







实验内容
本次实验主要通过运动python语言实现了一种基于混合高斯模型(GMM)的前景检测算法,其思想主要参考论文[4][7][8]。
本次实验使用WavingTrees[9]数据来进行实验。该数据全由bmp图片组成,如图一所示。本实验将使用前200帧背景对GMM模型进行训练,然后使用剩余的87帧图片用于测试。

图1 WavingTrees数据
实验步骤
具体步骤如下:
- 将模型的矩阵参数进行初始化,即将每个高斯函数的均值,方差和权值都初始化为0;
- 将WavingTrees数据中前200帧背景对GMM模型进行训练。在训练时,各个像素点的特征由7个高斯模型来表示。第一帧图像传入时,设置其固定的初始方差为100,权值为0.005。其他帧传入时,则是通过将像素值与已有的高斯均值比较,如果该像素值与某个高斯模型的均值差在方差的3倍以内,则认为该像素点匹配此高斯模型,即可认为该像素点属于背景点。然后对当前的均值、方差和权值进行更新。
- 在选择哪个高斯模型能更好的描述像素点,混合高斯模型中的每个单高斯模型的权重降序排列。在更新了模型的参数后,可以从匹配到的模型向前重新排列单高斯模型的顺序,因为只要模型与像素点匹配才会更新模型的参数。按照这种方式,能够选择出最适合表达该区域像素点的模型,逐渐剔除不合适的高斯模型。被选择作为当前的背景模型,模型的数量需要满足:
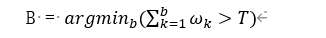
这里的T是判断一个像素点是否属于背景的最低阈值。如果一个像素值与混合高斯模型中的一个单高斯模型匹配,但权值和不大于T,该像素点仍然被判断为前景点。
测试
在测试阶段,将剩余的87帧图片中的像素值与最终选出的最合适的B个高斯模型的 每个均值进行比较,并用训练步骤(3)中提到的同样的匹配原则,进行匹配,匹配到某高斯模型则认为是背景,否则认为是前景。将被认为是前景的像素点赋值为255,背景像素点为0,可以得到前景的二值化图像,如图2所示。

图2 前景二值化图像
如图2所示,得到的前景二值化图像中包含由很多噪声,人物背景中摇摆的树枝树叶对前景的检测造成了影响。因此,我们考虑使用形态学操作,对前景二值化图像作进一步的处理。
这里用到的形态学操作主要由两种:膨胀和腐蚀(Dilation and Erosion)。膨胀和腐蚀常在二值图像上执行,膨胀通过将像素添加到该图像中的对象的感知边界,扩张放大图像中的明亮白色区域;而腐蚀恰恰相反,它沿着物体边界移除像素并缩小物体的大小。通常这两个操作是按顺序执行的,以增强重要的对象特征。
本实验主要对前景二值图像先作腐蚀再膨胀(这样的组合称为开运算)。主要是通过调用OpenCV库中的cv2.erode()和cv2.dilate()函数来实现。腐蚀首先清除噪声(并收缩物体)如何膨胀再次扩大物体,这一过程可以有效降低原始图像中的噪声。如图3所示,前景二值图像中的噪声有效降低。

图3 形态学操作后的前景图像
实验结果
实验结果如图4和图5所示。我们将原始图像、前景二值图像、形态学操作后的前景图像,以及检测出的前景图与原始图像的结合图像放在一起,进行对比,可以看出基于GMM的前景检测算法具有较好的表现。

图4 实验结果对比图(1)

图5 实验结果对比图(2)
实验的生成的视频文件可在附件中找到(result7.mp4)。
目前,OpenCV库已经实现了基于混合高斯模型的前景分割算法,通过调用cv2.createBackgroundSubtractorMOG(),通过传入一些参数即可实现。直接调库较为简单,本实验不使用此方法。
具体代码
def filelist(dir, type):
"""Read all files under the folder
Args:
dir: the folder path str
type: the file type str
Return:
namelist: contains a list of all files that meet the criteria list
"""
namelist=[]
for filename in os.listdir(dir):
if filename.endswith(type):
namelist.append(dir+'/'+filename)
return np.sort(namelist).tolist()
class GMM:
"""Mixed Gaussian model
Args:
K: the number of Gauss models int
alpha: the learning rate float
T: the threshold value float
initImg: initial image float (H*W*C)
initSigma: initial variance float
initWeight: initial weight float
"""
def __init__(self, K, alpha, T, initImg, initSigma, initWeight):
self.K = K
self.alpha = alpha
self.T = T
self.initSigma = initSigma
self.initWeight = initWeight
self.imgSize = initImg.shape
self.mu, self.sigma, self.weight = self.init_GMM(initImg)
def init_GMM(self, initImg):
"""Initialize the mean weight variance of the model
Args:
initImg: The image used to initialize float (H*W*C)
Return:
mu: Mean value matrix float (K*H*W*C)
sigma: Variance matrix float (K*H*W*C)
weight: Weight matrix float (K*H*W*C)
"""
Z = np.repeat(np.expand_dims(np.zeros(self.imgSize, dtype=float), axis=0), self.K-1,axis=0)
O = np.expand_dims(np.ones(self.imgSize, dtype=float), axis=0)
mu = np.expand_dims(initImg,axis=0)
mu = np.concatenate((mu,Z),axis=0)
sigma = np.concatenate((self.initSigma*O,Z),axis=0)
weight = np.concatenate((O,Z),axis=0)
return mu, sigma, weight
@staticmethod
def readimg(imgname):
"""Read the image, use opencv method, return float type, prevent overflow
Args:
imgname: Image path str
Return:
img: float (H*W*C)
"""
img = cv2.imread(imgname)
return img.astype(float)
@staticmethod
def showimg(*imgs, nx=1, ny=1, size=(160,120), scale=1, name='FIGURE', show_img=False):
"""The algorithm of displaying multiple images, the insufficient position is filled with blank
Args:
*imgs: img1, img2, ..., imgn a group of images
nx: Number of images displayed vertically int
ny: Number of images displayed horizontally int
size: image size tuple
scale: Scale transformation float/int/double
name: The window name str
Return:
imgbox: A collection of packaged images float
"""
n_img = len(imgs)
iter_img = 0
scaled_size = (np.ceil(size[0]*scale).astype(np.int),np.ceil(size[1]*scale).astype(np.int))
for i in range(nx):
for j in range(ny):
if iter_img>=n_img:
add_img = cv2.resize((imgs[0]*0+255).astype(np.uint8), scaled_size)
else:
add_img = cv2.resize(imgs[iter_img].astype(np.uint8), scaled_size)
if j == 0:
yimgs = add_img
else:
yimgs = np.hstack([yimgs, add_img])
iter_img += 1
if i == 0:
imgbox = yimgs
else:
imgbox = np.vstack([imgbox, yimgs])
if show_img:
cv2.namedWindow(name)
cv2.imshow(name,imgbox)
cv2.moveWindow(name,200,50)
cv2.waitKey(0)
cv2.destroyAllWindows()
return imgbox
def matcher(self, img, match_first=True, mask=None):
"""Determines whether it matches a distribution
Args:
img: float (H*W*C)
match_first: Whether to keep only the first match boolean
mask: for test,mask is the Threshold mask matrix int (K*H*W*C)
Retuen:
match: The matched matrix int (K*H*W*C)
unmatched: unmatched locations int (H*W*C)
"""
match = np.sum((np.square(self.mu-img)<(self.sigma*6.25)), axis=-1).astype(float)
match[match<2.5] = 0.0
match[match>2.5] = 1.0
match = np.repeat(np.expand_dims(match,axis=-1), 3, axis=-1) # repeat 3
if match_first:
tmp = np.zeros(match[0].shape)
for i in range(0, match.shape[0]):
ntmp = tmp + match[i]
match[i] -= tmp
tmp = ntmp
match[match>0.1] = 1.0
match[match<=0.1] = 0.0
if mask is not None:
unmatched = 1.0 - np.max(match*mask, axis=0)
else:
unmatched = 1.0 - np.max(match, axis=0)
return match, unmatched
def update(self, img, match, unmatched):
"""
Args:
img: picture float (H*W*C)
match: The matched matrix int (K*H*W*C)
unmatched: Record mismatched locations int (H*W*C)
"""
rho = self.alpha*(1/(np.sqrt(2*3.14*self.sigma+1e-10)) * np.exp(-0.5*np.square(self.mu-img)/(self.sigma+1e-10)))
# rho[rho>1.0] = 1.0
self.mu = (1.0-match)*self.mu + match*((1.0-rho)*self.mu+rho*img)
self.sigma = (1.0-match)*self.sigma + match*((1.0-rho)*self.sigma+rho*np.square(self.mu-img))
self.weight = (1-self.alpha)*self.weight + self.alpha*match
index = np.argsort(-(self.weight/(np.expand_dims(np.mean(self.sigma),axis=-1)+1e-10)),axis=0) #/(np.expand_dims(np.mean(sigma),axis=-1)+1e-10)
self.weight = np.take_along_axis(self.weight,index,axis=0)
self.mu = np.take_along_axis(self.mu,index,axis=0)
self.sigma = np.take_along_axis(self.sigma,index,axis=0)
self.mu[-1] = img*unmatched + (1-unmatched)*self.mu[-1]
self.sigma[-1] = np.expand_dims(np.ones(self.imgSize, dtype=float), axis=0)*self.initSigma*unmatched +(1-unmatched)*self.sigma[-1]
self.weight[-1] = np.expand_dims(np.ones(self.imgSize, dtype=float), axis=0)*self.initWeight*unmatched +(1-unmatched)*self.weight[-1]
self.weight = self.weight/(np.sum(self.weight,axis=0)+1e-10)
def B_mask(self): #Selection of adaptive GMM number for different pixel points
"""Make a threshold selection mask
Return:
mask: int (K*H*W*C)
"""
mask = np.zeros(self.weight.shape)
mask[0] = self.weight[0]
for i in range(1, mask.shape[0]):
mask[i] = mask[i-1]+self.weight[i]
for i in range(mask.shape[0]-2,-1,-1):
mask[i+1] = mask[i]
mask[mask>self.T] = 1 # self.T = 0.9
mask[mask<=self.T] = 0
mask = 1 - mask
mask[0] = np.ones(mask[0].shape)
return mask
def train_model(self, imgnamelist, match_first=True, show_img=False):
""" train the model
Args:
imgnamelist: image names list list contains str
match_first: Whether to keep only the first one boolean
"""
for imgname in tqdm(imgnamelist):
img = self.readimg(imgname)
match, unmatched = self.matcher(img, match_first=match_first)
self.update(img, match, unmatched)
self.showimg(img, unmatched*255, ny=2, nx=1, size=(img.shape[1],img.shape[0]), scale=2, show_img=show_img)
def test_model(self, imgnamelist, save_method='video', save_name='result', show_img=False):
""" test the model
Args:
imgnamelist: image names list list contains str
save_method: the saved method in 'video', 'image'
save_name: the name of result
"""
if save_method == 'video':
fps = 8
size = (self.imgSize[1]*4,self.imgSize[0]*4)
fourcc = cv2.VideoWriter_fourcc('a', 'v', 'c', '1')
outv = cv2.VideoWriter()
outv.open('./'+save_name+'.mp4', fourcc, fps, size)
mask = self.B_mask()
kernel_ero = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) #MORPH_ELLIPSE
kernel_dil = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) #MORPH_RECT
iimg = 0
for imgname in tqdm(imgnamelist):
img = self.readimg(imgname)
match, unmatched = self.matcher(img, match_first=False, mask=mask)
#Image Erosion and Dilation
#Morphological operation
eroded= cv2.erode(unmatched, kernel_ero) #Erosion
dilated = cv2.dilate(eroded, kernel_dil) #Dilation 确定扩张的内核为 5×5
padded = dilated*img
#Output: original image, foreground image, image after morphological processing, image after morphological processing + original image
ibx = self.showimg(img, unmatched*255, dilated*255, padded, ny=2, nx=2, size=(img.shape[1],img.shape[0]), scale=2, show_img=show_img)
iimg += 1
if save_method == 'video':
outv.write(ibx)
if save_method == 'image':
res_pos = './'+save_name+'.png'
cv2.imwrite(res_pos, ibx)
if save_method == 'video':
outv.release()
if __name__ == "__main__":
# The actual runtime changes the path name of the folder
# If you want to show the middle image, change the Boolean value for show_img
imgdir = r'D:/files/Video_analysis/homework1/WavingTrees'
show_img = False
imgnamelist = filelist(imgdir, 'bmp')
trainlist = imgnamelist[:200]
testlist = imgnamelist[200:286]
img1 = GMM.readimg(imgnamelist[0])
model = GMM(7, 0.01, 0.9, img1, 100, 0.005) # K = 7 learning_rate =0.01 threshold=0.9 variance=100 weight=0.005
print("Training...")
model.train_model(trainlist, show_img=show_img)
print("Testing...")
model.test_model(testlist, save_method='video', save_name='result'+str(model.K), show_img=show_img)
model.test_model([imgnamelist[248]], save_method='image', save_name='result'+str(model.K), show_img=show_img) #
print("Finish!")
参考代码
[1] https://github.com/Andrew-Tuen/GMM/blob/master/GMM.py
参考文献
[1] Zivkovic, Z. and F. van der Heijden (2004). “Recursive unsupervised learning of finite mixture models.” Pattern Analysis and Machine Intelligence, IEEE Transactions on 26(5): 651-656.
[2] Jain R,Nagel H H. On the analysis of accumulative difference pictures from image sequences of real world scenes.[J]. IEEE transactions on pattern analysis and machine intelligence,1979,1(2).
[3] Wern, C.R., Azarbayejani, A., Darrell, T ., Pentland, A.: Pfinder: Real-time tracking of human body. IEEE Trans. Pattern Anal. Mach. Intell.(1997).
[4] Stauffer C , Grimson W E L . Adaptive background mixture models for real-time tracking[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE Xplore, 2007.
[5] 孙丕波,周利江.动态目标检测技术在智能监控中的应用研究[J].制造业自动化,2011,33(05):56-57+115.
[6] T oyama, K., Krumm, J., Brumitt, B., Meyers, B.: Wallflower: Principles and practice of background maintenance. In: IEEE International Conference on Computer Vision (1999).
[7] KaewTraKulPong, P. and R. Bowden (2001). An improved adaptive background mixture model for real-time tracking with shadow detection.
[8] Zivkovic, Z. and F. van der Heijden (2006). “Efficient adaptive density estimation per image pixel for the task of background subtraction.” Pattern recognition letters 27(7): 773-780.
[9] https://www.microsoft.com/enus/download/details.aspx?id=54651















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









