*Sample';% eachComposeContributeToOutput(j,:)是行向量 Sample' 是列向量
end
%update means;
means=(tempmartixForMeans')./Nq
tempmartixForConvs=zeros(numOfGaussiant,1);
for j=1:1:numOfGaussiant
tempmartixForConvs(j,:)=eachComposeContributeToOutput(j,:)*((Sample-means(j)).^2)';
end
%update conv
conv=sqrt((tempmartixForConvs')./Nq) %方差开方变标准差
%update weight
weights=Nq./numOfSample
pause(1);
%画图
drawDistribution(Sample,weights,means,conv);
%退出条件:产生序列的似然概率变化达到阈值
loglikehoodOldModel=sum(log(ModelOutputProbility(Sample,numOfGaussiant,weights0,means0,conv0)));
loglikehoodNewModel=sum(log(ModelOutputProbility(Sample,numOfGaussiant,weights,means,conv)));
if abs(loglikehoodOldModel-loglikehoodNewModel)<qiutThread
break;
else
weights0=weights;
means0=means;
conv0=conv;
end
end
function [weights,means,convs]=K_Means(Sample,numOfCluser)
sampleNum=size(Sample,2);
means=round(255*rand(1,3));%随机得到分类中心
means0=means;
threadHold=1e-5;%停止阈值
while(1)
%计算每个样本到达分类中心的距离
distanceSampleMeans=zeros(numOfCluser,sampleNum);
for i=1:1:numOfCluser
distanceSampleMeans(i,:)=Sample-means(i);%计算距离:此处计算的是一维的欧氏距离。
end
absDistanceSampleMeans=abs(distanceSampleMeans);%取绝对值,方便下一步将点归类
%将点分配到距离它最近的类中
cluserMartrix=zeros(numOfCluser,sampleNum);
for i=1:1:sampleNum
[minValue,minimumLocation]=min(absDistanceSampleMeans(:,i));%计算最近距离的位置
cluserMartrix(minimumLocation,i)=1;
end
pointAsignToCluser=sum(cluserMartrix,2);%计算分配到每个类的点的个数
%计算重新分配后的点聚类群的均值
cluserCenter=zeros(1,numOfCluser);
for i=1:1:numOfCluser
cluserCenter(1,i)=(Sample*cluserMartrix(i,:)')./pointAsignToCluser(i);
end
means=cluserCenter;%更新均值
weights=pointAsignToCluser'./sampleNum;%更新权重
if min(abs(means-means0))<threadHold %求means最小变化值是否已经小于阈值
%重新计算分类:
cluserMartrix=zeros(numOfCluser,sampleNum);
for i=1:1:numOfCluser
distanceSampleMeans(i,:)=Sample-means(i);
end
absDistanceSampleMeans=abs(distanceSampleMeans);
cluserMartrix=zeros(numOfCluser,sampleNum);
for i=1:1:sampleNum
[minValue,minimumLocation]=min(absDistanceSampleMeans(:,i));
cluserMartrix(minimumLocation,i)=1;
end
%###################################
convs=zeros(1,numOfCluser);
for i=1:1:numOfCluser
bufferSample=((Sample-means(i)).^2)*cluserMartrix(i,:)';
convs(1,i)=sqrt(bufferSample/sum(cluserMartrix(i,:)));%标准差
end
%画混合高斯模型图:利用K-means方法估计的权重,均值和标准差
X=[0:1:255];
Y=weights(1)*normpdf(X,means(1),convs(1))+weights(2)*normpdf(X,means(2),convs(2))+weights(3)*normpdf(X,means(3),convs(3));
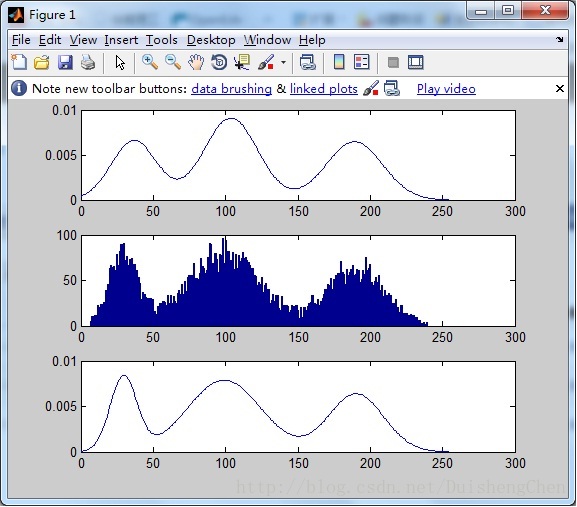
subplot(3,1,1);
plot(X,Y);
%
break;
else
means0=means;
end
end
function ProbilityVector=ModelOutputProbility(Sample,numOfGaussiant,weights,means,conv)
%P(xi|weights,means,conv)
GaussianOutput=zeros(numOfGaussiant,size(Sample,2));
for i=1:1:numOfGaussiant
%在高斯模型下,对当前样本的概率进行计算
% weight(i)*N(xj|(i)th compose of the old model ) j=[0:1:numOfSample];
GaussianOutput(i,:)=weights(i)*normpdf(Sample,means(i),conv(i));
end
%E-step calculate the expatation
%计算P(xi|old model)
ProbilityVector=sum(GaussianOutput,1);
function drawDistribution(Sample,weights,means,conv)
%画图
%数据分布
xx=1:1:255;
yy=hist(Sample,xx);
subplot(3,1,2)
bar(xx,yy);
%混合模型
X=[0:1:255];
Y=weights(1)*normpdf(X,means(1),conv(1))+weights(2)*normpdf(X,means(2),conv(2))+weights(3)*normpdf(X,means(3),conv(3));
subplot(3,1,3);
plot(X,Y);
算法运行效果截图:















 4614
4614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









