







正态分布
1.什么是正态分布?
正态分布:若随机变量X服从一个数学期望为μ、方差为σ^2 的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
记作X~N(μ,σ^2) ,读作X服从N(μ,σ^2)

当μ = 0,σ = 1时的正态分布是标准正态分布。

正态分布特点:越胖代表离中趋势越明显,越高代表集中趋势越明显
哪些实际情况服从正态分布如考试成绩分布、运动员生涯成绩、泊松过程
如何创建正态分布图
s = pd.DataFrame(np.random.randn(10000)+100,columns = ['value'])
# 创建随机数据
fig = plt.figure(figsize = (100,60))
ax1 = fig.add_subplot(2,1,1) # 子图1
ax1.scatter(s.index, s.values,color='blue')
plt.grid()
# 绘制数据分布图
ax2 = fig.add_subplot(2,1,2) # 子图2
s.plot(kind = 'kde', secondary_y=True,ax = ax2,color='red')
plt.grid()
# 绘制直方图
# 呈现较明显的正太性
效果:

2.正态分布有什么特点?
集中性:正态曲线的高峰位于正中央
对称性:正态分布曲线以均数为中心,左右对称,曲线两端永远不与横轴相交
均匀变动性:正态曲线由均数所在处开始,分别向左右两端均匀下降,曲线与横轴面积等于1
3.如何利用正态分布解决实际问题?
1.如何判断一组数据是否服从正态分布的方法:正态性检验
-
直方图
通过画直方图的方法来对数据分布进行初判s.hist(bins=30,alpha = 0.5,ax = ax2)#添加直方图模块

效果从图中可以看出直方图形状与曲线变化规律相同 -
KS检验
将所得数据与对应正态分布表相互对比如果结果p值大于0.05则满足正态分布
python中导入scipy包# 直接用算法做KS检验from scipy import stats df = pd.DataFrame(np.random.randn(10000)+100, columns =['value']) u = df['value'].mean() # 计算均值 std = df['value'].std() # 计算标准差 stats.kstest(df['value'], 'norm', (u, std)) # 结果返回两个值:statistic—D值,pvalue—P值 # p值大于0.05,为正态分布
结果:KstestResult(statistic=0.15901807048240979, pvalue=0.30662972583580261),满足正态分布。
2.利用正态性检验判断数据是否满足正态分布
随便编一组数据[1,2,1,3,5,1,1,34,1,24,1,12,4,5,35,753,4,34,5,73,32,5,23,5,23,4,2,52,25,2,5,6,2,52,25,2,52,52,2,1,2,34,2,4,23,4,23,4,2,34,2,34,63,6,75,8,6,9,9,8,5,67,3,25,2,2]
结果如下:
# 直方图初判
grade=[2,1,3,5,1,1,34,1,24,1,12,4,5,35,753,4,34,5,73,32,5,23,5,23,4,2,52,25,2,5,6,2,52,25,2,52,52,2,1,2,34,2,4,23,4,23,4,2,34,2,34,63,6,75,11,6,9,9,8,5,67,3,25,2,2]
s = pd.DataFrame(grade,columns = ['value'])
# 创建随机数据
fig = plt.figure(figsize = (100,60))
ax1 = fig.add_subplot(2,1,1) # 子图1
ax1.scatter(s.index, s.values,color='blue')
plt.grid()
# 绘制数据分布图
ax2 = fig.add_subplot(2,1,2) # 子图2
s.hist(bins=30,alpha = 0.5,ax = ax2)
s.plot(kind = 'kde', secondary_y=True,ax = ax2,color='red')
plt.grid()
# 绘制直方图
# 呈现较明显的正太性
# 直接用算法做KS检验
from scipy import stats
grade=[2,1,3,5,1,1,34,1,24,1,12,4,5,35,753,4,34,5,73,32,5,23,5,23,4,2,52,25,2,5,6,2,52,25,2,52,52,2,1,2,34,2,4,23,4,23,4,2,34,2,34,63,6,75,11,6,9,9,8,5,67,3,25,2,2]
df = pd.DataFrame(grade, columns =['value'])
u = df['value'].mean() # 计算均值
std = df['value'].std() # 计算标准差
stats.kstest(df['value'], 'norm', (u, std))
# .kstest方法:KS检验,参数分别是:待检验的数据,检验方法(这里设置成norm正态分布),均值与标准差
# 结果返回两个值:statistic → D值,pvalue → P值
# p值大于0.05,为正态分布

KstestResult(statistic=0.3857928635185164, pvalue=3.236212187118781e-09)
显然不满足正态分布
用一组班级学生的分数如下
[77,67,82,58,70,68,74,67,71,70,70,67,82,76,66,70,71,65,67,62,71,62,74,76,70,58,67,77,66,67,68,82,65,70,68]判断是否满足正态分布。
# 直方图初判
grade=[77,67,82,58,70,68,74,67,71,70,70,67,82,76,66,70,71,65,67,62,71,62,74,76,70,58,67,77,66,67,68,82,65,70,68]
s = pd.DataFrame(grade,columns = ['value'])
# 创建随机数据
fig = plt.figure(figsize = (100,60))
ax1 = fig.add_subplot(2,1,1) # 子图1
ax1.scatter(s.index, s.values,color='blue')
plt.grid()
# 绘制数据分布图
ax2 = fig.add_subplot(2,1,2) # 子图2
s.hist(bins=30,alpha = 0.5,ax = ax2)
s.plot(kind = 'kde', secondary_y=True,ax = ax2,color='red')
plt.grid()
# 绘制直方图
# 呈现较明显的正太性
from scipy import stats
grade=[77,67,82,58,70,68,74,67,71,70,70,67,82,76,66,70,71,65,67,62,71,62,74,76,70,58,67,77,66,67,68,82,65,70,68]
df = pd.DataFrame(grade, columns =['value'])
u = df['value'].mean() # 计算均值
std = df['value'].std() # 计算标准差
stats.kstest(df['value'], 'norm', (u, std))
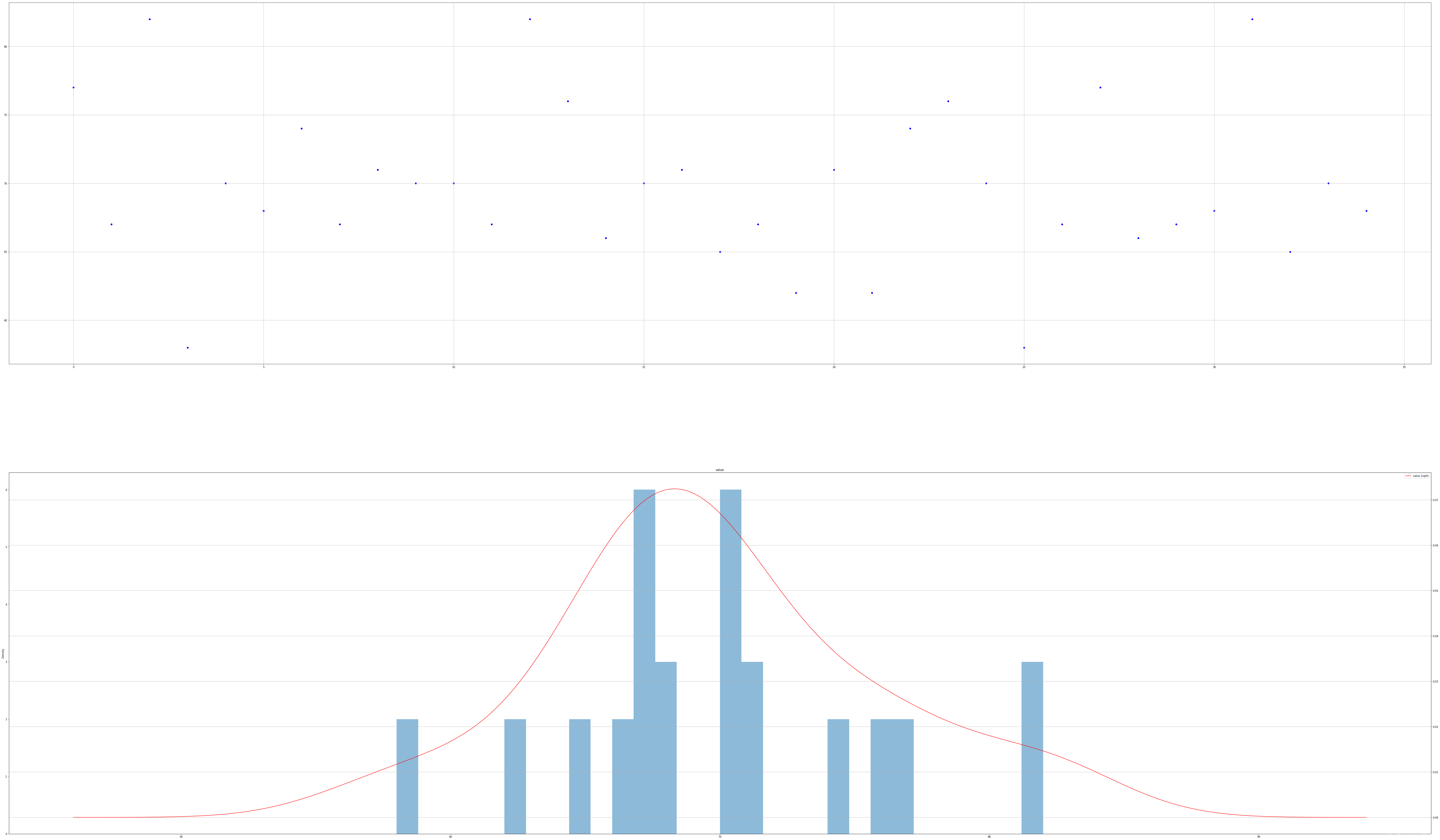

结果:KstestResult(statistic=0.1590180704824098, pvalue=0.3066297258358026)满足正态分布















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









