






基于spark的图书推荐系统 基于大数据的图书推荐 基于模型的协同过滤图书推荐系统 矩阵分解 ALS推荐(最小二乘法)
数据源:BookCrossing (BX) 数据集由 Cai-Nicolas Ziegler 在 Humankind Systems 首席技术官 Ron Hornbaker 的善意许可下从 Book-Crossing 社区进行为期 4 周的爬行(2004 年 8 月 / 9 月)收集。
它包含 278,858 名用户(匿名但具有人口统计信息),对 271,379 本书提供 1,149,780 个评分(显式/隐式)。
推荐流程:
(1)数据清洗:过滤重复的数据,比如同个书编的书籍信息,评分为0分的不合理信息,将清洗后的数据保存到mysql数据库中
(2)模型训练:从mysql数据库中读取评分数据,通过spark构建模型后填充数据进行模型训练,模型训练后可以保存模型到本地,当有新数据时再重新训练,这个过程可以用采用本地启动spark进行运算也可以将任务提交到spark集群上运算(前提时已搭建好spark集群)
(3)数据推荐:为每个用户推荐20本书,并将推荐结果保存到数据库中
(4)通过springboot搭建一个图书借阅系统展示数据,当新用户在平台借书后归还图书则会增加数据集,触发计算则会有新的推荐结果。
ID:81480692261157726
苹果大大个


基于Spark的图书推荐系统
摘要:本文将介绍基于Spark的图书推荐系统的设计与实现。该系统基于大数据分析技术,并采用基于模型的协同过滤算法,通过矩阵分解和ALS推荐算法对用户的评分数据进行处理和分析,为用户推荐适合其兴趣的图书。文章将围绕数据清洗、模型训练、数据推荐以及系统展示等方面展开详细的分析与讨论。
-
引言
图书推荐系统是利用机器学习和大数据分析技术,根据用户的兴趣和行为,为用户推荐适合其阅读的图书。传统的图书推荐系统主要基于协同过滤算法,但面对海量的图书和用户数据时,算法效率和推荐准确性会面临挑战。因此,本文采用了基于Spark的大数据分析框架,以及基于模型的协同过滤算法,通过矩阵分解和ALS推荐算法提高推荐系统的效率和准确性。 -
数据清洗
在图书推荐系统中,数据清洗是一个非常重要的步骤。本文所使用的数据集是从BookCrossing社区爬取而来的,包含了278,858名用户对271,379本书的1,149,780个评分。为了提高数据质量,我们首先对数据进行去重处理,过滤掉同一本书的多条评分信息。同时,我们也过滤掉评分为0分的不合理信息,确保数据的准确性和完整性。清洗后的数据将被保存到MySQL数据库中,以备后续的模型训练和数据推荐使用。 -
模型训练
在数据清洗完成后,我们将从MySQL数据库中读取评分数据,并利用Spark构建模型进行训练。模型训练过程中,我们采用了矩阵分解和ALS推荐算法,通过对评分矩阵进行分解和填充,得到用户对图书的隐式评分。这样可以更准确地反映用户的兴趣和喜好。为了提高系统的效率,我们可以将任务提交到已搭建好的Spark集群进行运算,也可以在本地启动Spark进行计算,具体选择根据实际情况而定。训练完成后,模型可以保存到本地,并在有新数据时重新训练以保持推荐的准确性。 -
数据推荐
模型训练完成后,我们可以利用训练好的模型为每个用户推荐20本图书。推荐结果将被保存到数据库中,以备后续的展示和查询。推荐算法会根据用户的历史行为和评分数据,为用户推荐对其兴趣度较高的图书。通过矩阵分解和ALS推荐算法,系统可以根据用户的个性化特征和相似用户的行为,推荐适合用户口味的图书。 -
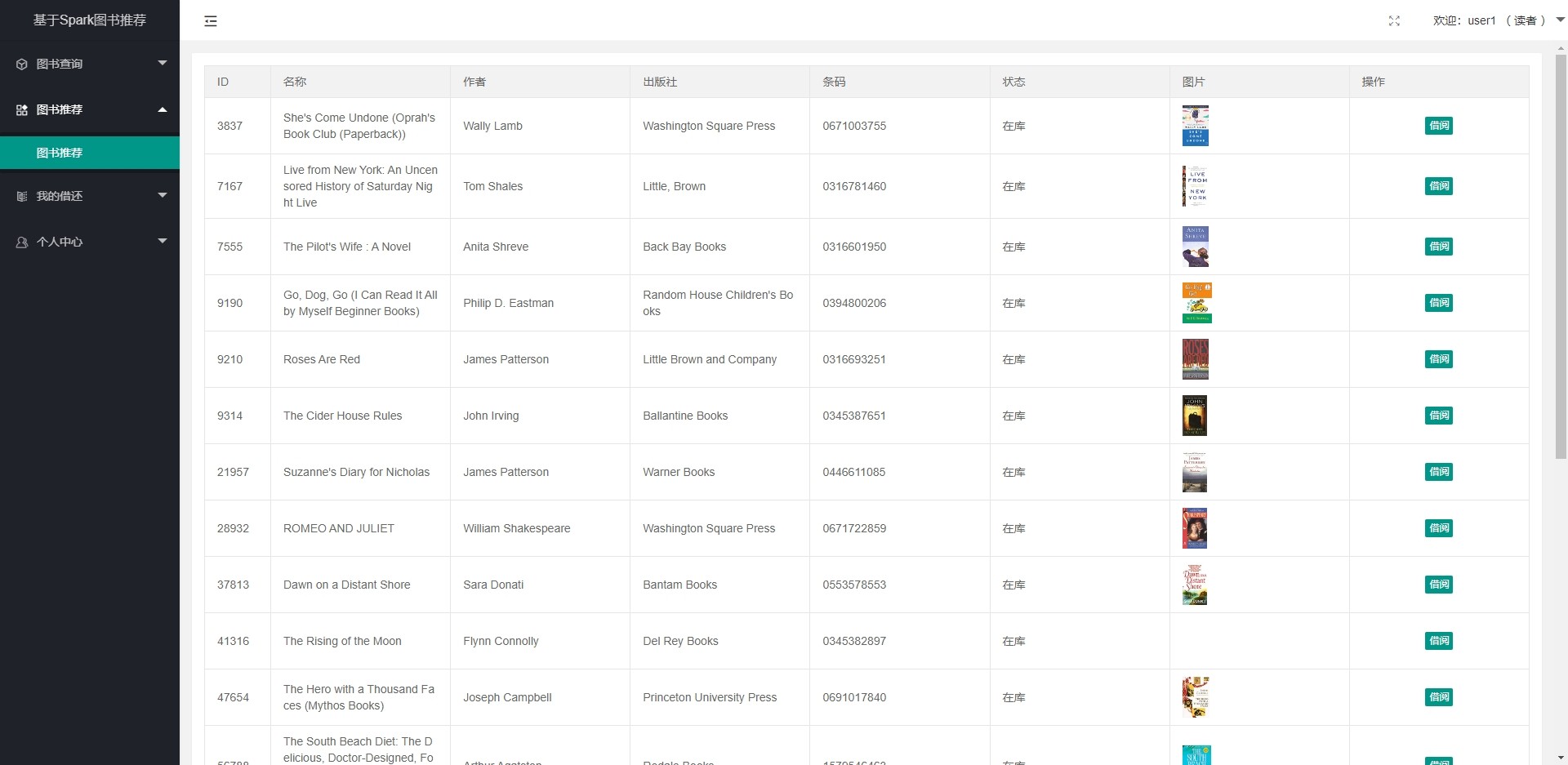
图书借阅系统展示
为了更好地让用户体验和利用图书推荐系统,我们采用Spring Boot搭建了一个图书借阅系统。当新用户在平台借阅图书并归还后,系统会增加新的数据集。这将触发推荐系统的重新计算,从而生成新的推荐结果。通过图书借阅系统的展示,用户可以方便地查询和阅读推荐的图书,提高用户的阅读体验和满意度。 -
结论
本文介绍了基于Spark的图书推荐系统的设计与实现。通过基于模型的协同过滤算法和矩阵分解技术,系统可以高效地对大规模的图书和用户数据进行分析和处理,为用户提供个性化的图书推荐。通过清洗数据、模型训练、数据推荐以及系统展示等步骤的详细分析和讨论,文章旨在为读者提供一个全面且深入的理解,以帮助读者更好地应用和掌握该推荐系统的设计和开发。
关键词:Spark、大数据分析、图书推荐系统、模型训练、数据清洗、矩阵分解、ALS推荐算法、Spring Boot。
【相关代码 程序地址】: http://nodep.cn/692261157726.html















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









