







总言
思路汇总,慢慢学习和补充。
单链表
1、力扣题:移除链表元素
题源:力扣题源

1.1、思路一:
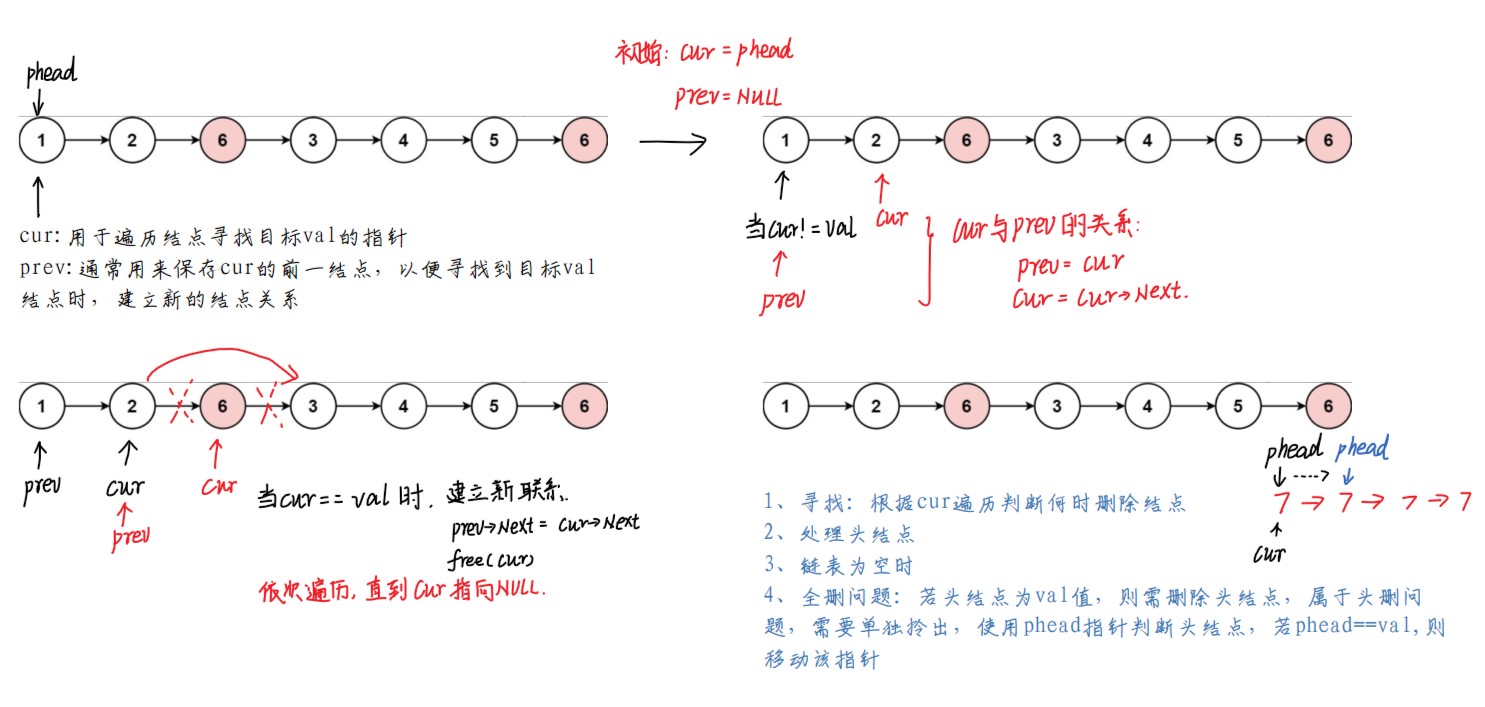
基本思路:遍历一遍链表,找到目标结点,删除目标结点并建立对链表建立新的联系。
基于此,给定一个cur指针,用于控制遍历,此时还需要一个prev指针,用于建立目标结点前后两结点间的新的指向关系。
考虑极端情况,若目标结点为头结点时,则需要变动head头指针指向关系,需要特殊考虑。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*prev=NULL;
struct ListNode*cur=head;
while(cur)
{
//判断是否需要删除时
if(cur->val==val)
{
//头删
if(cur==head)
{
head=head->next;
free(cur);
cur=head;
}
//非头删
else{
prev->next=cur->next;
free(cur);
cur=prev->next;
}
}
else{
prev=cur;
cur=cur->next;
}
}
return head;
}
思考:关于此题中函数形参 struct ListNode* head 没像“单链表的简单实现”中那样使用二级指针的原因?
此函数返回类型是struct ListNode* ,即返回新的头指针。
1.2、思路二:
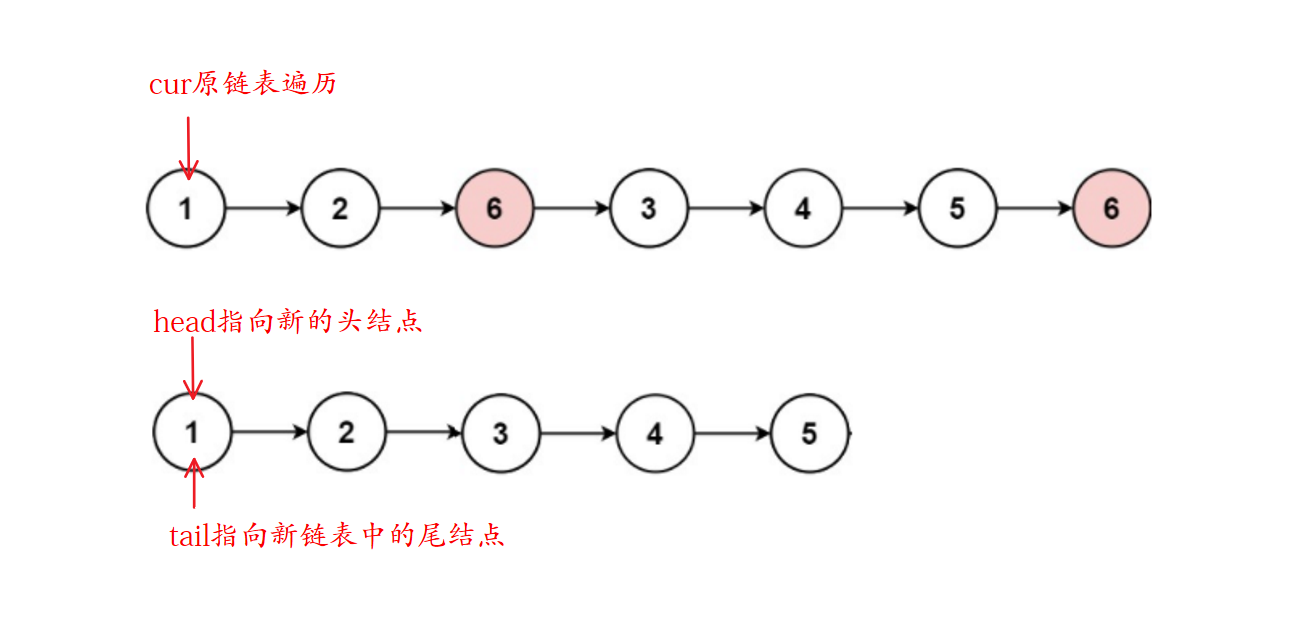
其它思路:仍旧遍历链表,但类似于处理顺序表数组结构一样,把有效结点挑出,通过尾插建立新联系,再返回该新链表的头指针即可。对于目标结点,仍旧释放。
即一种思路是原地变动链表结构,另一种思路是直接建立新链表代替旧链表。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*cur=head;
struct ListNode*tail=NULL;
head=NULL;
while(cur)
{
if(cur->val==val)//删除操作
{
struct ListNode*del=cur;
cur=cur->next;//此步骤不能省去,故cur指针的变动在两种情景下需要分别写
free(del);
}
else//复刻操作:将有效数据尾插到新链表中
{
if(tail==NULL)//首次复刻
{
head=tail=cur;
}
else//非首次复刻
{
tail->next=cur;
tail=tail->next;//复刻后变动tail指针的指向位置
}
cur=cur->next;
tail->next=NULL;//每次操作后对于新建立的链表要将tail尾部next指向位置置空
}
}
return head;
}
始终要记住变动链表本身是为了重建结点间的联系。因此在写代码时要注意这种更变指向关系的步骤是否已写,可用来走读代码时检查问题。
1.3、思路三:
对思路二的改进,加入一个哨兵位的结点。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*cur=head;
struct ListNode*tail=NULL;
//插入一个带哨兵位的头结点:该哨兵位结点不存储有效数据,只起到站长作用。
head=tail=(struct ListNode*)malloc(sizeof(struct ListNode));
tail->next=NULL;
while(cur)
{
if(cur->val==val)//删除操作
{
struct ListNode*del=cur;
cur=cur->next;//此步骤不能省去,故cur指针的变动在两种情景下需要分别写
free(del);
}
else//复刻操作:将有效数据尾插到新链表中
{
tail->next=cur;
tail=tail->next;//复刻后变动tail指针的指向位置
cur=cur->next;
tail->next=NULL;//每次操作后对于新建立的链表要将tail尾部next指向位置置空
}
}
//释放结点
struct ListNode* del=head->next;
free(head);
head=del;
return head;
}
如上,加入哨兵位的头结点后,对于有效数据的尾插将方便很多,即不需要区分tail==NULL新链表为空第一次尾插的情况。
哨兵位的头结点的一个作用是便于尾插。但需要注意对链表申请新的哨兵位,结束时若没有目前要求还需把该哨兵位释放。
2、力扣题:反转单链表
题源:力扣题源
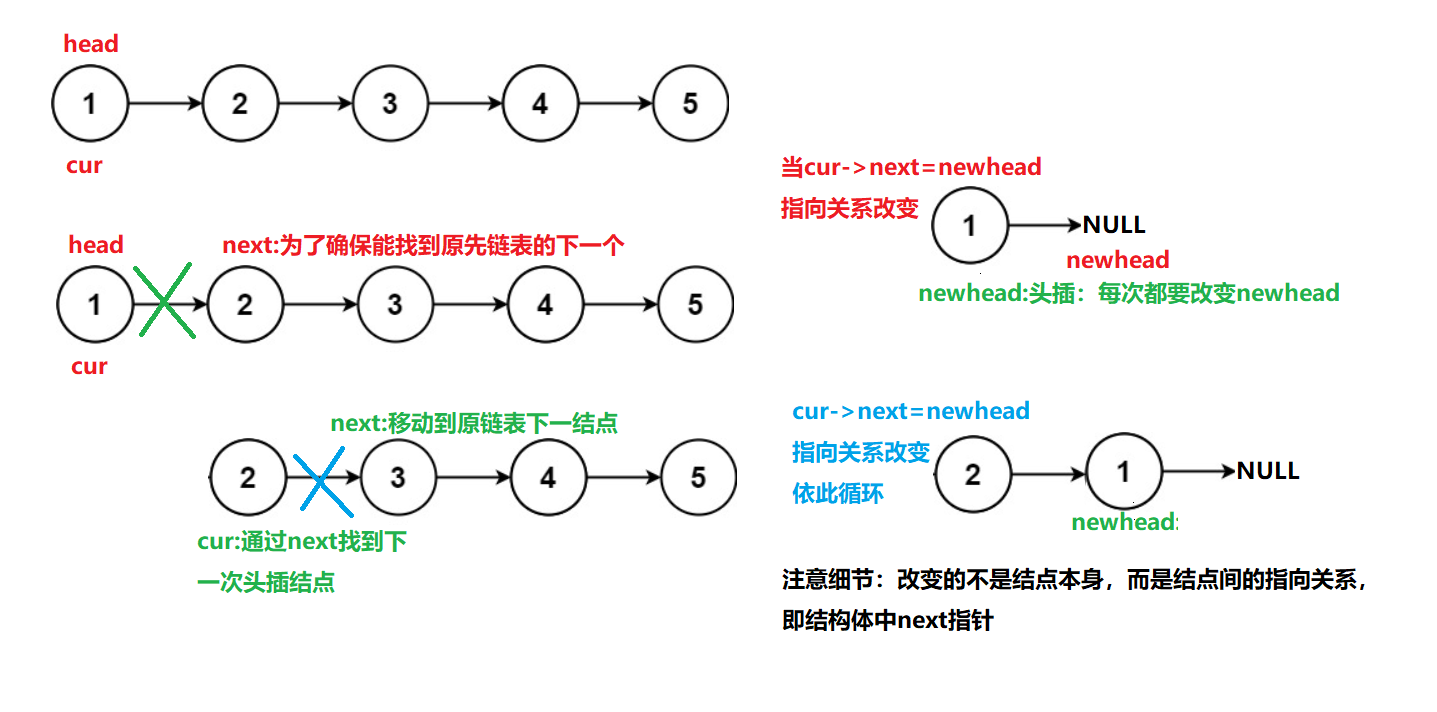
2.1、思路一:头插法
思路分析示意图:相当于头插,只不过需要注意是在原链表中插入(类比于数组原地调换)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
struct ListNode*cur=head;
struct ListNode*newhead=NULL;
while(cur)
{
//存储原链表cur后续结点
struct ListNode* next=cur->next;//next指向需要在while内明确指向关系,以杜绝链表为空时,NULL=NULL->next的情况。
//变动cur指向结点的链接关系
cur->next=newhead;
//头插变动头结点
newhead=cur;
//变动cur指向结点,完成遍历
cur=next;
}
return newhead;
}
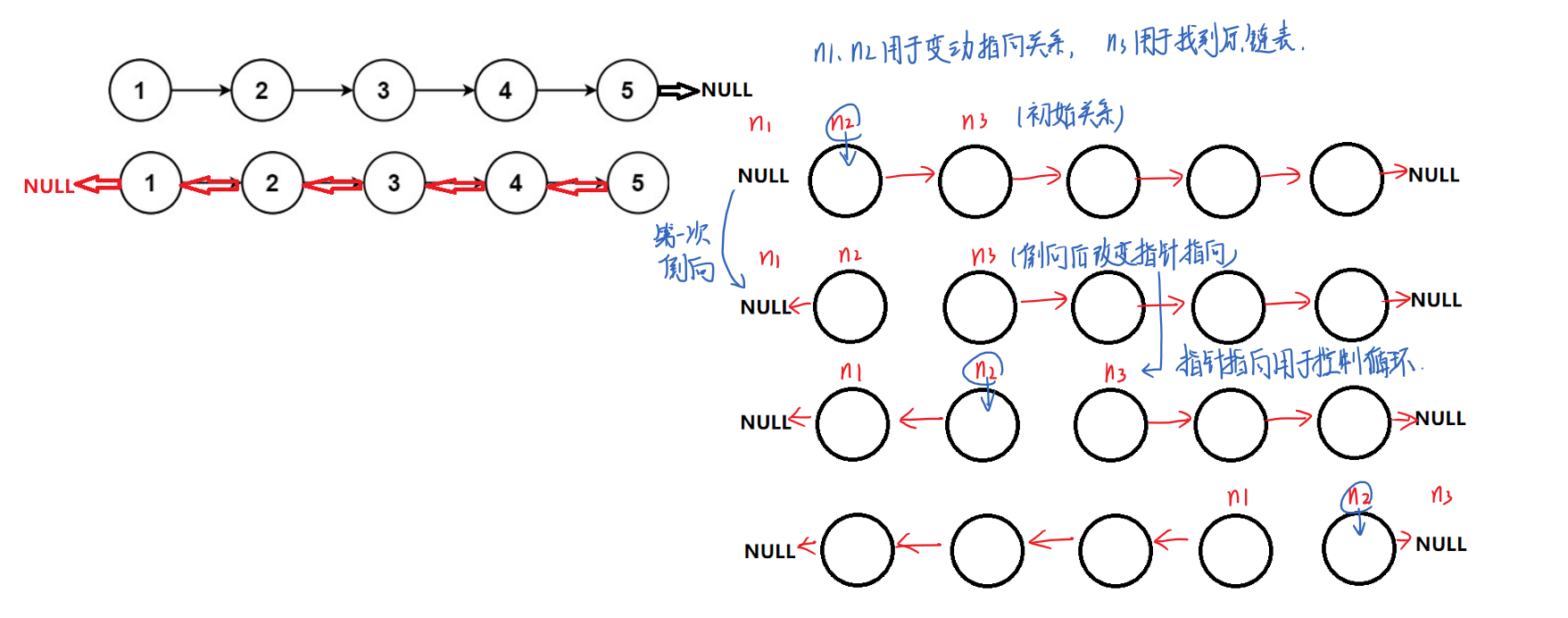
2.2、思路二:三指针控制
思路分析示意图:
代码:对于该写法,需要注意的是三个指针迭代时的顺序变化。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
//当链表为空的情况
if(head==NULL)
return NULL;
//确定初始指向关系:n1、n2用于改变原结点指向关系,n3用于找到断开后的结点
struct ListNode*n1,*n2,*n3;
n1=NULL;
n2=head;
n3=n2->next;
//链表不为空时
while(n2)//n2用于判断何时结束
{
//改变指向关系
n2->next=n1;
//改变指针迭代
n1=n2;
n2=n3;
if(n3)
n3=n3->next;
//由于n2控制循环结束,当n2指向末尾结点时,用于下一次进入循环改变末结点,
//但此时n3已经指向空指针,故此处需要对此做处理
}
return n1;//注意此处返回值,结束循环时n2已经指向空指针,n1指向尾结点
}
3、力扣题:链表的中间结点
题源:力扣题源
3.1、思路一:二次遍历法
常规思路下,一种方法是先遍历一遍链表,统计链表总结点数,除二找到中间结点,再遍历一遍链表即可得到指向中间结点的指针。
但这是需要多次遍历链表,以下为只遍历一遍链表的方法。
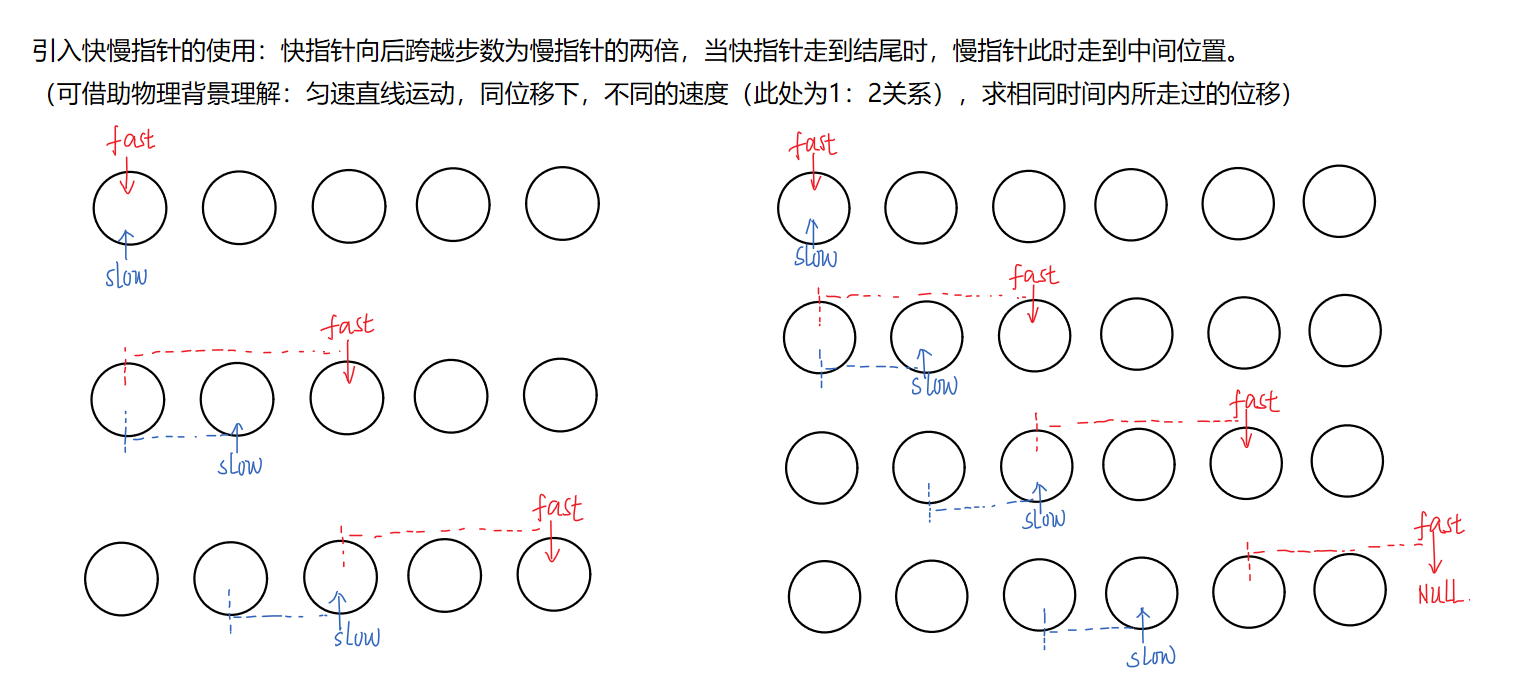
3.2、思路二:快慢指针法
思路示意图:(快慢指针法,此方法通用性高,需要学习)
代码:关于循环的判断条件需要注意。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head){
struct ListNode*fast,*slow;
fast=slow=head;
//判断结束条件:当fast指针指向末结点或指向某节点后的空指针时,循环结束,
//德摩根定律作用于布尔运算下,即得:当fast指针不为空且fast指针中next指针非空,则循环继续
while(fast&&fast->next)//此借用了逻辑运算符的短路问题处理奇偶不同条件。
{
slow=slow->next;
fast=fast->next->next;
}
return slow;
}
4、牛课题:链表中倒数第K个结点
题源:牛客题源
4.1、思路一:快慢指针法
思路示意图:本题仍旧使用快慢指针,但需要注意思考细节问题。
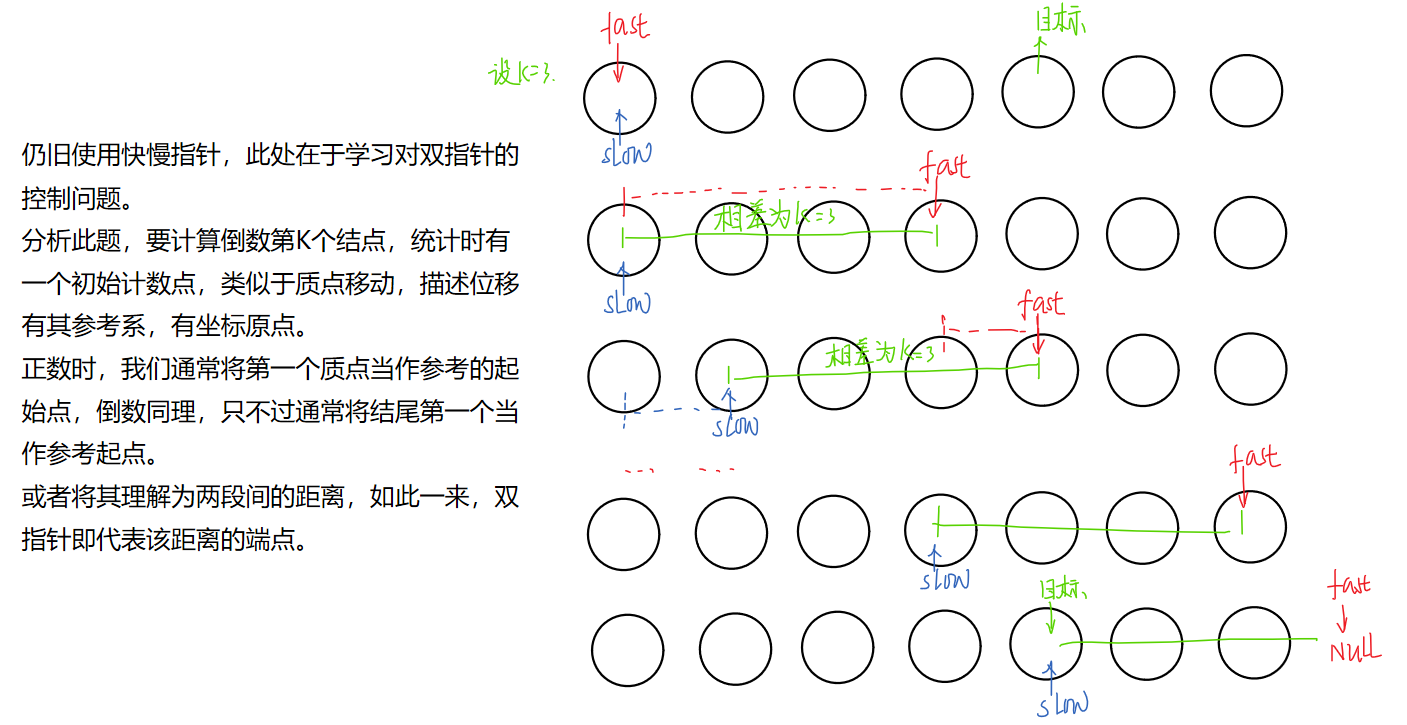
代码:本题的另一关键点在于考虑各种不满足情况,如:链表为空时、给定K值大于链表结点个数时,K=0时。所有这些边界问题都要考虑周全。
另外关于两指针间的差值也不是限制于K,也可以用K-1,只要理清逻辑关系并注意边界问题即可。
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*
* C语言声明定义全局变量请加上static,防止重复定义
*
* C语言声明定义全局变量请加上static,防止重复定义
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
if(pListHead==NULL)//用于防止链表为空时
return NULL;
struct ListNode*fast,*slow;
fast=slow=pListHead;
//调整两指针间距(相差K):
int i=k;
while(i--)
{
if(fast)//用于防止给定k值大于链表实际个数
fast=fast->next;
else
return NULL;
}
//一对一挪动
while(fast)
{
fast=fast->next;
slow=slow->next;
}
return slow;
}
关于判断部分,也可以改写为如下情况:
//调整两指针间距(相差K):
int i=k;
while((i--)&&(fast!=NULL))
{
// if(fast)//用于防止给定k值大于链表实际个数
fast=fast->next;
// else
// return NULL;
}
if(i>=0)
return NULL;
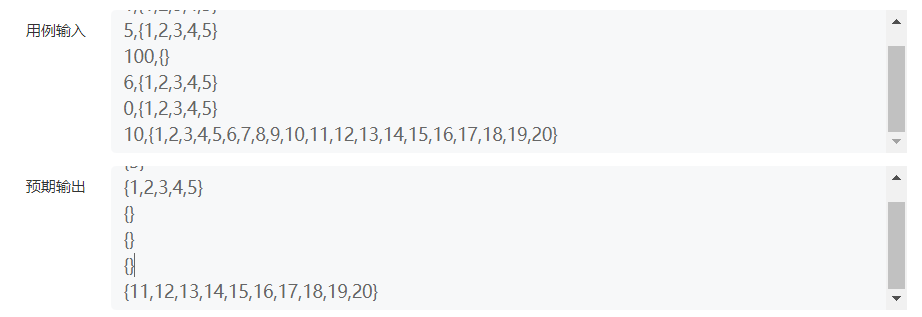
此题中牛客测试用例:
用例输入:
1,{1,2,3,4,5}
5,{1,2,3,4,5}
100,{}
6,{1,2,3,4,5}
0,{1,2,3,4,5}
10,{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20}
预期输出:
{5}
{1,2,3,4,5}
{}
{}
{}
{11,12,13,14,15,16,17,18,19,20}
5、力扣题:合并两个有序链表
题源:力扣题源
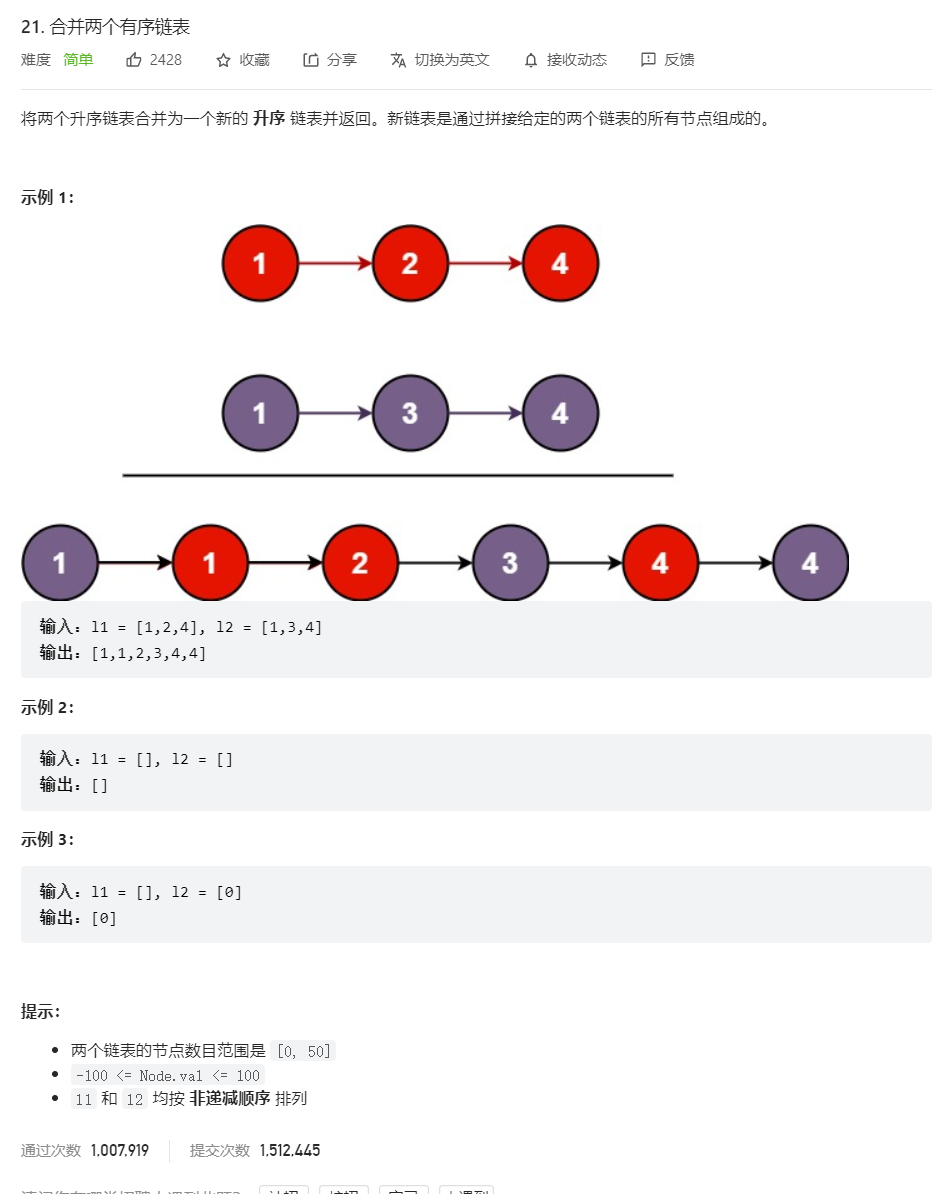
思路分析示意图:若不用并归的方法,另一个方法相当于在pos位置处插入,只不过此方法思考起来需要注意插入位置判断条件。以List1为基链表,让List2在List1中pos位置插入,则判断条件为:list2指针所指向的数据小于list1指针指向数据时,在list1当前指针指向位置前插入。即它涉及到一个何时插入,插在前还是后的问题,需要根据自设的指针来分析判断。

代码如下:上述思路只是针对常规情况,仍旧需要考虑一些边界问题。如:链表为空时.
不带哨兵位,链表为空时要自行判断:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
//链表为空时
if(list1==NULL)
return list2;
if(list2==NULL)
return list1;
struct ListNode*head,*cur;
head=cur=NULL;
//比较
while(list1&&list2)
{
//list1>list2时
if(list1->val>list2->val)
{
if(head==NULL)
{
head=cur=list2;
}
else
{
cur->next=list2;
cur=cur->next;
//此段代码逻辑是理解关键。用于遍历的指针为list1、list2、cur,cur在头结点时和cur在其它结点略有不同( 即头结点时不需要cur=cur->next)。
//cur=cur->next是更新cur指针当前指向关系。在cur=head=NULL时,首次相当于建立指向关系,后续相当于更新。
}
list2=list2->next;
}
else//list1<=list2时
{
if(head==NULL)
{
head=cur=list1;
}
else
{
cur->next=list1;
cur=cur->next;
}
list1=list1->next;
}
}
//剩余结点:由于原链表已经排序,故此处直接链接即可。
if(list1)
{
cur->next=list1;
//此处需要注意赋值指向。在while循环中,cur、list每轮结束后都指向新的未处理的结点,
//因此此处是cur->next=list,而不是cur=list->next或者cur->next=list->next。
//即需要注意指针指向的结点间的关系。
}
if(list2)
{
cur->next=list2;
}
return head;
}
注意细节:对于自定义的指针,需要注意循环结束后不同含义的指针具体的指向位置。
比如上述代码中,对list指针,while循环结束后,其中一个指向NULL,另一个指向下一次需要链接到新链表中的结点。对cur指针,其指向新链表中最后一次链接的结点。因此,若下一次要在新链表中再次链接结点,对cur来说即cur->next,对list来说即为list本身。
带哨兵位时,链表如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
//创建一个带哨兵位的结点,哨兵位不存储有效数据
struct ListNode* head,*cur;
head=cur=(struct ListNode*)malloc(sizeof(struct ListNode));
cur->next=NULL;//带哨兵位的头结点中,此句代码起到处理list1、list2都为空时的情况。
//比较
while(list1&&list2)
{
//list1>list2时
if(list1->val>list2->val)
{
cur->next=list2;
cur=cur->next;
list2=list2->next;
}
else//list1<=list2时
{
cur->next=list1;
cur=cur->next;
list1=list1->next;
}
}
//剩余结点
if(list1)
{
cur->next=list1;
}
if(list2)
{
cur->next=list2;
}
//释放动态空间
struct ListNode* del=head;
head=head->next;
free(del);
//返回头结点
return head;
}
6、牛客题:链表分割
题源:牛客题源
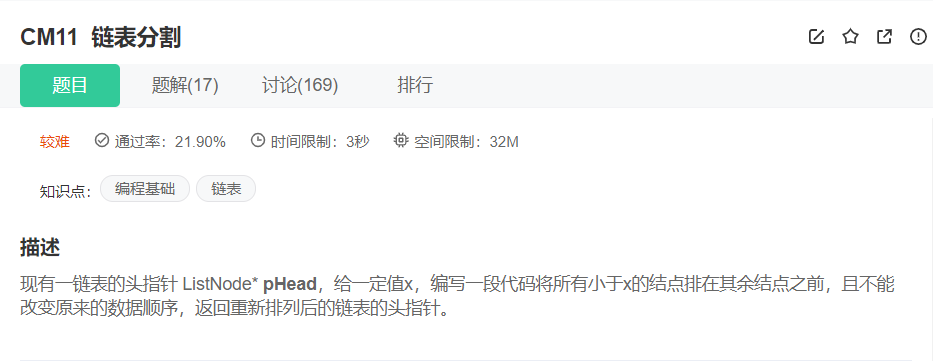
大致思路分析:以X为分界线,创建两链表,一个保存小于X的结点,一个保存大于等于X的结点。遍历依次原链表,将符合要求的结点分别保存在新创建的两链表中,最后再将两链表拼接起来。
此方法一个小关键点在于理清结点和链表的逻辑关系。比如结点尾插时,插入关系如何?再比如,遍历后对应新的两个链表而言,其中list指针此时指向什么位置?两链表链接在一起时,链接关系又是什么样的?(这些细节思考才是此题的关键问题)
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
if(pHead==NULL)
return NULL;
//建立带哨兵位的头结点:
//两个新链表所需指针:每个链表对应的头指针及用于往后挪动的尾插指针
ListNode*headsmall,*headbig,*tailsmall,*tailbig;
headsmall=tailsmall=(ListNode*)malloc(sizeof(ListNode));
headbig=tailbig=(ListNode*)malloc(sizeof(ListNode));
tailsmall->next=NULL;tailbig->next=NULL;
ListNode* cur=pHead;//用于遍历原链表的指针
while(cur)
{
if(cur->val<x)//list1链表:用于链接小于X的结点
{
tailsmall->next=cur;
tailsmall=tailsmall->next;
}
else//list2链表:用于链接大于等于X的结点
{
tailbig->next=cur;
tailbig=tailbig->next;
}
cur=cur->next;
}
//处理两链表间的关系:
//极端场景:都比x小,都比x大,有大有小
if(headbig->next!=NULL)//有大有小的情况以及都比x大的情况
{
tailsmall->next=headbig->next;//小链表的尾链接大链表的头(非哨兵位)
tailbig->next=NULL;//大链表尾结点链接空
}
else if(headbig->next==NULL)//都比x小的情况
{
tailsmall->next=NULL;//小链表尾结点链接空
}
pHead=headsmall->next;
free(headsmall);
free(headbig);
return pHead;
}
};
此处关于两链表尾部处理也可以不用分情况讨论。
//处理两链表间的关系:
//极端场景:都比x小,都比x大,有大有小
tailsmall->next=headbig->next;//小链表的尾链接大链表的头(非哨兵位)
tailbig->next=NULL;//大链表尾结点链接空
pHead=headsmall->next;
free(headsmall);
free(headbig);
7、牛客题:链表的回文结构
题源:牛客题
题目分析:回文结构就是对称结构。
本题可结合前面例题的技巧解决。先二倍查找到中间结点,再把后半段逆置,再用双指针对比是否为对称结构。需要注意奇数结点和偶数结点判断的问题,一个简单的解决办法是,对于奇数结点,多判断一次(即对中间结点的判断)。
侵入式编程:破坏了原来链表的结构

/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
//二倍查找中间结点
struct ListNode* MiddleNode(struct ListNode*A)
{
struct ListNode* slow,*fast;
slow=fast=A;
while(fast && fast->next)//此处为确保fast指向最后一个结点,而非最后的NULL指针
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}
//逆置
struct ListNode*reverseNode(struct ListNode*middle)
{
if(middle==NULL)
return NULL;
//双指针控制及其关系
struct ListNode*n1,*n2,*n3;
n1=NULL;n2=middle;n3=middle->next;
//建立新关系
while(n2)//n2用于判断何时结束
{
//断开
n2->next=n1;
//更迭
n1=n2;
n2=n3;
if(n3)//由于n2最终要指向NULL,需要注意此时n3的指向情况
n3=n3->next;
}
return n1;//注意返回的指针
}
//主体:
bool chkPalindrome(ListNode* A) {
// write code here
//二倍查找中间结点
struct ListNode*middle=MiddleNode(A);
//逆置
struct ListNode*newmid=reverseNode(middle);
//判断
struct ListNode*head=A;
while(head && newmid)//头不为空
{
if((head->val)!= (newmid->val))
{
return false;
}
else
{
head=head->next;
newmid=newmid->next;
}
}
return true;
}
};
8、力扣题:相交链表
题源:力扣题源

关于链表相交的解释:
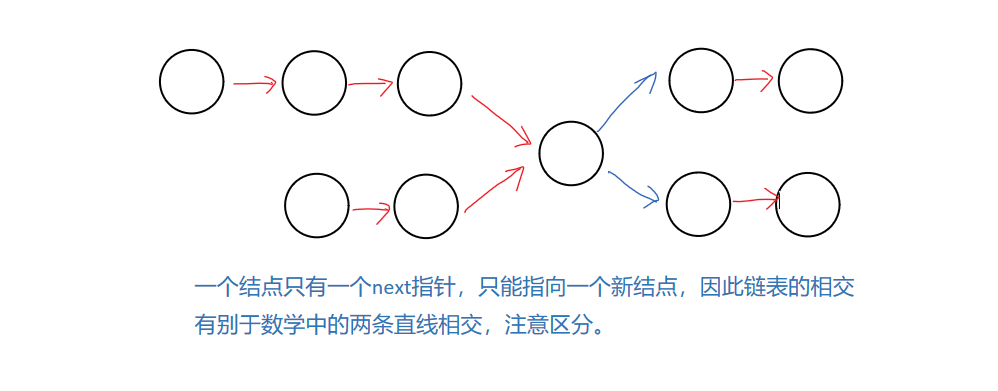
此外还需注意一个问题,链表的相交不是指链表中结点存储数据的相同,而是指结点本身相同,即在比较判断时,应该比较两个结点的地址,而非两个结点中存储的数据。
8.1、思路一:暴力比较法
思路分析:
思路一:
暴力比较法。有A、B两链表,任意选其中一链表为基准(此处选A),另一链表用于反复遍历(此处为B)。则有,对A中的每一个结点,遍历一遍B中的结点,判断是否有地址相同的结点,若有,则A、B两链表相交,若无,则A、B两链表不相交。
此方法时间复杂度为O(nm),即O(n^2)。(此处就体现了是判断结点数据还是判断结点地址本身的区别。此外,此方法相当于在判断是否相交的同时,也寻找了相交的起始结点)
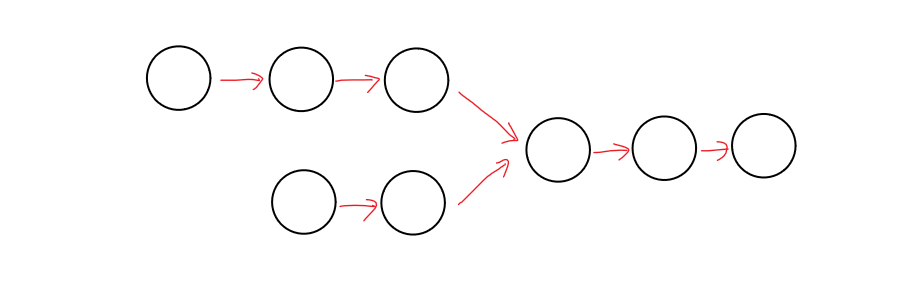
8.2、思路二:找尾结点
思路二:
找尾结点: 根据上述对链表相交的描述,若链表相交,则从相交结点起,后续结点地址相同。那么我们可先判断链表是否相交,再寻找相交的初始结点。
判断链表是否相交: 可通过寻找尾结点的方法,若链表尾结点地址相同,则链表至少有一个相交结点,若尾结点地址不同,则说明链表不相交。
寻找初始结点: 在上述步骤中,对A、B两链表,我们分别遍历了一次,可通过此次遍历求出A、B两链表各自的长度lenA、lenB。求出两链表长度差|lenA-lenB|,然后类比使用快慢指针的方法,让长链表先走单位为长度差个结点(即长链表先走|lenA-lenB|个结点),则此时A、B两链表剩余结点数相同。再分别遍历对比,当首次出现结点地址相同时,即为链表相交结点。
此方法是时间复杂度为O(3n),即O(n)。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
#include <math.h>
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
if(headA==NULL || headB == NULL)
return NULL;
struct ListNode*curA,*curB;
curA=headA,curB=headB;
//步骤一:判断相交:找尾结点,同时求出两链表各自长度
int lenA,lenB;
lenA=lenB=1;
//↑ 关于此处的解释:一个原因是题目中明确说明A、B至少有一个结点,这种写法方便后续对curA,curB遍历后对尾结点的比较。
//↓ 此处直接拿curA、curB作为判断条件,则循环结束时curA、curB指向NULL,而后续还需使用到尾结点,因此循环判断时做出了调整。此处当然也可以选择自己的写法,比如再创建两个周转变量。
while(curA->next)
{
lenA++;
curA=curA->next;
}
while(curB->next)
{
lenB++;
curB=curB->next;
}
//步骤一的结果反馈:
if(curA!=curB)//无相交结点时
return NULL;
else
{
//步骤二:存在相交结点时,先将两链表长度置同
int len=abs(lenA-lenB);//求出交点长度差:abs求绝对值函数
curA=headA;curB=headB;//再次遍历
if(lenA>lenB)
{
while(len--)
{
curA=curA->next;
}
}
else//lenB>lenA
{
while(len--)
{
curB=curB->next;
}
}
//再找出相交交点
while(curA!=curB)
{
curA=curA->next;
curB=curB->next;
}
return curA;
}
}
关于步骤二中找相交结点的另一种写法,需要学习:创建两个长短指针,假设A长,B短,若逻辑错误,则进行修正,使得A短,B长。
//长短指针判断与修正
struct ListNode*longlist,*shortlist;
longlist=headA;shortlist=headB;
if(lenA<lenB)
{
longlist=headB;
shortlist=headA;
}
int gap=abs(lenA-lenB);
while(gap--)//长的先走
{
longlist=longlist->next;
}
while(longlist!=shortlist)
{
longlist=longlist->next;
shortlist=shortlist->next;
}
return longlist;
9、力扣题:环形链表
题源:力扣题源
思路分析:
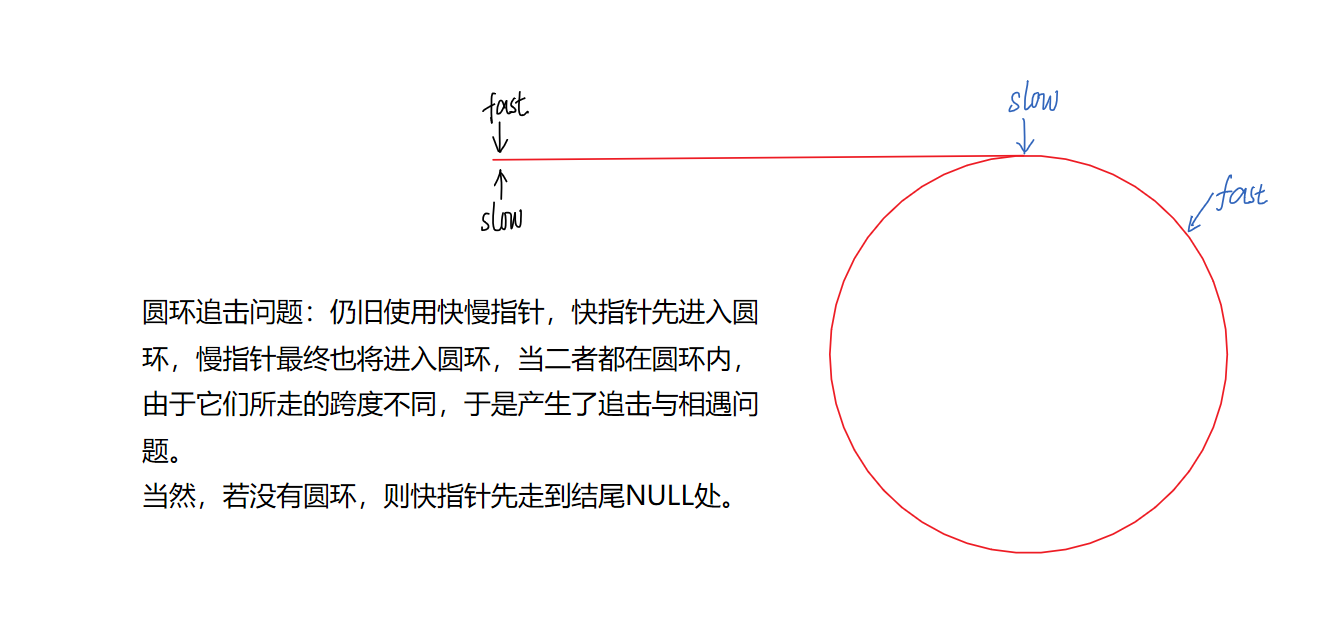
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode*fast,*slow;
fast=slow=head;
while(fast&&fast->next)//快指针指向NULL循环结束。
{ //在使用快慢指针时,由于结点奇偶个数,fast判断部分需都考虑进去。注意此处while中位置判断不可颠倒,此处包含着逻辑运算符短路问题的运用。
//下述if条件和slow、fast指针更新的顺序不能颠倒。
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
return true;
}
return false;
}
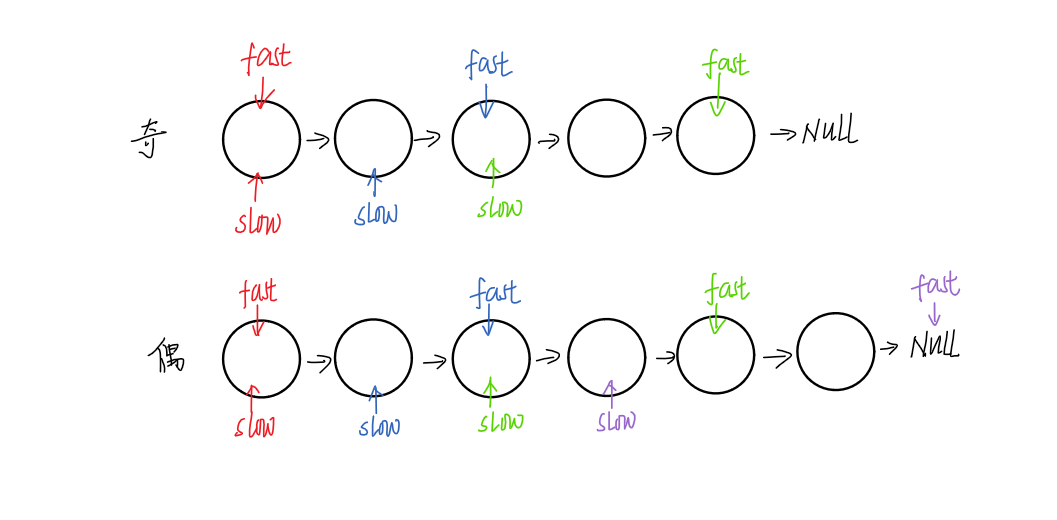
延伸思考:
Q1:证明为什么可通过“快指针每次走两步,慢指针每次走一步”这种方法一定能判断链表是否带环?
假设慢指针开始进入环中,此时其与快指针间的距离(相差结点)为N,当慢指针每次走一步时,快指针每次走两步,此时二者相差距离为N-1,依次类推,两指针间距离以递减数列的方式逐渐减小,最终为0,则代表快指针追上慢指针,说明有环存在。
步数变化情况:N、N-1、N-2、N-3、……、4、3、2、1、0
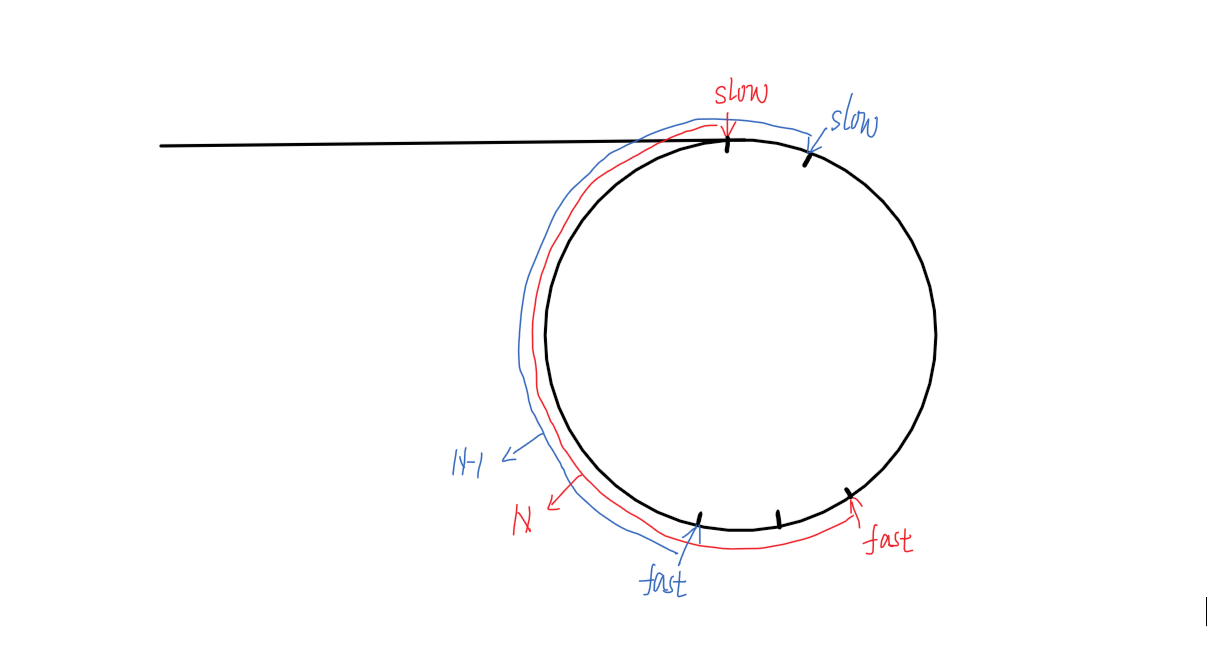
Q2:若快指针一次走三步、四步……k步,慢指针仍然一次走一步,是否可通过这种方法判断链表带环?
此情况下快慢指针不一定能彼此相遇。
步数变换情况:初始相差距离为N,快指针每次走k步,慢指针每次走1步,则快慢指针每走一次,减少距离为k-1步。则有:N、N-(k-1)、N-2(k-1)、N-3(k-1)、……
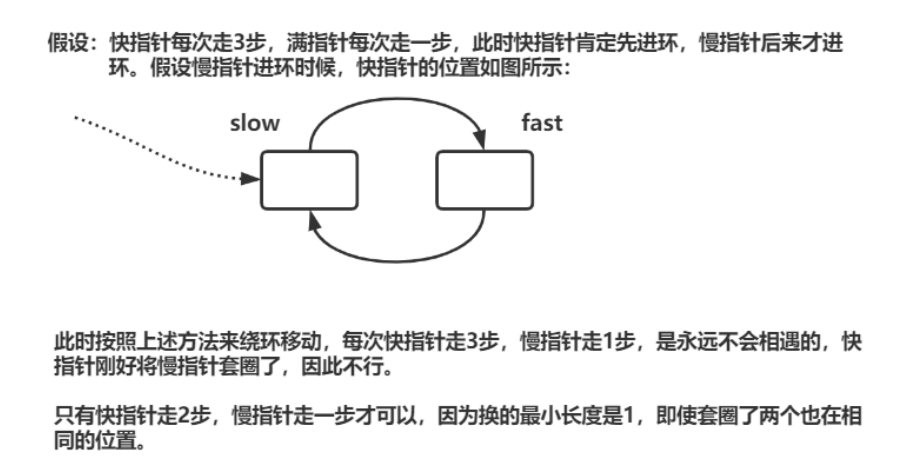
10、力扣题:环形链表Ⅱ
题源:力扣题源
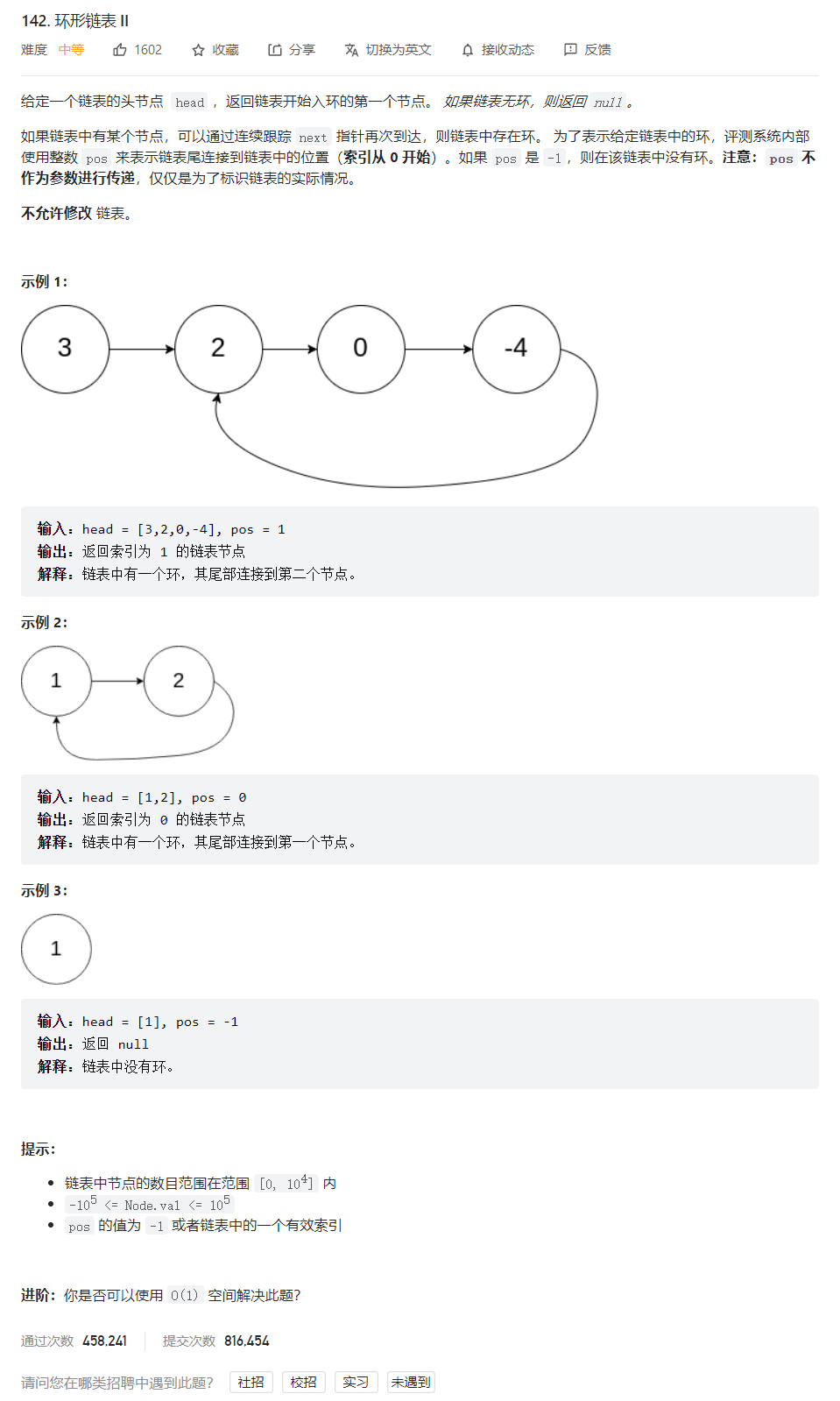
10.1、思路一:
思路分析:
两个注意点:
Q1:环形链表Ⅱ与Ⅰ问题区别在哪?
在上一题中,只要求回答是否能追上,通过快慢指针2:1倍数关系可得出结论。但是需要注意的是,追加过程中,当slow==fast两指针相遇时,它们所在的结点不一定是环的起始结点。而本题要求返回的是环的起始结点,需要注意这个小细节。
Q2:slow进入环后,fast是否能在一圈之内追上slow?
在快慢指针2:1的速度关系中,由上题延伸部分可知,二者间距递减,且此递减关系是连续不间断的。取极限下,fast与slow之间最大差距为一圈(实际中此时相当于相遇了,fast无论转了多少环实际结点位置不变视作一圈看待)。可以把它看作圆上slow在fast之后,二者最小弧度为一个结点,由此开始追击,当fast走完一圈时,根据二者相对运动,slow最多走半圈,当fast再走完一圈时,slow也走完了一圈,回到最初位置,此时fast已经经过slow初始位置,即二者必然有一次相遇。
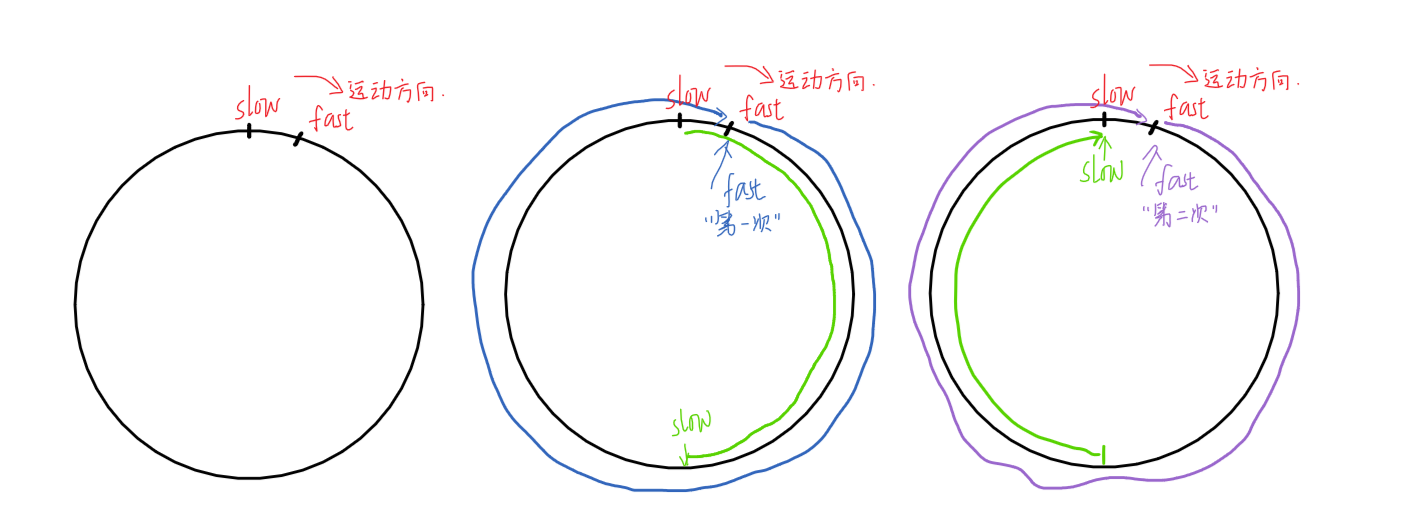
基于上述两个点:
设未相交结点长度为L,进入环前,fast走了N* C(N>0),slow进入环后到与fast初次相遇,走了X距离。则有:
相遇时,slow走的总路程为:L+X
fast走的总路程为:L+X+N* C
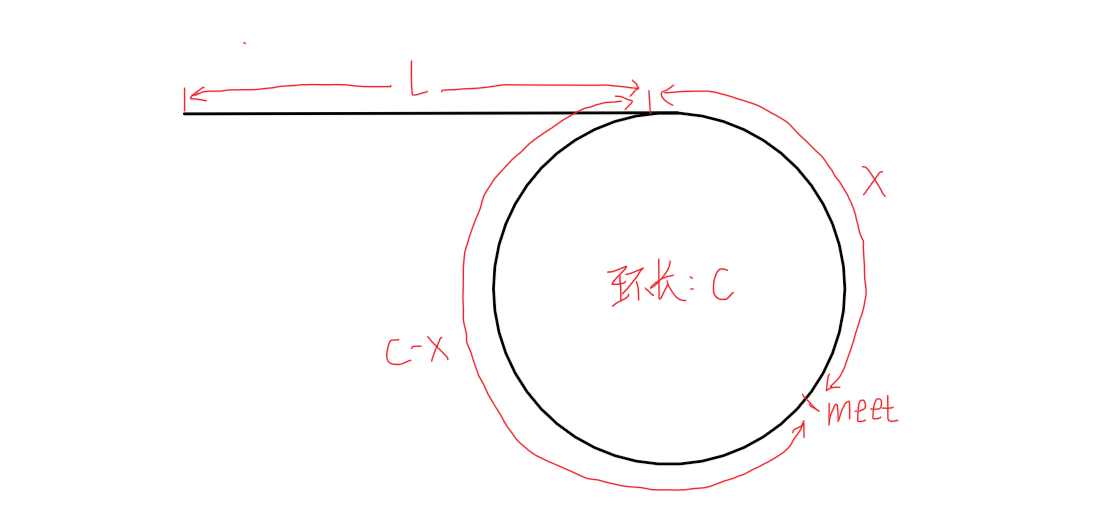
由倍数关系得:2* (L+X) = L+X+ N* C → L = N* C -X →L=(N-1)* C+ (C-X)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode*fast,*slow;
fast=slow=head;
while(fast&&fast->next)//何时停止循环:快指针会遇到尾结点或NULL(无环时的最终情况)
{
slow=slow->next;//慢指针每次走一步
fast=fast->next->next;//快指针每次走两步
if(fast==slow)//有环时,快指针能追上慢指针
{
struct ListNode*meet=slow;
while(meet!=head)
{
meet=meet->next;
head=head->next;
}
return meet;
}
}
return NULL;
}
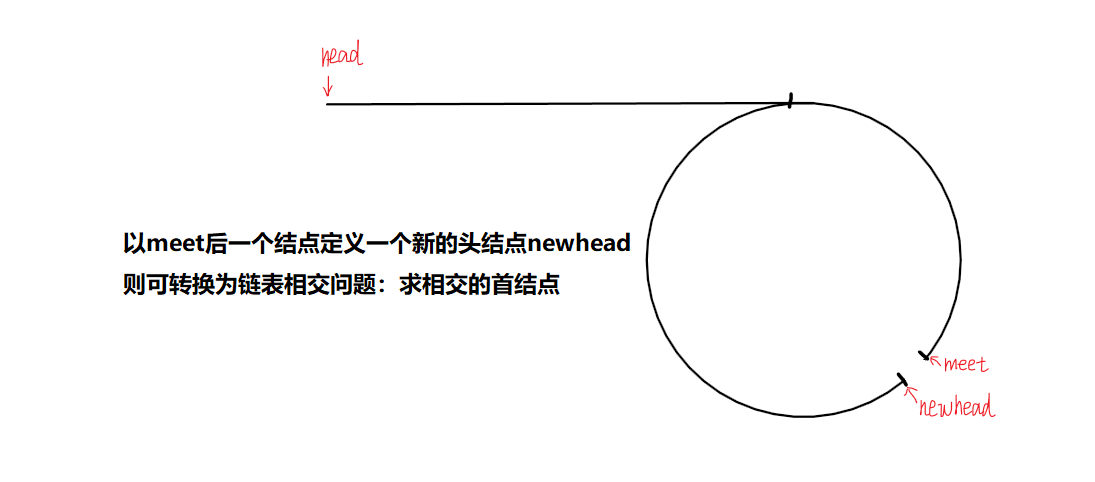
10.2、思路二:
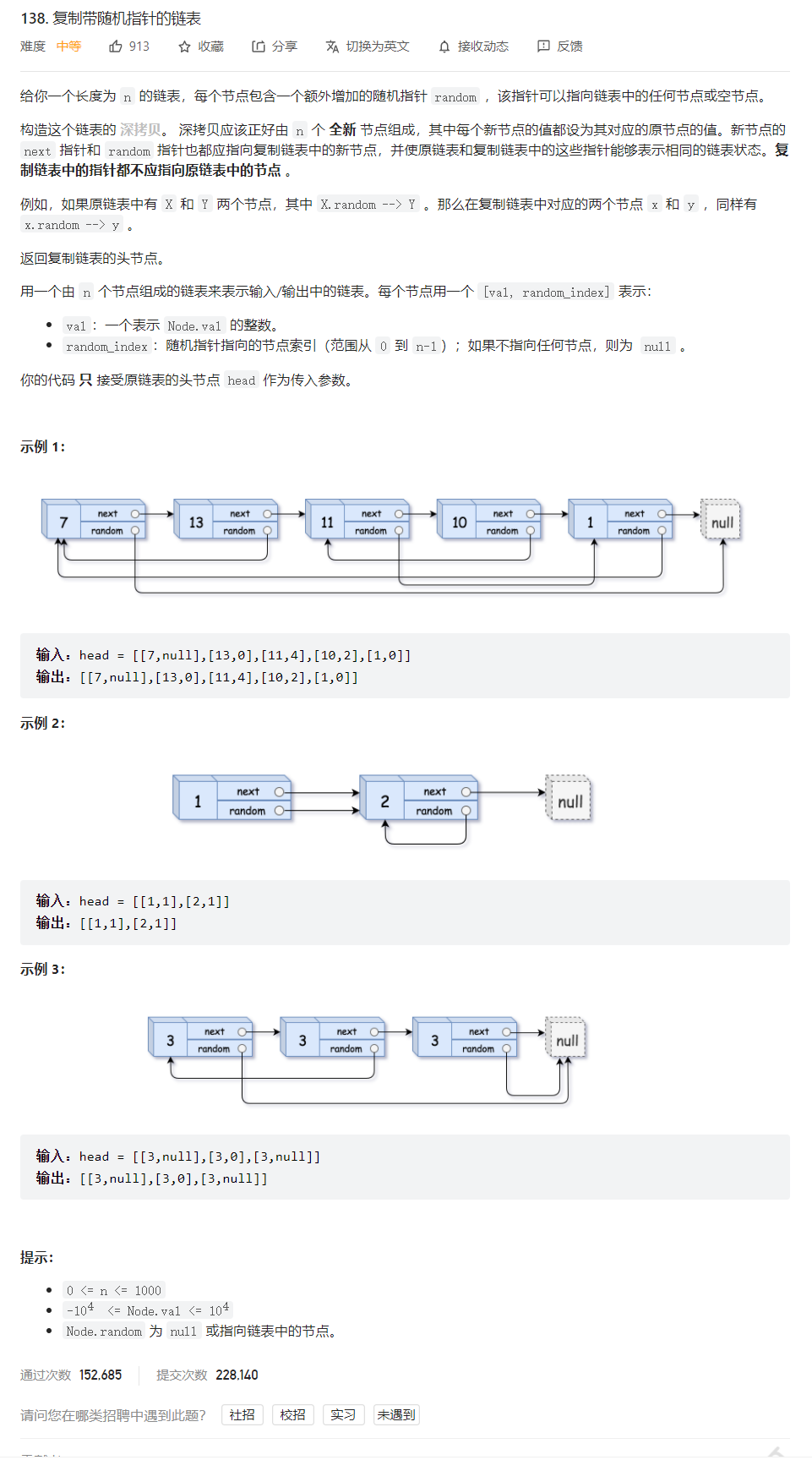
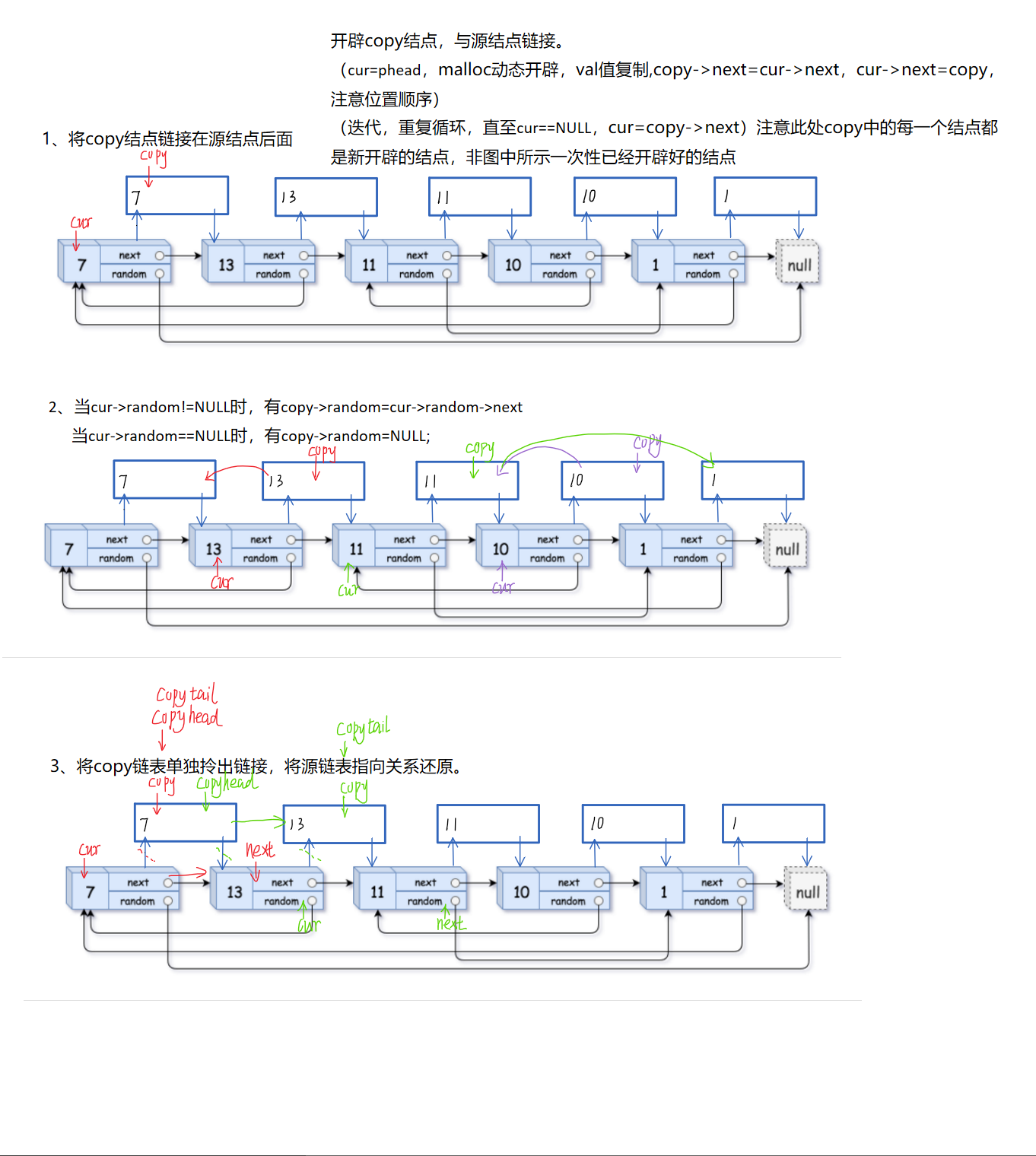
11、力扣题:复制带随机指针的链表
题源:力扣题源
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
//步骤一:copy结点逐一与源链表建立指向关系,在此其间顺带解决copy链表中val值、next指针。
struct Node*cur=head;
while(cur)
{
//新建copy结点:copy链表结点是伴随源链表中cur指针的移动而创建的
struct Node*copy=(struct Node*)malloc(sizeof(struct Node));
//改变指向关系:将源链表与copy链表链接
copy->val=cur->val;//注意此句与下句的位置关系,若先写后者,则源链表关系会断开。此处也可新建一指针来完成指向关系。
copy->next=cur->next;
cur->next=copy;
//更新cur指针:用于遍历
cur=copy->next;
}
//步骤二:解决random
cur=head;//重置源链表cur指向,用于遍历链表
while(cur)
{
//与cur指针当前指向所对应的结点一一对应:copy中random是根据cur在源链表中此时指向结点的random来确定的
struct Node*copy=cur->next;
if(cur->random==NULL)
{
copy->random=NULL;
}
else//cur->random!=NULL时
{
copy->random=cur->random->next;
//源链表和拷贝链表链接后,cur->radnom指向原链表的random
//cur->random->next指向拷贝结点中对应的random
}
cur=copy->next;//cur指针遍历时,遍历的是源链表,而非合并后的两链表
}
//步骤三:复原,重建:复原源链表,对copy链表要单独拎出,使二者成为两个独立的链表
cur=head;//重置源链表cur指向,用于遍历链表
struct Node*copyhead,*copytail;
copyhead=copytail=NULL;
//关于copy链表的构建,可使用带哨兵位的头结点,也可直接构建
//copytail是构建copy链表尾插时需要(方便找尾),copyhead指向copy链表的头结点,最后用于函数返回
while(cur)
{
struct Node*copy=cur->next;
struct Node*next=copy->next;
//尾插
if(copytail==NULL)//即copy链表中首次关系建立:处理copyhead
{
copytail=copyhead=copy;
}
else//后续copy链表可直接尾插
{
copytail->next=copy;//建立当前一轮中copy链表的指向关系
copytail=copytail->next;//更新copy链表中copytail的指向用于下一轮循环
}
cur->next=next;//恢复当前一轮中源链表的指向关系
cur=next;//更新cur指针用于下一轮循环
}
return copyhead;
}
栈和队列
1、力扣题:有效的括号
题源:力扣题源
思路分析:
此题我们采取的思路是借助栈后进先出的特性,根据题目要求,要能达成有效括号,则需要左右括号对应匹配。因此,一个方法是遍历输入的字符串,若遇到左括号,则将其一一入栈,若遇到右括号,则将其与栈顶存储的括号进行比较匹配。
如果匹配不上,则说明这不是有效括号,若匹配上,则将栈顶存储括号删除,进行下一轮的入栈和匹配。
例如:{}()[],先遇到{,将其入栈(当前栈内元素为{),s继续遍历,下一个遇到}是右括号,将其与栈顶元素进行比较匹配,能够对应,则销毁当前栈顶元素(当前栈内元素为NULL),且s继续遍历下一个字符。
例如:({[]}),s指针遍历,前三个字符一一入栈(当前栈内元素为({[),下一个遇到]是右括号,将其与栈顶元素比较匹配,能够匹配上,则销毁当前栈顶元素(当前栈内元素为({)。重复上述操作。
其它:需要考虑一些极端特殊场景。比如,只有左括号、只有右括号。
关于本题的核心部分:
bool isValid(char * s){
ST st;
StackInit(&st);
while(*s)
{
if(*s=='(' || *s=='[' || *s=='{')//若字符为左括号,则入栈
{
StackPush(&st,*s);
++s;
}
else//若为右括号,则与栈中左括号进行匹配,若匹配成功,则说明是有效括号
{
//如果一开始就是右括号,则字符串为无效闭合
if(StackEmpty(&st))//栈为空,说明开始取到的不是左括号是右括号
{
StackDestroy(&st);
return false;
}
//取栈顶的左括号
STDataType top=StackTop(&st);
//删除已经判断的左括号
StackPop(&st);
if( ( top == '(' && *s == ')' )
||( top == '{' && *s == '}' )
||( top == '[' && *s == ']' ) )//满足左右括号有效闭合的情况
{
++s;
}
else//不满足情况时
{
StackDestroy(&st);
return false;
}
}
}
bool ret=StackEmpty(&st);//判断栈是否为空,栈为空时,返回ture
//当字符串中所有括号都逐一满足时,字符串有效
StackDestroy(&st);//销毁栈
return ret;//若ret==0,则说明左右括号成功匹配
}
StackDestroy(&st);注意,每次return返回值前,需要销毁开辟出的栈空间,否则存在内存泄漏的问题。
整体代码如下:
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
//使用malloc开辟动态栈
typedef char STDataType;
typedef struct Stack
{
STDataType* a;
int top;//栈顶
int capacity;
}ST;
void StackInit(ST* ps)
{
assert(ps);//给定一个栈,指向栈的指针不为空
ps->a = NULL;
ps->top = 0;
ps->capacity = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
if (ps->a)//数组不为空
{
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
//扩容检查:
if (ps->top == ps->capacity)//由于没有头插、尾插、pos插入,对应的检验扩容的辅助函数单独拎出,可直接在压栈函数中写
{
int newcapacity = (ps->capacity == 0 ? 4 : ps->capacity * 2);
STDataType* tmp = (STDataType*)realloc(ps->a,sizeof(STDataType) * newcapacity);
if (tmp == NULL)//扩容失败
{
perror("StackPush:realloc");
exit(-1);
}
//扩容成功:
ps->a = tmp;
ps->capacity = newcapacity;
}
//压栈:
ps->a[ps->top] = x;
ps->top++;//此处top的处理取决于初始化时的定义,此处top从0开始,若从-1开始,细节有些区别
}
bool StackEmpty(ST* ps)//判空函数,判断栈中元素是否为空
{
assert(ps);
return ps->top == 0;
}
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;//栈的先进后出性质,尾删实际不需要对栈顶数据做处理,直接修改top即可,但需要注意top有下限,故此处用StackEmpty检验
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
//--------------------------------------------
bool isValid(char * s){
ST st;
StackInit(&st);
while(*s)
{
if(*s=='(' || *s=='[' || *s=='{')//若字符为左括号,则入栈
{
StackPush(&st,*s);
++s;
}
else//若为右括号,则与栈中左括号进行匹配,若匹配成功,则说明是有效括号
{
//如果一开始就是右括号,则字符串为无效闭合
if(StackEmpty(&st))//栈为空,说明开始取到的不是左括号是右括号
{
StackDestroy(&st);
return false;
}
//取栈顶的左括号
STDataType top=StackTop(&st);
//删除已经判断的左括号
StackPop(&st);
if( ( top == '(' && *s == ')' )
||( top == '{' && *s == '}' )
||( top == '[' && *s == ']' ) )//满足左右括号有效闭合的情况
{
++s;
}
else//不满足情况时
{
StackDestroy(&st);
return false;
}
}
}
bool ret=StackEmpty(&st);//判断栈是否为空,栈为空时,返回ture
//当字符串中所有括号都逐一满足时,字符串有效
StackDestroy(&st);//销毁栈
return ret;//若ret==0,则说明左右括号成功匹配
}
2、力扣题:用队列实现栈
题源:力扣题源

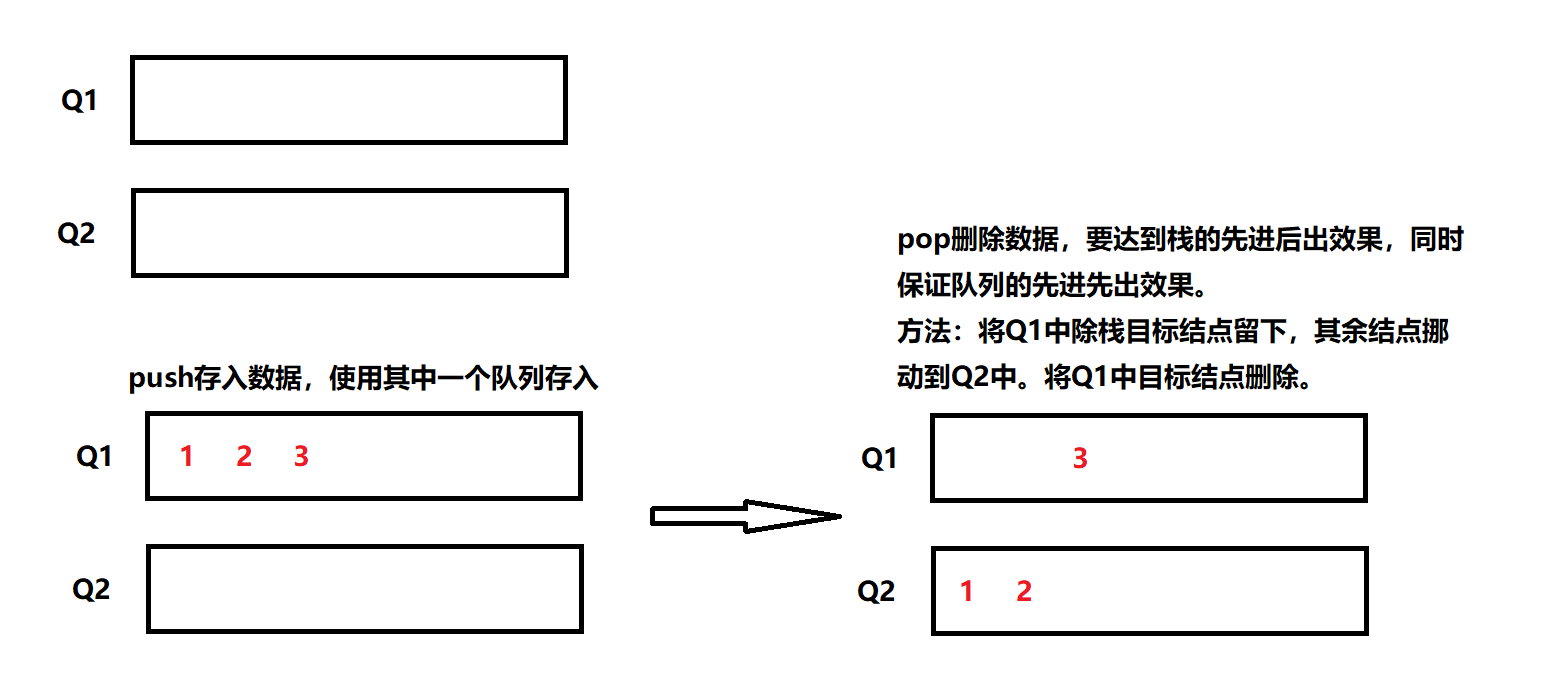
基本思路:本题主要考察的是队列的尾进头出、先进先出和栈的尾进尾出,先进后出不同特性间的转换。不考虑效率情况下,一个相对容易的实现方式是两个队列轮番交换数据进行实现。
分析:pop删除结点,要达到栈的先进后出效果,同时保证队列的先进先出效果。
关于Push、Pop实现细节分析:
方法:将Q1中除栈目标结点留下,其余结点挪动到Q2中。将Q1中目标结点删除。
以Q1中存入结点1、2、3为例,此时对栈使用Pop删除结点,根据其先进后出的性质,是要删除结点3,故结点3之前的数据1、2都要挪动到Q2中,然后对Q1中的剩余结点删除,此时:
对队列,1、2结点按顺序从Q1队头出队,从Q2队尾入队,符合队列特点。
对栈,初始时1、2、3结点从栈顶入栈,出栈时3先出栈,符合栈的特点。
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
//定义一个单链表用作实现队列
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
//QueueSize的一种实现方法,在此间新增一个用于统计结点的变量,随着对队列变动而变动
//int size;
QNode* head;
QNode* tail;//为了方便队列尾插,重新创建一个结构体,加入尾指针
}Queue;
void QueueInit(Queue* pq)
{
assert(pq);//初始化队列结点,结点自然不能为空指针
pq->head = pq->tail = NULL;
}
//队列插入,尾插
void QueuePush(Queue* pq, QDataType x)
{
//分为两种情况,其一为链表(队列)为空时,其二为链表(队列)中有结点时
//当链表为空时,对tail、head都要进行处理;当链表中有结点时,head已有确切指向,只需要对tail进行处理(每链接一个结点,tail指向需要跟随变动)
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));//开辟新结点,注意此处单链表与顺序表的不同之处
if (newnode == NULL)//判空
{
perror("QueuePush::malloc");
exit(-1);
}
//处理结点中数据:
newnode->data = x;
newnode->next = NULL;
//处理指向结点的指针关系:
if (pq->head == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;//已存在结点,只需把结点关系链接上即可,并更新尾指针指向
pq->tail = newnode;//pq->tail->next
}
}
//检查链表(队列)是否为空的函数
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL;
}
//队列删除,头删(此处可看出为什么选择单链表较优,头插在顺序表中要挪动数据,在链表只需要更改头指针和释放对应结点)
void QueuePop(Queue* pq)
{
//思考问题:头删界限,由于结点有限个,头删有下限
//此外,为方便寻找头删后的链表头结点,使用保存下一个结点的方式进行头删,循环下去最终头指针将指向NULL,
//而此时尾指针tail指向NULL前的尾结点,该结点已经被free,则存在tail指向为野指针的问题,需要注意考虑
assert(pq);//用于检查函数传参进入的指针是否为空(即它可能不指向链表,而指向NULL)
assert(!QueueEmpty(pq));//用于检查链表本身是否为空(即pq指针指向链表,但这是一个空链表)
if (pq->head->next == NULL)//链表中只剩一个结点的情况,即链表头指针和尾指针此处重合,该结点next指向NULL
{
free(pq->head);
pq->head = pq->tail = NULL;//此时为了防止tail为野指针,需要将二者置空
}
else//当链表中存在多个结点时(此处如果使用带哨兵位的头结点时,头删到下限即只剩下哨兵位,则细节有些区别)
{
QNode* next = pq->head->next;//保存头结点后一个结点
free(pq->head);//头删
pq->head = next;//新的头结点
}
}
//提出队列头结点数据
QDataType QueueFront(Queue* pq)
{
assert(pq);//指针本身不为空
assert(!QueueEmpty(pq));//链表本身不为空
return pq->head->data;
}
//提取队列尾结点数据
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
//统计队列数据总数
int QueueSize(Queue* pq)
{
//若不在初始结构体中定义变量用于统计结点数目,则在此处需要遍历链表主动求得(效率相对较低)
assert(pq);
QNode* cur = pq->head;
int size=0;
while (cur)
{
++size;
cur = cur->next;
}
return size;
}
//队列销毁
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur=pq->head;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
}
/
//匿名结构体
typedef struct {
Queue Q1;
Queue Q2;//三层结构
} MyStack;
MyStack* myStackCreate() {
MyStack*obj=(MyStack*)malloc(sizeof(MyStack));
if(obj==NULL)//判空,oj题中可省去(通常情况下后台会检查),严谨起见可加上
{
exit(-1);
}
//对MyStack结构体成员初始化:为队列
QueueInit(&obj->Q1);//注意QueueIint参数类型
QueueInit(&obj->Q2);
return obj;
//出结构体对应变量销毁,但malloc开辟出的动态空间仍旧在,主函数中有指向该区域的指针
}
void myStackPush(MyStack* obj, int x) {
//对栈而言,为压栈(栈顶到栈低),对队列而言,为入队(队尾到队头),此处顺序符合各自特性
//其它思考点:两队列的轮番使用方式,Push数据,发生在不为空的队列中,两个队列始终保持一个为空
if(!QueueEmpty(&obj->Q1))//若队列一不为空
{
QueuePush(&obj->Q1,x);//向队列一中插入数据
}
else{
QueuePush(&obj->Q2,x);
}
}
int myStackPop(MyStack* obj) {
//Pop删除数据,需要倒数据,栈中出栈的数据为队列中最后一个数据,因此要将队列目标数据之前的数据通通按顺序出队
//此处倒数据实则借助了其它函数功能,比如,要先将非空队列中的数据倒入空队列中,对非空队列进行QueueFront操作,对空对立进行QueuePush操作,而要导入目标数据前所有数据,则可使用QueueSize得出数据个数。
//一种判断链表为空的方法,在链表相交题目中出现过,需要学习该技巧
Queue* Empty=&obj->Q1;//先假设条件
Queue* NonEmpty=&obj->Q2;
if(!QueueEmpty(&obj->Q1))//当条件不成立时,反过来,即该条件的逻辑需要满足非真即假才能使用
{
Empty=&obj->Q2;
NonEmpty=&obj->Q1;
}
while(QueueSize(NonEmpty)>1)//挪动(复制)数据,当非空队列中数据大于1时,都要挪动(剩下最后一个数据即为符合栈的特性需要删除的数据)
{
QueuePush(Empty,QueueFront(NonEmpty));//先入队(挪动)
QueuePop(NonEmpty);//后出队(删除)
}
//处理栈中需要删除的数据
//题目要求pop需要完成移除并返回栈顶元素,因此此处需要根据需求编写
int top=QueueFront(NonEmpty);
QueuePop(NonEmpty);
return top;
}
int myStackTop(MyStack* obj) {
//题目要求返回栈顶元素,即取栈顶数据,方法与上同。注意此处栈顶的含义,
//对栈而言,数据从栈顶入,再从栈顶出,需要满足先进后出的性质;
//对队列而言,数据从队尾入,再从队头出,需要满足先进先出的性质。
if(!QueueEmpty(&obj->Q1))//若队列一不为空
{
return QueueBack(&obj->Q1);//此处返回栈顶数据,实际为队列中最后一次入队的数据,故使用QueueBack,而非QueueFront
}
else{
return QueueBack(&obj->Q2);
}
}
bool myStackEmpty(MyStack* obj) {
//栈为空,即两个队列要同时满足为空的情况
return QueueEmpty(&obj->Q1)&&QueueEmpty(&obj->Q2);
}
void myStackFree(MyStack* obj) {
//free即销毁栈,此处要先销毁队列
QueueDestroy(&obj->Q1);
QueueDestroy(&obj->Q2);
free(obj);//myStackCreate处开辟了新的动态内存空间,此处free是对其进行处理
}
/**
* Your MyStack struct will be instantiated and called as such:
* MyStack* obj = myStackCreate();
* myStackPush(obj, x);
* int param_2 = myStackPop(obj);
* int param_3 = myStackTop(obj);
* bool param_4 = myStackEmpty(obj);
* myStackFree(obj);
*/
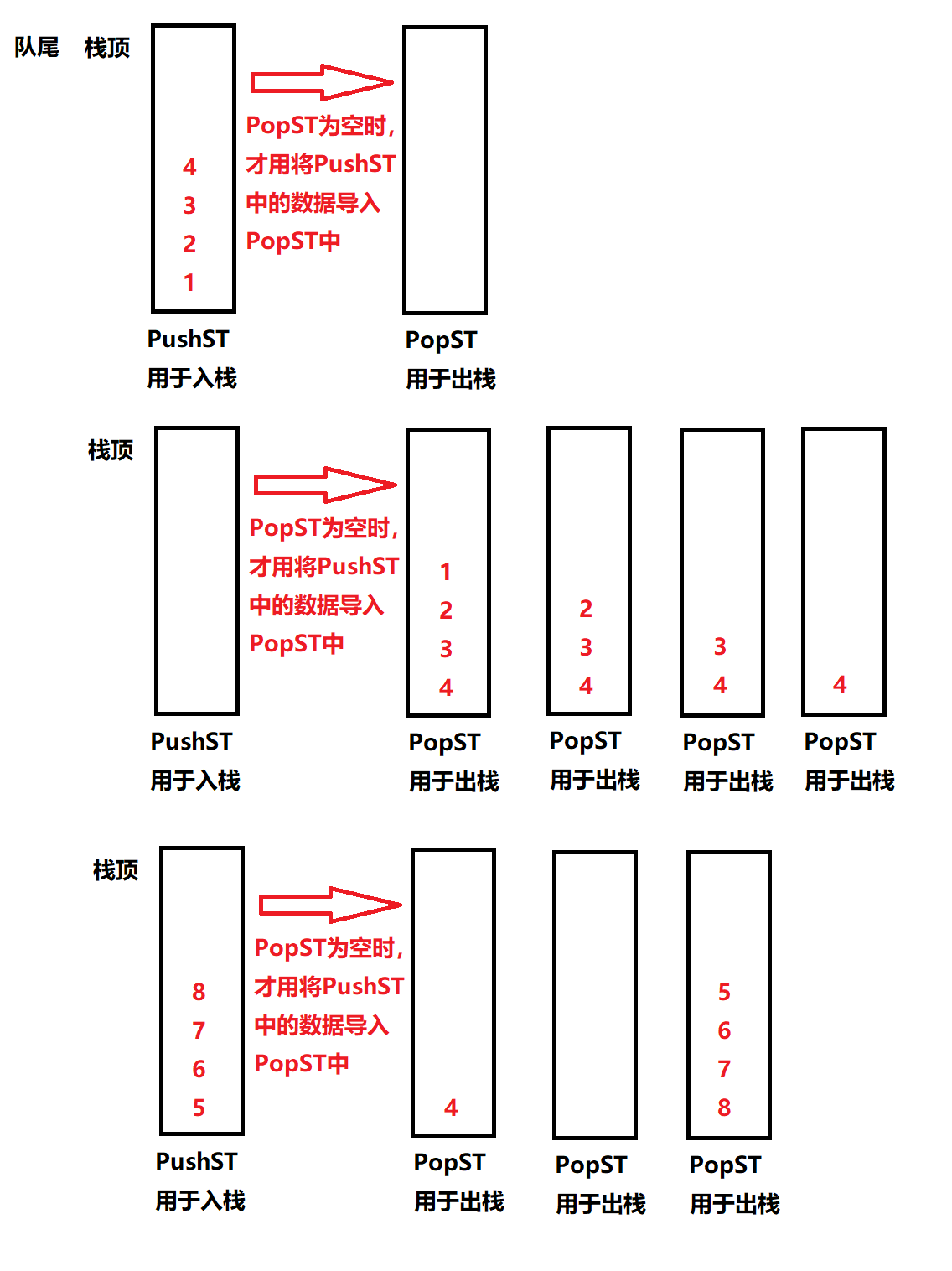
3、力扣题:用栈实现队列
题源:力扣题源

思路图:
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
//静态的栈
//#define N 10
//typedef int STDataType;
//typedef struct Stack
//{
// STDataType a[N];
// int top;//栈顶
// int capacity;
//}ST;
//使用malloc开辟动态栈
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;//栈顶
int capacity;
}ST;
//栈的各种功能实现
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps,STDataType x);//栈只能单向插入数据,即从栈顶插入数据,因此不用像链表、顺序表一样区分头插、尾插、pos位置前插入
void StackPop(ST* ps);//栈只能从栈顶端删除
STDataType StackTop(ST* ps);//获取栈顶元素
bool StackEmpty(ST* ps);//判断栈是否为空
int StackSize(ST* ps);//获取栈中元素个数
void StackInit(ST* ps)
{
assert(ps);//给定一个栈,指向栈的指针不为空
ps->a = NULL;
ps->top = 0;
ps->capacity = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
if (ps->a)//数组不为空
{
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
//扩容检查:
if (ps->top == ps->capacity)//由于没有头插、尾插、pos插入,对应的检验扩容的辅助函数单独拎出,可直接在压栈函数中写
{
int newcapacity = (ps->capacity == 0 ? 4 : ps->capacity * 2);
STDataType* tmp = (STDataType*)realloc(ps->a,sizeof(STDataType) * newcapacity);
if (tmp == NULL)//扩容失败
{
perror("StackPush:realloc");
exit(-1);
}
//扩容成功:
ps->a = tmp;
ps->capacity = newcapacity;
}
//压栈:
ps->a[ps->top] = x;
ps->top++;//此处top的处理取决于初始化时的定义,此处top从0开始,若从-1开始,细节有些区别
}
bool StackEmpty(ST* ps)//判空函数,判断栈中元素是否为空
{
assert(ps);
return ps->top == 0;
}
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;//栈的先进后出性质,尾删实际不需要对栈顶数据做处理,直接修改top即可,但需要注意top有下限,故此处用StackEmpty检验
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
///
typedef struct {
ST PushSt;
ST PopSt;
} MyQueue;
MyQueue* myQueueCreate() {
MyQueue* obj=(MyQueue*)malloc(sizeof(MyQueue));
if(obj==NULL)
{
exit(-1);
}
//对两个栈出初始化
StackInit(&obj->PushSt);
StackInit(&obj->PopSt);
return obj;
}
void myQueuePush(MyQueue* obj, int x) {
//此处两个栈功能分开,因此直接入栈即可。
StackPush(&obj->PushSt,x);
}
int myQueuePop(MyQueue* obj) {
//pop时要注意PopSt是非为空,若为空则需要导入数据.此过程仍旧通过栈的各个接口函数实现
if(StackEmpty(&obj->PopSt))
{
while(!StackEmpty(&obj->PushSt))
{
//先导入后删除
StackPush(&obj->PopSt,StackTop(&obj->PushSt));
StackPop(&obj->PushSt);
}
}
//当PopSt栈中有数据时,才开始对队列进行删除数据操作
//题目要求放回元素,根据需求自行添加语句
int top=StackTop(&obj->PopSt);
StackPop(&obj->PopSt);
return top;
}
int myQueuePeek(MyQueue* obj) {
//返回队头元素,在栈中,即PopSt中栈顶元素,需要注意PopSt为空的情况
if(StackEmpty(&obj->PopSt))//PopSt为空时,若直接在PushSt中队头元素会很麻烦,因此仍旧需要倒一次数据。
{
while(!StackEmpty(&obj->PushSt))
{
//先导入后删除
StackPush(&obj->PopSt,StackTop(&obj->PushSt));
StackPop(&obj->PushSt);
}
}
return StackTop(&obj->PopSt);
}
bool myQueueEmpty(MyQueue* obj) {
//判断队列为空,需要两个栈中都无数据
return StackEmpty(&obj->PopSt)&&StackEmpty(&obj->PushSt);
}
void myQueueFree(MyQueue* obj) {
//free即释放队列,需要对两个栈进行释放,也需要对create函数中申请的MyQueue释放动态空间
StackDestroy(&obj->PopSt);
StackDestroy(&obj->PushSt);
free(obj);
}
/**
* Your MyQueue struct will be instantiated and called as such:
* MyQueue* obj = myQueueCreate();
* myQueuePush(obj, x);
* int param_2 = myQueuePop(obj);
* int param_3 = myQueuePeek(obj);
* bool param_4 = myQueueEmpty(obj);
* myQueueFree(obj);
*/
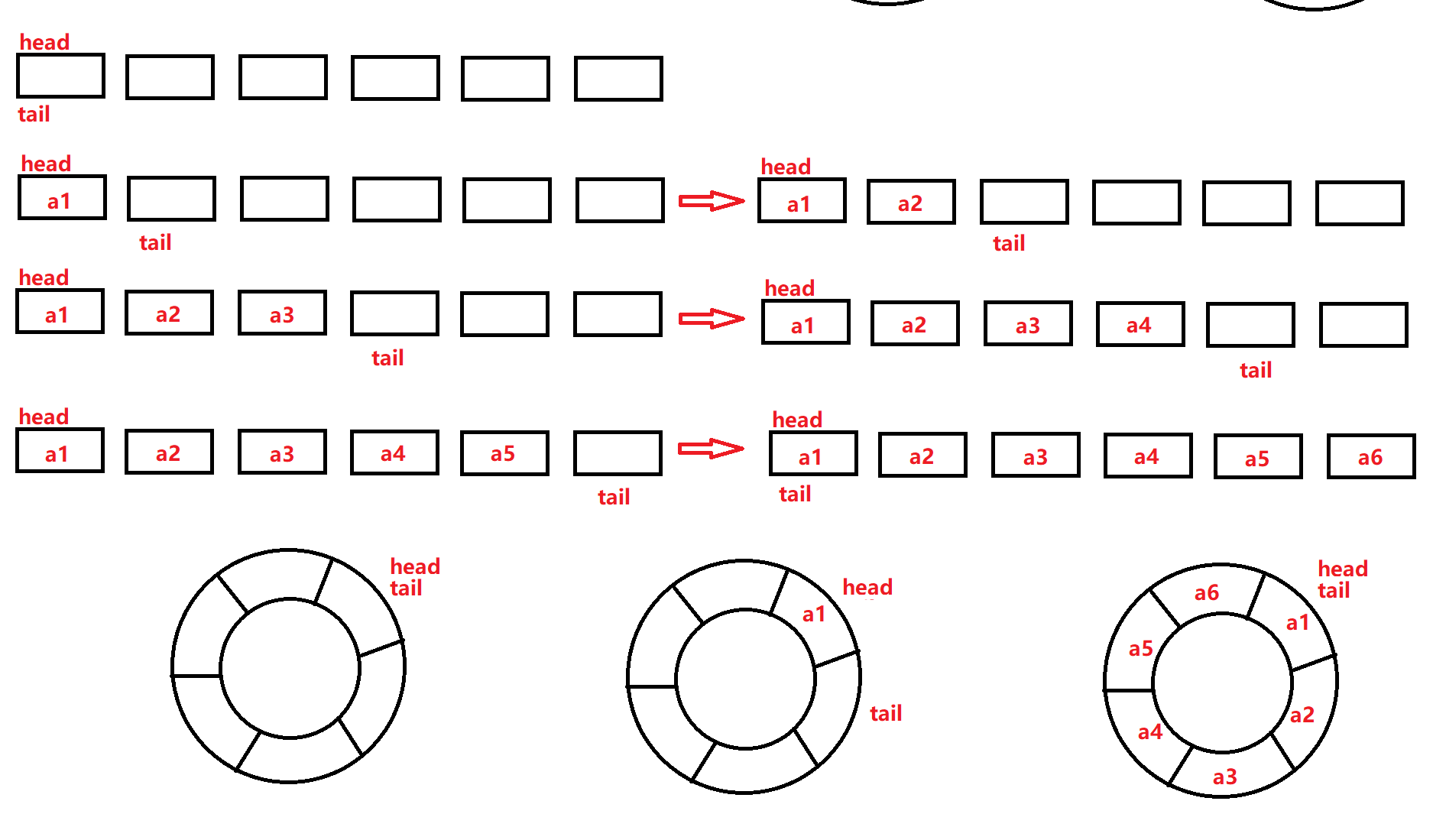
4、力扣题:设计循环队列
题源:力扣题源

环形队列中,基本实现思路如下:tail指针是指向push数据后的下一个新结点,当 head==tail 时,一圈结束。
关于此处循环队列中pop、push的使用方式举例:
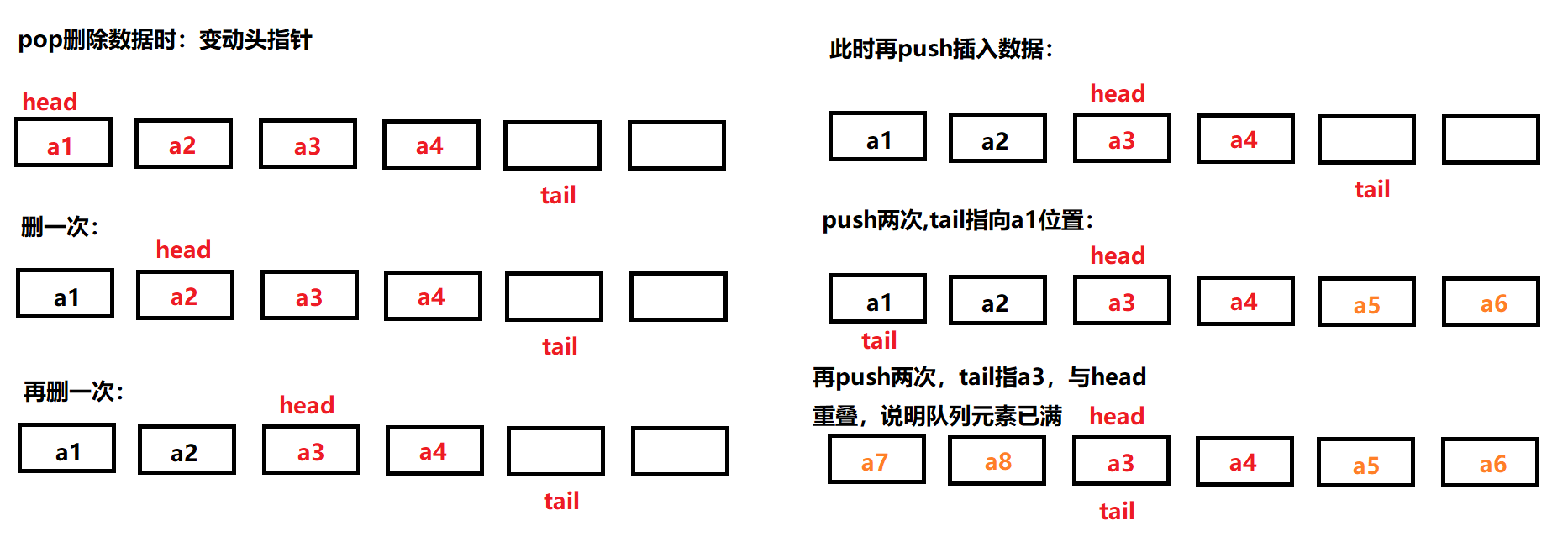
上述例子存在一个问题:如何判断队列已满?
如果用 tail == head , 该条件也可表示队列为空的初始状态,因此无法准确区分。一个解决方案是通过size计数来判断队列是否已满。另一个解决方案是:预留一个结点,通过tail -> next ==head来判断是否为空。
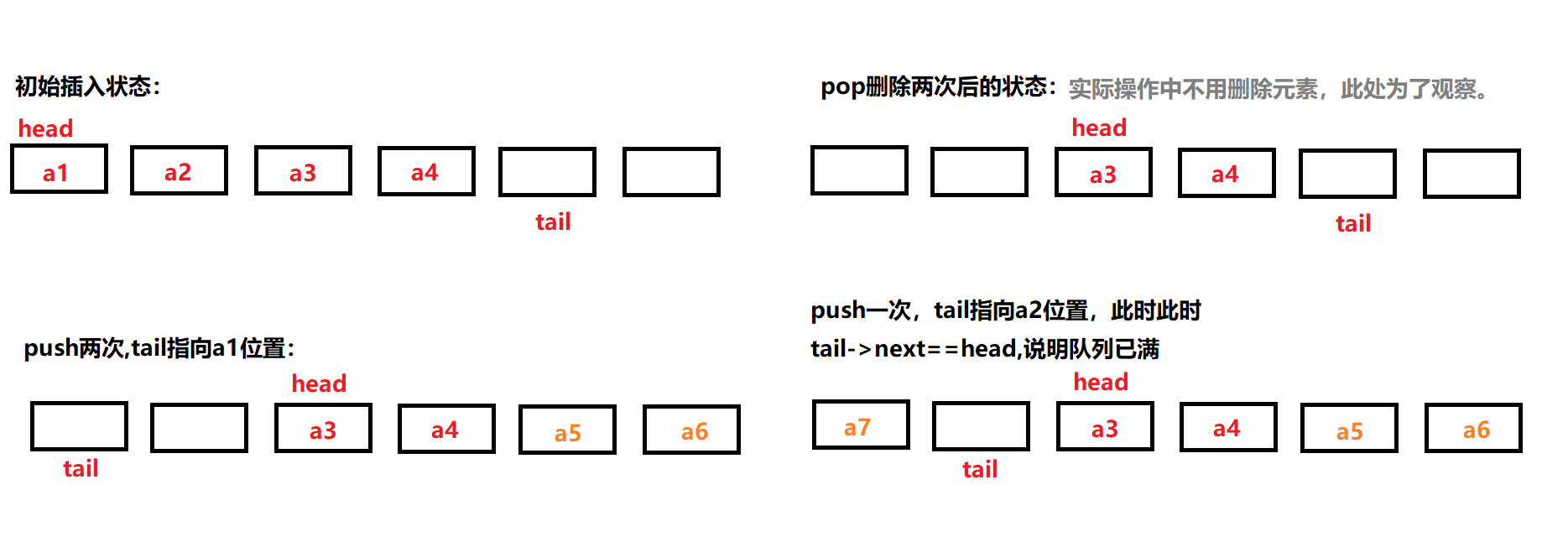
上述方法仍旧有缺点,由于没有指针指向链表尾结点(此情况下tail指向尾结点的下一个结点),找尾结点时会很麻烦。
一种解决方法是使用数组来实现该循环队列。此时tail、head表示数组下标,判断队列是否已满可通过tail+1 =head来实现。但对数组需要判断其边界问题。
typedef struct {
int *a;//数组
int k;//数组长度
int head;//头
int tail;//尾
} MyCircularQueue;
MyCircularQueue* myCircularQueueCreate(int k) {
MyCircularQueue*obj=(MyCircularQueue*)malloc(sizeof(MyCircularQueue));//动态开辟循环队列
obj->a=malloc(sizeof(int)*(k+1));//对结构体中的数组也要单独开辟空间,+1是为了多一个预留结点判断是否为满的情况(题目要求队列中有效数据为K个)
obj->head=obj->tail=0;//初始化
obj->k=k;//初始化
return obj;
}
bool myCircularQueueIsEmpty(MyCircularQueue* obj) {
//队列为空有两种情况,其一是初始数组中无任何元素时,其二是后续使用中删除数组元素使得head下标再此等同于tail下标时
//ps:删除数组元素(出队)时,tail指向不变,head++,二者距离减小
return obj->head==obj->tail;
}
bool myCircularQueueIsFull(MyCircularQueue* obj) {
//数值是否为满有两种情况。
//常规下,由于存在自设的预留结点,若tail+1==head,则说明已满。
//特别的,当head指向数组头部(下标最小值),tail指向数组尾部(下标最大值),此时tail指向的位置作为预留结点不能插入数据
//要注意tail指向的是下一次插入数据的位置。即再次插入数据时需要在tail下标处插入。
int next=obj->tail+1;//即下标为tail+1的位置
if(next==obj->k+1)//即越界时
next=0;
return next==obj->head;//若为真,则返回ture,即队列已满;若为假,则返回false,即队列未满
}
//根据题目要求,入队列,成功返回true,失败返回false(失败即队列已满时)
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
//入队,需要处理数组满时和数组边界问题(对tail的处理)
if(myCircularQueueIsFull(obj))
{
return false;//数组满时,插入失败,根据题目要求返回false
}
//插入数据:
obj->a[obj->tail]=value;
//处理tail指向:此处顺序不能颠倒,要先让tail自增,再来判断其是否越界
obj->tail++;
if(obj->tail==(obj->k+1))//设k=3,实际开辟为4个,数组下标最大值为3,此处越界为k+1=4(tail、head实际指向为数组下标)
{
obj->tail=0;
}
return true;
}
bool myCircularQueueDeQueue(MyCircularQueue* obj) {
//数组为空时,删除失败,根据题目要求返回false
if(myCircularQueueIsEmpty(obj))
{
return false;
}
//删除数组元素,根据队列的性质为头删,因此head下标变化,对实际数据可不做处理。
//和tail一致需要检查越界问题,此处顺序不可调动
obj->head++;
if(obj->head==obj->k+1)
obj->head=0;
return true;
}
int myCircularQueueFront(MyCircularQueue* obj) {
//取对头元素
if(myCircularQueueIsEmpty(obj))//队列为空时
return -1;
return obj->a[obj->head];
}
int myCircularQueueRear(MyCircularQueue* obj) {
//取队尾元素,实际返回为tail-1
if(myCircularQueueIsEmpty(obj))//队列为空时
return -1;
//对tail下标为0时需要做处理(此时tail-1=-1)
int prev=obj->tail-1;
if(obj->tail==0)
prev=obj->k;
return obj->a[prev];
}
void myCircularQueueFree(MyCircularQueue* obj) {
//create时开辟了两次动态内存空间,都要分别对其进行释放(根据结构体及其内部成员间的关系来写代码,此处顺序不能调换)
free(obj->a);
free(obj);
}
/**
* Your MyCircularQueue struct will be instantiated and called as such:
* MyCircularQueue* obj = myCircularQueueCreate(k);
* bool param_1 = myCircularQueueEnQueue(obj, value);
* bool param_2 = myCircularQueueDeQueue(obj);
* int param_3 = myCircularQueueFront(obj);
* int param_4 = myCircularQueueRear(obj);
* bool param_5 = myCircularQueueIsEmpty(obj);
* bool param_6 = myCircularQueueIsFull(obj);
* myCircularQueueFree(obj);
*/
如果用取模的方式来判断越界:
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
//入队,需要处理数组满时和数组边界问题(对tail的处理)
if(myCircularQueueIsFull(obj))
{
return false;//数组满时,插入失败,根据题目要求返回false
}
//插入数据:
obj->a[obj->tail]=value;
//处理tail指向:此处顺序不能颠倒,要先让tail自增,再来判断其是否越界
obj->tail++;
obj->tail%=(obj->k+1);//取模的方法
return true;
}
int myCircularQueueRear(MyCircularQueue* obj) {
//取队尾元素,实际返回为tail-1
if(myCircularQueueIsEmpty(obj))//队列为空时
return -1;
//对tail下标为0时需要做处理
int prev=obj->tail-1+(obj->k+1);//取模的方法
prev%=(obj->k+1);
return obj->a[prev];
//改进写法:return obj-> a[(obj->tail+k) %= (obj->k+1)]
}














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









