






abstruct: 作为课程作业,下面的内容是利用爬虫爬取D瓣书籍数据并用spark进行书籍推荐。实际使用了MF(Matrix factorizaion)矩阵分解模型和FM(Factor Machine因子分解机)两个模型进行测试,并给出了他们的关系和区别。
文章目录
套话
推荐系统也是信息过滤系统,即为用户过滤出个性化的信息搜索结果。从这一领域发展历史而言,可以分为 基于内容推荐以及 协同过滤两大类。基于内容的过滤规则从物体出发,比如说文档的基于内容过滤一般采用匹配关键词方式,视匹配度高的文档内容更加相似。此种种方法属于传统的信息过滤技术。协同过滤则是目前推荐系统中应用较多的技术,皮尔逊相关系数、余弦相似度算法、最近邻算法、贝叶斯算法、K-means 聚类算法等都应用到邮件过滤、电影推荐、电子商务、新闻推荐、文献资料推荐、商场推荐、旅游推荐等相关领域中。
推荐系统的核心是推荐算法。通过分析用户的历史数据信息,去预测用户对未知项目信息的喜好程度,在商品推荐系统中,产品的属性、客户的兴趣和偏好、同类客户对产品的评价等三要素共同决定了客户对产品的喜好程度,最终作为推荐系统考量的重要指标。
本文使用协同过滤的技术。协同过滤(Collabortive Filtering),通过用户和产品以及用户的偏好信息产生推荐产品的策略。基本的有两种:一是找到相同喜好的人所钟爱的产品,即基于用户的推荐。另一种是根据一个人喜欢的产品推荐类似的产品,即基于产品的推荐。利用用户以及物品的信息来预测用户的喜好,并且发觉用户可能会喜欢的类似产品或者是喜欢产品的相关产品,这就是协同过滤的核心思想。
算法简介
基于矩阵分解的思路:FunkSvd 模型
基于矩阵分解的推荐算法的核心假设是用隐语义(隐变量)来表达用户和物品,他们的乘积关系就成为了原始的元素。这种假设之所以成立,是因为我们认为实际的交互数据是由一系列的隐变量的影响下产生的(通常隐变量带有统计分布的假设,就是隐变量之间,或者隐变量和显式变量之间的关系,我们往往认为是由某种分布产生的。),这些隐变量代表了用户和物品一部分共有的特征,在物品身上表现为属性特征,在用户身上表现为偏好特征,只不过这些因子并不具有实际意义,也不一定具有非常好的可解释性、每一个维度也没有确定的标签名字,所以才会叫做“隐变量”。而矩阵分解后得到的两个包含隐变量的小矩阵,一个代表用户的隐含特征,一个代表物品的隐含特征,矩阵的元素值代表着相应用户或物品对各项隐因子的符合程度,有正面的也有负面的。
这种分解的思路我们就能立刻想到SVD,也就是奇异值分解。这样得到的三个矩阵就是物品与物品、用户与用户、用户与物品之间的隐联系。隐语义模型最经典的实现是 FunkSvd,他 是在传统 SVD 面临计算效率问题时提出来的,既然将一个矩阵做 SVD 分解成 3 个矩阵很耗时,同时还面临稀疏的问题,FunkSVD 选择只分解成两个矩阵:
R
a
t
e
=
U
s
e
r
f
a
c
t
o
r
m
a
t
r
i
x
I
t
e
m
f
a
c
t
o
r
m
a
t
r
i
x
R_{ate} = U_{serfactormatrix}I_{temfactormatrix}
Rate=UserfactormatrixItemfactormatrix
即用户 i 对 j 的评分被认为是这样得到的:用户因子矩阵 U 的第 i 行(代表第 i 个用户)点乘物体因子矩
阵 I 的第 j 列(代表第 j 个物体)。为了统一行列起见,写作
R
=
U
T
I
R = U^TI
R=UTI
损失函数
因此,一个迅速的思路是对损失函数
L
=
∑
D
i
j
(
R
i
j
−
U
i
T
I
j
)
\mathbb{L} = \sum D_{ij}(R_{ij} - U_i^T I_j)
L=∑Dij(Rij−UiTIj)优化。
其中
D
i
j
=
1
D_{ij} = 1
Dij=1,如果
R
i
j
R_{ij}
Rij有评分,否则是0。
现在我们选用所谓RMSE作为最后的评定标准,即
L
=
∑
i
m
∑
j
n
D
i
j
(
R
i
j
−
U
i
T
I
j
)
2
m
∗
n
\mathbb{L} = \sqrt{\frac{\sum_i^m\sum_j^n D_{ij}(R_{ij} - U_i^T I_j)^2}{m*n}}
L=m∗n∑im∑jnDij(Rij−UiTIj)2进行评估,也等价于优化
L
=
∑
i
m
∑
j
n
D
i
j
(
R
i
j
−
U
i
T
I
j
)
2
\mathbb{L} = \sum_i^m\sum_j^n D_{ij} (R_{ij} - U_i^T I_j)^2
L=i∑mj∑nDij(Rij−UiTIj)2
这种选择是基于一下原因做出的。只要假定用户对项目的真实评分和预测评分之间的差服从高斯分布,
即
p
(
R
i
j
−
U
i
T
I
j
∣
δ
)
∼
N
(
0
,
δ
2
)
p(R_{ij} - U_i^T I_j|\delta) \sim \mathbf{N}(0,\delta^2)
p(Rij−UiTIj∣δ)∼N(0,δ2)等价于
p
(
R
i
j
∣
U
,
I
,
δ
)
∼
N
(
U
i
T
I
j
,
δ
2
)
p(R_{ij}|U,I,\delta)\sim \mathbf{N}(U_i^T I_j,\delta^2)
p(Rij∣U,I,δ)∼N(UiTIj,δ2)
而似然函数
p
(
R
∣
U
,
I
,
δ
)
=
∏
i
m
∏
j
n
(
D
i
j
N
(
R
i
j
∣
U
i
T
I
j
,
δ
2
)
)
p(R|U,I,\delta) = \prod_i^m\prod_j^n(D_{ij}\mathbf{N}(R_{ij}| U_i^T I_j,\delta^2))
p(R∣U,I,δ)=i∏mj∏n(DijN(Rij∣UiTIj,δ2))最大化等价于最大化
l
n
p
(
R
∣
U
,
I
,
δ
)
=
−
1
2
δ
2
∑
i
m
∑
j
n
D
i
j
(
R
i
j
−
U
i
T
I
j
)
2
−
1
2
(
∑
i
∑
j
D
i
j
(
l
n
δ
2
+
l
n
2
π
)
)
ln p(R|U,I,\delta) = -\frac{1}{2\delta^2}\sum_i^m\sum_j^n D_{ij}(R_{ij} - U_i^T I_j)^2 - \frac{1}{2}(\sum_i \sum_j D_{ij}(ln\delta^2 + ln 2\pi))
lnp(R∣U,I,δ)=−2δ21i∑mj∑nDij(Rij−UiTIj)2−21(i∑j∑Dij(lnδ2+ln2π))
最大化等价于最小化
L
=
∑
i
m
∑
j
n
D
i
j
(
R
i
j
−
U
i
T
I
j
)
2
\mathbb{L} = \sum_i^m\sum_j^n D_{ij}(R_{ij} - U_i^T I_j)^2
L=i∑mj∑nDij(Rij−UiTIj)2
并加入正则项,就得到了我们最常见的损失函数:
L
=
∑
i
m
∑
j
n
D
i
j
(
R
i
j
−
U
i
T
I
j
)
2
+
λ
(
∑
∥
U
i
∥
2
2
+
∑
∥
I
j
∥
2
2
)
\mathbb{L} = \sum_i^m\sum_j^n D_{ij}(R_{ij} - U_i^T I_j)^2 + \lambda(\sum \Vert U_i\Vert_2^2+\sum \Vert I_j\Vert_2^2)
L=i∑mj∑nDij(Rij−UiTIj)2+λ(∑∥Ui∥22+∑∥Ij∥22)
优化
优化采用了交叉最小二乘法。在上面的损失函数中分别求偏导有
∂
L
∂
U
i
=
−
2
(
∑
j
D
i
j
I
j
(
R
i
j
−
U
i
T
I
j
)
)
+
2
λ
U
i
\frac{\partial L}{\partial U_i} = -2(\sum_j D_{ij} I_j (R_{ij} - U_i^TI_j)) + 2 \lambda U_i
∂Ui∂L=−2(j∑DijIj(Rij−UiTIj))+2λUi
∂
L
∂
I
j
=
−
2
(
∑
i
D
i
j
U
i
(
R
i
j
−
U
i
T
I
j
)
)
+
2
λ
I
j
\frac{\partial L}{\partial I_j} = -2(\sum_i D_{ij} U_i (R_{ij} - U_i^TI_j)) + 2 \lambda I_j
∂Ij∂L=−2(i∑DijUi(Rij−UiTIj))+2λIj
令右边为0分别有
U
i
=
∑
D
i
j
I
j
R
i
j
λ
+
∑
I
j
I
j
T
U_i = \frac{ \sum D_{ij} I_j R_{ij}}{\lambda+\sum I_jI_j^T}
Ui=λ+∑IjIjT∑DijIjRij
I
j
=
∑
D
i
j
U
i
R
i
j
λ
+
∑
U
i
U
i
T
I_j = \frac{ \sum D_{ij} U_i R_{ij}}{\lambda+\sum U_iU_i^T}
Ij=λ+∑UiUiT∑DijUiRij
选择
λ
\lambda
λ作为超参数,并在迭代一个超参数次停止。也可以使用GD或者SGD,因为数据量比较大
基于回归的思路:FM 模型
现在工业界常见的模型是FM模型,MF(Matrix factorizaion),也就是上文提到的矩阵分解,可以看做是FM模型的一个特例。
该模型在2010年被提出,并在最近得到了广泛应用。
FM被视作线性回归的一种扩展。线性回归要求特征由人手动构造,并且没有进行特征的组合。与此对比,为了引入特征组合,对每一维特征 x ⋅ , i x_{·,i} x⋅,i,其对应的一个隐向量 v i v_i vi,定义 w i j = ⟨ v i , v j ⟩ w_{ij} =\langle v_i,v_j\rangle wij=⟨vi,vj⟩.FM的公式为:对于某个特征x,估计得到y是 y ^ ( x ) = w 0 + ∑ i w i x i + ∑ i ∑ j ≥ i w i j x i x j \hat{y}(x) = w_0+ \sum_i w_ix_i+\sum_i\sum_{j\ge i}w_{ij} x_ix_j y^(x)=w0+i∑wixi+i∑j≥i∑wijxixj这一定义的合理性在于,实对称矩阵 ( w i j ) (w_{ij}) (wij)可以被分解为 V T V V^TV VTV(楚列斯基分解)(上面的公式中也可以加入正则化项以限制参数大小,Spark中的实现据文档应该是没有)。
即只要特征的两个维度
x
i
,
x
j
x_i,x_j
xi,xj同时出现过就能够学习到它的参数v。经过下面的优化,计算被简化到线性的复杂度。
对于 FM 而言,我们可以加任意多的特征,比如 user 的历史购买平均值,item 的历史购买平均值等。

MF与FM的关系
MF被视为是FM的一个特例,这是因为在FM中,将特征定义为User-id 和 Item-id 的 onehot 矩阵之连接,即如果第i个人推荐了第j个商品的话,定义特征是
x
i
&
j
=
[
0
,
.
.
.
,
1
,
0
,
.
.
.
,
0
,
1
,
0...
,
0
]
x_{i\&j} = [0,...,1,0,...,0,1,0...,0]
xi&j=[0,...,1,0,...,0,1,0...,0],其中第i个元素和第m+j个元素是1。因此有|U|+|V| = m+n个隐向量v,但是能学习的隐向量只有当
x
i
x
j
≠
0
x_ix_j\neq 0
xixj=0,也就是|数据个数|个。得到的FM:
y
^
(
U
=
u
,
I
=
i
)
=
w
0
+
w
u
+
w
i
+
m
+
⟨
v
u
,
v
m
+
i
⟩
\hat{y}(U = u,I = i) = w_0+w_u+w_{i+m}+\langle v_u,v_{m+i}\rangle
y^(U=u,I=i)=w0+wu+wi+m+⟨vu,vm+i⟩
对于该条特征,y的实际值是评分.而写成矩阵形式:
Y
^
=
[
v
u
]
T
[
v
m
+
i
]
+
w
0
+
[
w
u
]
+
[
w
i
+
m
]
\hat{Y} = [v_u]^T[v_{m+i}]+w_0+[w_u]+[w_{i+m}]
Y^=[vu]T[vm+i]+w0+[wu]+[wi+m]
即加入偏置
w
u
,
w
i
+
m
w_u,w_{i+m}
wu,wi+m的Y = UV。

优化
计算时用GD或者SGD进行优化,如果按
∑
(
y
−
y
^
)
\sum(y-\hat{y})
∑(y−y^)作为LOSS:
∂
y
^
∂
θ
=
{
1
,
θ
=
w
0
x
i
,
θ
=
w
i
x
i
∑
j
v
j
,
f
x
j
−
v
j
,
f
x
i
2
,
θ
=
v
j
,
f
\frac{\partial \hat{y}}{\partial \theta}=\left\{ \begin{aligned} &1,&\theta = w_0\\ &x_i,&\theta = w_i\\ &x_i\sum_j v_{j,f}x_j-v_{j,f}x_i^2, &\theta = v_{j,f}\\ \end{aligned} \right.
∂θ∂y^=⎩
⎨
⎧1,xi,xij∑vj,fxj−vj,fxi2,θ=w0θ=wiθ=vj,f
爬虫
代码:主要用lxml库。自从知道lxml后再也不用正则了~ 爬虫需要注意的地方是DBan不允许爬很多,可能需要一些特殊方法。另外很多信息录入有误,格式也不统一(比如【】、[]之类),我们尽量修改,实在不行就unknown。
下文中,??? ???请替换为具体某站使用
爬取页面
# -*- coding: utf-8 -*-
from logging import exception
from tokenize import group
import requests
import re
from lxml import etree
def read():
list = []
# 读cate.txt中的作为需要搜索的类别
# 格式:
# 小说
# 历史
# 文学
with open("cate.txt",'r',encoding="utf-8") as c:
while(1):
line = c.readline()
if(line==""): break
line = line.strip("\n")
list.append(line)
base = "h t t p s:/ / b o o k.??? ???. c o m /tag/"
file = open("data.txt","a",encoding="UTF-8")
for j in range(len(list)):
# b:起始,p结束
b = 1
p = 100
cats = list[j]
url = base+cats
for i in range(b,p):
context = getcontext(url+"?start="+str(i*20-20)+"&type=T")
_ = etree.HTML(context)
data_list = _.xpath("//li[contains(@class,'subject-item')]")
if(data_list == []): break;
for data in data_list:
#print("-" * 100)
try:
book_link = data.xpath(".//h2/a/@href")[0].strip()
book_name = data.xpath(".//h2/a/text()")[0].strip()
book_info = data.xpath(".//div[@class='pub']/text()")[0].strip()
score,score_numbers = readScore(data)
file.write( book_name+"\t"+
modifyInfo(book_info)+"\t"+
str(score)+"\t" +
str(score_numbers)+"\t" +
book_link+"\t"+cats+"\n")
except:
print(i,book_name,book_info)
raise
return
# 在这里,防止@reply
# 读取评分
def readScore(data):
score = data.xpath(".//div[@class='star clearfix']/span[1]/text()")
if(score != []):
# 那就一定是少于10
if("少于" in score[0]):
score_numbers = 5
score = -1
elif ("无" in score[0]):
score_numbers = 0
score = 0
return score,score_numbers
else :
score = data.xpath(".//div[@class='star clearfix']/span[2]/text()")
if(score != []):
score = score[0].strip()
else :
score = -1
score_numbers = data.xpath(".//div[@class='star clearfix']/span[3]/text()")[0]
score_numbers = re.findall("\d+",score_numbers)[0]
return score,score_numbers
def getcontext(url):
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
pages =requests.get(url,headers = headers)
print("Now,checking:"+url)
pages.encoding = "utf-8"
context = pages.text
return context
# 修改info到合适的形式: 如果是 zh (en) .. ,删除en
def filtername(name:str)->str:
_ = re.match("([\u0000-\uffff ]+)[绘编著主翻译注者]{1,2}",name)
if(_ is not None):
name = _.group(1)
_ = re.match("([\u4e00-\u9fff •·]+)([ ]?[((]?[^\u4e00-\u9fff]*)$",name)
if(_ is not None):return _.group(1)
return name
def modifyInfo(info:str):
try:
_ = info.replace("、"," / ").strip().split(" / ")
nations = []
names = []
time = ""
flag = 0
if( _ ==[""]):return "unknown|unknown"+"\t"+"unknown"+"\t"
elif(len(_)>3 and _[-2][0].isdigit()):
flag = 1
_[-3] = _[-2]
_ = _[:-2]
for entry in _:
if(entry!="" and entry!=" "):
if(entry[0].isdigit()):
time = entry
break;
if(entry[0] in "[{【([("):
if("无" not in entry):
reg = "[\[(([【{]([\u0000-\uffff_a-zA-Z0-9·]+)[\]}]))】]+[ ]?([\u0000-\uffff _a-zA-Z0-9·]+)"
match = re.match(reg,entry)
name = filtername(match.group(2))
if(name not in names):
nations.append(match.group(1))
names.append(name)
else :
reg = "([\u0000-\uffff_a-zA-Z0-9· ]+)"
match = re.match(reg,entry)
name = filtername(match.group(1))
if(name not in names):
names.append(name)
nations.append("中")
info = ""
for k,v in zip(nations,names):
info += k+"|"+v+"\t"
if(flag == 0):
time ="unknown"
info += time
#print(info)
return info
except:
return ""
if __name__ == "__main__":
#print(n)
read()
#n = filtername("中|拱玉书 译")
#print(n)
爬虫1的结果
数据用\t分割,分别是名-作者-译者-时间-评分-评分人数-链接-分类。爬取了 77260 本。
[这里是一张具体的截图]
这些数据可以用来构造一些手工特征,FM算法等等可以用到。就MF算法的使用来看并不需要这么详细的数据(只要一个评分矩阵就可以)。
比如说“经典著作”“拉美文学”等等tag。
爬取页面 新书速递
# -*- coding: utf-8 -*-
import requests
import re
from lxml import etree
def read():
list = ['全部','文学','小说','历史文化','社会纪实','科学新知']
base = "ht t p s:/ / b o o k.??? ???. c o m/latest?subcat="
file = open("newbook.txt","w+",encoding="UTF-8")
for cats in list:
url = base+cats
for i in range(1,2):
context = getcontext(url+"&p="+str(i))
_ = etree.HTML(context)
data_list = _.xpath("//li[contains(@class,'media clearfix')]")
for data in data_list:
#print("-" * 100)
book_link = data.xpath(".//h2/a/@href")[0].strip()
book_name = data.xpath(".//h2/a/text()")[0].strip()
book_info = data.xpath(".//p[@class='subject-abstract color-gray']/text()")[0].strip()
score = data.xpath(".//p[@class='clearfix w250']/span[2]/text()")
if(score == []): score = -1
else: score = score[0].strip()
score_numbers = data.xpath(".//p[@class='clearfix w250']/span[3]/text()")[0]
score_numbers = re.findall("\d+",score_numbers)[0]
file.write( book_name+"\t"+
modifyInfo(book_info)+"\t"+
str(score)+"\t" +
score_numbers+"\t" +
book_link+"\n")
return
# 在这里,防止@reply
def getcontext(url):
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
pages =requests.get(url,headers = headers)
print("Now,checking:"+url)
pages.encoding = "utf-8"
context = pages.text
return context
# 修改info到合适的形式
def filtername(name:str)->str:
_ = re.match("([\u4e00-\u9fff •·]+)[ ]?[((]?[^\u4e00-\u9fff]+",name)
if(_ is not None):return _.group(1)
return name
def modifyInfo(info):
_ = info.split(" / ")[:-2]
nations = []
names = []
time = ""
for entry in _:
if(entry[0].isdigit()):
time = entry
break;
if(entry[0] in "[{【([("):
reg = "[\[(([【{]([\u0000-\uffff_a-zA-Z0-9·]+)[\]}]))】]+[ ]?([\u0000-\uffff _a-zA-Z0-9·]+)"
match = re.match(reg,entry)
name = filtername(match.group(2))
if(name not in names):
nations.append(match.group(1))
names.append(name)
else :
reg = "([\u0000-\uffff_a-zA-Z0-9· ]+)"
match = re.match(reg,entry)
name = filtername(match.group(1))
if(name not in names):
names.append(name)
if(len(nations)>=1):
nations.append(nations[-1])
else:
nations.append("unknown")
info = ""
for k,v in zip(nations,names):
info += k+"|"+v+"\t"
info += time
return info
if __name__ == "__main__":
# 得到的格式如下
a = "摄影:张靖 / / 东方出版社 / 2018-01-01 / 99.8 "
read()
爬虫2的结果
这个数据比较少,因为他是新书。评分的人很少就难以开展协同过滤,只能使用基于内容的推荐等等。推荐的时候可以直接tag里面随机一些推荐。另外个人观点来看,新书这种东西就是用来随机的(笑)。
爬取具体用户评分
协同过滤还需要加入用户的评分。首先,我们需要去重。其次,选一些书作为总的推荐池子来爬取(全部也行,如果你有希望的话)。
去重
def makePoints():
# 选择评分人>1000的书来做实验
p = open("data.txt","w+",encoding="utf-8")
with open("data_filtered.txt","r",encoding="utf-8") as f:
count = 0
while(1):
count+=1
line = f.readline()
if(line == ""): break;
linedata = line.split("\t")
number = linedata[-3]
if(int(number)>1000):
p.write(line)
def filtersame():
# 如果书名和出版日期都一样就是一本书
p = open("data_filtered.txt","r",encoding="utf-8")
f = open("newdata.txt","w+",encoding="utf-8")
booklist = []
while(1):
line = p.readline()
if(line == ""): break;
linedata = line.split("\t")
if(linedata[0]+linedata[-5] not in booklist):
booklist.append(linedata[0]+linedata[-5])
f.write(line)
filtersame()
爬取评论
#coding=utf-8
import requests
from lxml import etree
def get():
rank = {"力荐":"5","推荐":"4","还行":"3","较差":"2","很差":"1"}
dic = {}
list = []
# newdata.txt里存着链接书名
with open("newdata.txt","r",encoding= "utf-8") as f:
count = 0
while(1):
count += 1
line = f.readline()
if(line == ""): break;
l = line.split("\t")[-2]
list.append(l)
dic[count] = l.split("/")[-2]
people_id = 0
dic_pname_id ={}
allName = []
book_id = 0
p = open("user.txt","a",encoding="utf-8")
try:
for link in list:
book_id+=1
for i in range(0,30):
url = "?start=%d&limit=20&status=P&sort=new_score"%(i*20)
context = getcontext(link+"comments"+url)
_ = etree.HTML(context)
data_list = _.xpath("//li[contains(@class,'comment-item')]")
if(data_list == []): break;
for data in data_list:
rate = data.xpath(".//div[@class='comment']/h3/span[2]/span[1]/@title")
if rate != []:
vote = data.xpath(".//div[@class='comment']/h3/span[1]/span[1]/text()")[0].strip()
rate = rate[0].strip()
name = data.xpath(".//div/a/@href")[0].strip().split("/")[-2]
time = data.xpath(".//div[@class='comment']/h3/span[2]/a[@class='comment-time']/text()")[0].strip()
this_id = 0
if(name not in allName):
this_id = people_id
dic_pname_id[name] = people_id
allName.append(name)
people_id+=1 #下一个人的id
else:
this_id = dic_pname_id.get(name)
p.write(str(this_id)+"\t"+
dic.get(book_id)+"\t"
+ rank.get(rate) + "\t"+ vote+"\t"+time+"\n")
except:
with open("10.txt","w+") as new_file:
for k,v in dic_pname_id.item():
new_file.write(k+"\t"+str(v)+"\n")
p.flush()
raise
p.close()
def getcontext(url):
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
pages =requests.get(url,headers = headers)
print("Now,checking:"+url)
pages.encoding = "utf-8"
context = pages.text
return context
get()
爬虫3结果
用户 id 书籍 id 评分 点赞人数 时间
书籍id就是链接里的那个
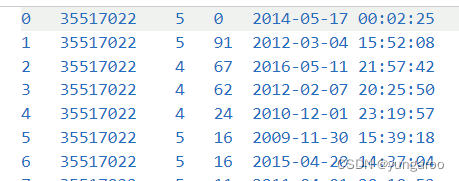
数据清洗和处理
需要做两件事:
- 图书数据清理(我们已经做过了)
由于正则表达式的限制,在姓名一栏还有许多问题。例如跟着出版社信息、出现”… 译” 字样、国籍时有时无、【[](混用), 后两者是D瓣没有校验的缘故,这导致正则表达式再复杂也不能进行一次全部过滤。为了修正姓名,采用如下策略:- 过滤掉错误信息,如把出版社加入到作者
- 将书名相同的多本书标识为同一实体,并按照投票方法得到这本书的作者、出版日期信息。投票方
法指认为对同一实体(书名 + 作者 1)的某个属性,更多数据中记录的一个值是正确的。这有利于我们选
出更经典的版本(尤其是译者不同时)。
使用 python 再过滤一次并只要评价人数 >1000 的,并去重复实体(这已经在上一步中完成),得到了 8283 本。然后,再进行数据获取的 [评论爬取] 部分。
- 评论数据清理 对只有一次评分的读者进行清理。他们对于模型具有不良影响,这点主要体现在这些人的
产生很有可能是因为对一本书爬取了太多数据,或者某本书有大量的只评价一次的“水军”。这些数据的
价值是不大的,并导致模型更愿意推荐这本书。
清理之后,剩下 285842 条评论。还剩下 58661 个用户(他们评论了两条及以上)。
制作评分矩阵
def makeFactor():
bid_n = {}
user = []
book = []
uid_n = {}
num = 0
with open("user.txt","r") as f:
while(1):
line= f.readline()
if(line == ""): break;
line = line.strip().split("\t")[0:3]
if(bid_n.get(line[1]) is None):
bid_n[line[1]] = num
num+=1
user.append(line[0])
book.append(bid_n.get(line[1]))
d = {}
count = 0
for key in user:
d[key] = d.get(key, 0) + 1
for k,v in d.items():
if(v>1):
uid_n[k] = count
count+=1;
print(len(bid_n.keys()))
with open("user.txt","r") as f:
# user_i book_j rate
p = open("rate.txt","w+")
while(1):
line= f.readline()
if(line == ""): break;
lined = line.strip().split("\t")[0:3]
lined[2] = str(float(lined[2])/5.0)
if(d.get(lined[0])>1):
p.write(str(uid_n.get(lined[0]))+"\t"+str(bid_n.get(lined[1]))+"\t"+lined[2]+"\n")
with open("book_dict.txt","w+") as f:
# book oldname \t newname
for k,v in bid_n.items():
f.write(k+"\t"+str(v)+"\n")
with open("user_dict.txt","w+") as f:
# user oldname \t newname
for k,v in uid_n.items():
f.write(k+"\t"+str(v)+"\n")
print(count)
makeFactor()
使用spark
前:安装等等
apache的文档一直很优秀,直接看观网下载和使用spark和hadoop。spark使用scala语言编写并支持scala脚本,当然我们还是用python的库pyspark。spark的具体使用请参考一般的教程,非常简单~
需要配置一些环境。打开spark并
import os,sys
os.environ['SPARK_HOME'] = "D:/spark-3.0.3-bin-hadoop3.2/" # 安装目录
sys.path.append("C:/Program Files/Java/jdk1.8.0_333") # jdk
sys.path.append("D:/spark-3.0.3-bin-hadoop3.2/bin") # 库
sys.path.append("D:/spark-3.0.3-bin-hadoop3.2/python")
sys.path.append("D:/spark-3.0.3-bin-hadoop3.2/python/lib")
sys.path.append("D:/spark-3.0.3-bin-hadoop3.2/python/lib/py4j-0.10.9-src")
from pyspark import SparkContext
# 测试:单词计数
sc = SparkContext("local","test")
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD -> %i" % counts)
这个简单的测试跑出来就说明都正常运行。而且这个实验比较简单,代码也直接用库就好了。spark专门提供了Rating数据结构,格式是(user, item, rate),正好对应我们的格式。
sqark 的机器学习库 MLlib提供了ALS(交替最小二乘)库可以进行 MF(Funksvd) 的训练。同样的,MLlib 也提供了 FM 的实现。实际上 MLlib 还包括 GBDT 等等,出于数据的形式是评分不是点击率的考虑选择了前文所述的两个模型。另一方面前文的两个模型训练是比较简单,并且每次迭代都能在一轮 MapReduce 中实现,方便模型的实践与拓展。下文中将直接使用 ASL 库进行训练。
训练:Funksvd(MF)
user_data = sc.textFile("rate.txt").map(lambda x: x.split("\t")[0:3])
from pyspark.mllib.recommendation import Rating
data = user_data.map(lambda x: (Rating(int(x[0]),int(x[1]),int(x[2]) )) )
(trainingData, testData) = data.randomSplit([0.9, 0.1])
# 训练集上的损失
from pyspark.mllib.recommendation import ALS
from pyspark.mllib.recommendation import MatrixFactorizationModel
# funksvd
model = ALS.train(ratings=trainingData, rank=10, iterations=10, lambda_ =0.02,)
predicttest = model.predictAll(testData.map(lambda x:(x[0],x[1]))).map(lambda x:((x[0],x[1]),x[2]))
predict1_result = predicttest.join(testData.map(lambda x:((x[0],x[1]),x[2]))).map(lambda x:((x[1][1]-x[1][0])*(x[1][1]-x[1][0])))
# 计算RMSE
import math
print(math.sqrt(predict1_result.reduce(lambda x,y :x+y)/predict1_result.count()))
predicttrain = model.predictAll(trainingData.map(lambda x:(x[0],x[1]))).map(lambda x:((x[0],x[1]),x[2]))
predict2_result = predicttrain.join(trainingData.map(lambda x:((x[0],x[1]),x[2]))).map(lambda x:((x[1][1]-x[1][0])*(x[1][1]-x[1][0])))
print(math.sqrt(predict2_result.reduce(lambda x,y:x+y)/predict2_result.count()))
爬虫写了几百行,模型却只有简单的几行(悲)。
训练:FM
我是用jupyter notebook写的,所以格式上空格很多就是新的格。由于缺少点击率等数据,而且这个实验比较简单,就直接使用 onehot 编码作为特征输入了,因此,FM 模型退化为带偏置的 MF模型,公式如前所述。
实际上,由于我们有标签、时间戳、书名、作者等信息,可以尽可能地拓展特征,即使是使用 onehot,也足够加入标签。很早之前我们把user和bookid都置1开始就是为了在这里变onehot。
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import IntegerType,StructField,StructType
from pyspark.sql import SparkSession
user_data = sc.textFile("rate.txt").map(lambda x: x.split("\t")[0:3]).map(lambda x: [int(x[0]),int(x[1]),float(x[2])])
spark = SparkSession(sc)
df = spark.createDataFrame(user_data,["uid","bid", "rate"])
from pyspark.ml.linalg import Vectors
from pyspark.ml.feature import OneHotEncoder
encoder = OneHotEncoder(inputCols=["uid", "bid"],
outputCols=["uid_out", "bid1_out"])
model = encoder.fit(df)
encoded = model.transform(df)
encoded.show()
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=["uid_out", "bid1_out"],
outputCol="features")
output = assembler.transform(encoded)
df1 = output['rate', 'features']
(trainingData,testData) = df1.randomSplit([0.9,0.1])
df1.show()
from pyspark.ml.regression import FMRegressor
fm = FMRegressor( featuresCol='features', labelCol='rate', stepSize=0.05,factorSize=10)
model = fm.fit(trainingData)
还是使用rmse衡量
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(predictionCol='prediction', labelCol='rate',metricName='rmse')
evaluator.evaluate(model.transform(trainingData))
evaluator.evaluate(model.transform(testData))
评估
MF评估
在对评分进行归一化后 (0.2,…,1),使用 Spark 进行学习,得到的实验结果如下表所示。其中超参数迭代次数、rank(两个分解的小矩阵的秩)、正则化系数 λ. 首先进行的实验是验证正则化系数和迭代次数的影响。
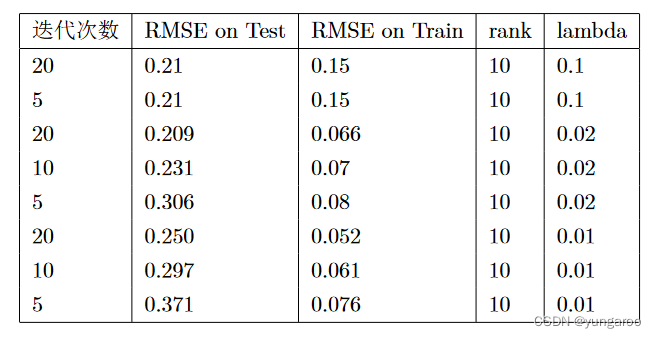
表一分析:正则化项的增大使得训练集上的得分下降,但是在测试集上得分能够达到小的正则化的水平。并且,只需要 5 轮迭代就能够完成其他正则化系数 20 轮左右的水平。从表能够看出,随着正则化系数的增大,相同轮次的训练效果变好直到 0.21 为止。下面分析设置两个小矩阵的秩对实验结果的影响。现在已经知道,对于正则项设置为 0.1,迭代次数 5 轮基本可以得到最好效果。
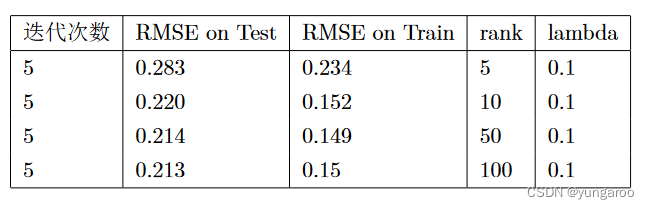
表二分析:从实验结果中不难看出,对这个数据集而言,设置的 rank>10 基本不改变在两个数据集上的
得分。
这个RMSE能达到0.2,也就是5分制1分左右的偏差。
FM评估
将特征写成 onehot 矩阵连接的形式,如前所述,这个 FM 等价于 MF。因此,实验实际是验证 bias项的意义。这个模型是比较占用内存的,因为每条记录对应一个隐变量;与之相比,MF 模型隐变量一共只有 rank*2 个。在单机上,如果设置 dim 在 100 左右,每次训练都要100M 内存。因此实验收到了较大的限制。但是从结果看,这一种特征的选取并不能带来多么好的效果!但已经可以验证 FM 的下界几乎和
MF 的上界是一致的。使用梯度下降法(实际使用了 Adam),需要设置的超参是:step(步长)、隐变量维度(rank)
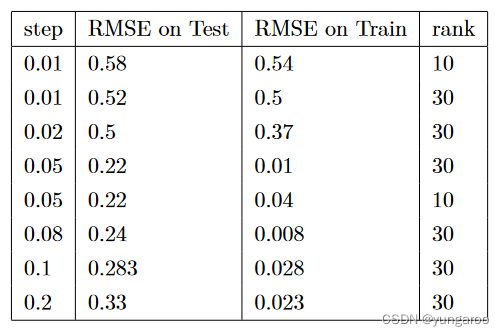
表三分析:能看出对实验结果影响比较大的因素是 Step。在同样 step 的情况下,rank=10 或 rank=30 都不会对结果造成特别大的影响。rank 增大虽然能够改善模型的输出,但是也会造成训练时间的加长和内存的占用增大。从结果看来,随着 step 增大,RMSE 先上升后下降。其中,step=0.05 是比较合适的。
似乎出现了过拟合现象。如果读者有兴趣可以自己加一些手工特征看看能不能提升一些表现~
模型推荐演示
最后,选用 Rank=10,step=0.05 的模型结果来推荐。这里由于版权考虑隐去了具体书名,读者可以自行实验。
–实际上感觉这些书随便一本我都很喜欢XD–
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









