










目录:
- 概述
- 代表性人物
- 应用领域
- 相关资料
从科学、技术和人工智能诞生之初,科学家们就在设想:机器如何能够像人类一样聪明。很多的作家通过文学作品描述这个场景,比如星球大战等等。而机器学习与深度学习是最有希望突破的两个方向。本文中我将主要介绍深度学习的简史、代表性人物、应用领域和相关的资料总结。

概述
深度学习(Deep Learning)的概念源于人工神经网络的研究,含多隐层的多层感知器就是一种深度学习结构,是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次的,更加抽象的表达。通过足够多的转换的组合,非常复杂的函数也可以被学习。
深度学习的核心方面是,上述各层的特征都不是利用人工工程来设计的,而是使用一种通用的学习过程从数据中学到的。
下面这是Ian Goodfellow,Yoshua Bengio, Aaron Courville《Deep Learning》中关于深度学习的描述。
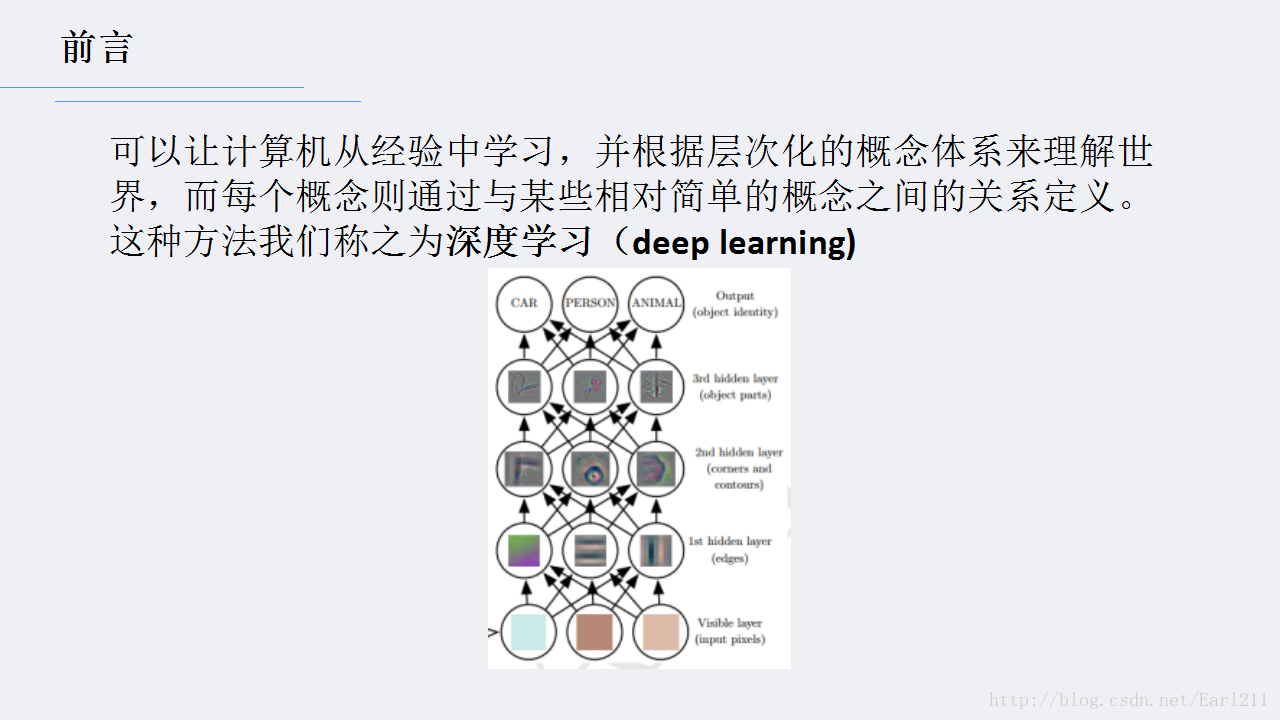
这是近几年火遍各个领域的词汇,似乎所有的算法只要跟它扯上关系,瞬间就显得高大上起来。但其实,从2006年Hinton在Science上的论文算起,深度学习发展至今才不到十年。深度学习与机器学习始终分不开,看一下他们两个的简史:

- 1949年,Hebbian提出神经心理学学习方式——Hebbian学习理论
- 1957年,Rosenblatt的感知器算法,与今天的ML很像。
- 1969年,Minskey的XOR问题论证了感知机在类似XOR问题的线性不可分数据的无力,给感知机画上了一个逗号,将ML暂时封印了起来。
- 1970年,Linnainmaa的自动微分的翻转模式揭开了神经网络的一角
- 1981年,Werbos的多层感知机算彻底打开了封印
- 1985-1986年,NN研究中成功的使用BP算法来训练MLP。(Rumelhart, Hinton, Williams - Hetch, Nielsen)
- 随后另一个很出名的算法——决策树也被提出来了,随后ID3,ID4回归树,CART等等都雨后春笋般的出现,在SVM与DL没出来之前,一度承载了ML的未来,至今还在应用。
- 1995年,ML领域最重要的一个突破——支持向量机(SVM)由Vapnik 与 Cortes提出。 从图中可以看到,SVM从提出到现在一直占据ML届的半壁江上。
- 于此同时,我们看看NN(神经网络)派,外部面临着SVM的挑战,内部Hochreiter表明BP算法在NN党员饱和后悔发生梯度损失。
- 1997年,另一个坚实的ML模型AdaBoost由Freund和Schapire提出。
- 2001年,Breiman基于AdaBoost的思想,提出将多个决策树组合起来的模型(随机森林RF)。这个模型让决策树的性能与SVM有了一拼之力。
- 时间终于来到了当下,我们的主角——深度学习登场了。在这个阶段NN模型可以拥有多层,3层的NN模型被Hinton,LeCun, Bengio, Andrew Ng等诸多大师一一实现。
- 2012年,《纽约时报》披露了Google Brain项目,这个项目由机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家JeffDean共同主导,训练了一种“深度神经网络(DNN)”,能够自动认识到猫这种概念.
- 2012年底,Geoff Hinton的博士生Alex Krizhevsky、Ilya Sutskever(他们研究深度学习时间并不长)在图片分类的竞赛ImageNet上,识别结果拿了第一名。其实类似的比赛每年很多,但意义在于,Google团队也在这个数据集上做了测试(非公开的,Google没有显式参加学术界的“竞赛”),用的也是深度学习,但识别精度比Geoff Hinton的团队差了很多,这下工业界振奋了。这是深度学习火起来的标志性时间
- 2013年1月,在百度的年会上,创始人兼CEO李彦宏高调宣布要成立百度研究院,其中第一个重点方向就是深度学习,并为此而成立Institute of Deep Learning(IDL)。
- 2013年4月,《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术(Breakthrough Technology)之首。
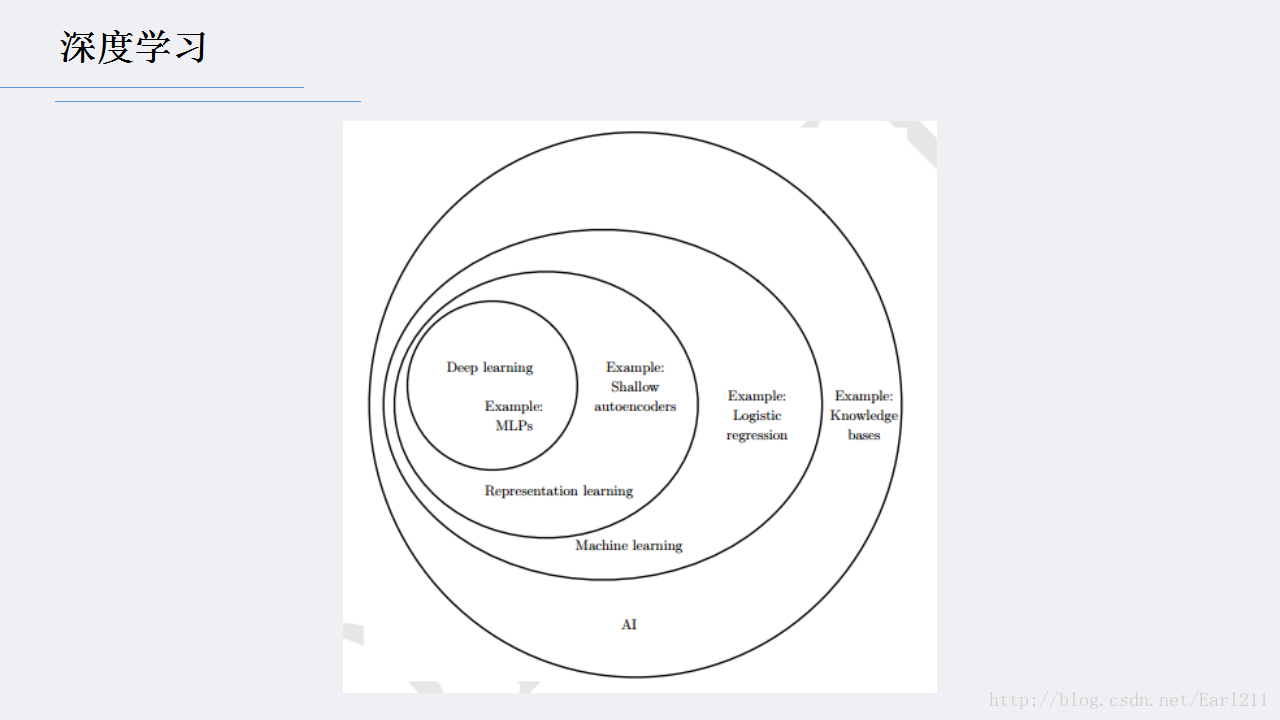
deep learning本身算是machine learning的一个分支,简单可以理解为neural network的发展。大约二三十年前,neural network曾经是ML领域特别火热的一个方向,但是后来确慢慢淡出了,原因包括以下几个方面:
1,比较容易过训练,参数比较难tune;
2,训练速度比较慢,在层次比较少(小于等于3)的情况下效果并不比其它方法更优;
所以中间有大约20多年的时间,神经网络被关注很少,这段时间基本上是svm和boosting算法的天下。但是,一个痴心的老先生hinton,他坚持了下来,并最终(和其它人一起bengio、yann.lecun等)提成了一个实际可行的deep learning框架。
应用领域
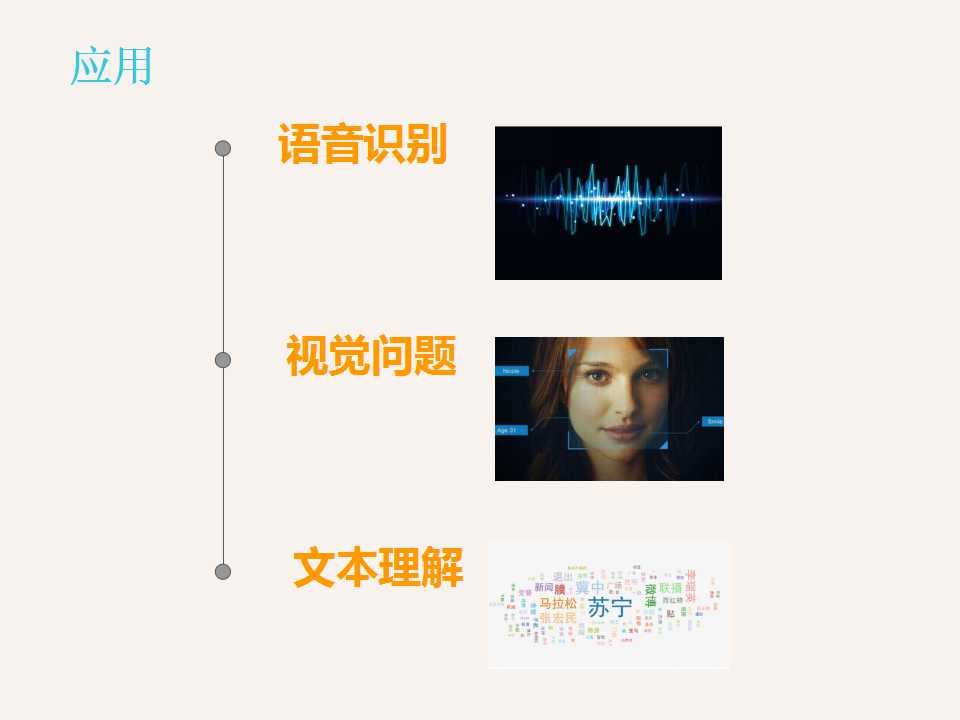
深度学习的应用主要由上面的三个方面:语言识别,计算机视觉,文本建模
语音识别上,2009年,Hinton把深层神经网络介绍给做语音识别的学者们。然后2010年,语音识别就产生了巨大突破。本质上是把传统的混合高斯模型(GMM)替换成了深度神经网络(DNN)模型,但相对识别错误率一下降低20%多,这个改进幅度超过了过去很多年的总和。这里的关键是把原来模型中通过GMM建模的手工特征换成了通过DNN进行更加复杂的特征学习。在此之后,在深度学习框架下,人们还在不断利用更好的模型和更多的训练数据进一步改进结果。现在语音识别已经真正变得比较成熟,并且被广泛商用,且目前所有的商用语音识别算法没有一个不是基于深度学习的。
计算机视觉上人们初步看到了深度网络的优势,但还是有很多人质疑它。语音识别是成功了,那么图像分类呢?2012年之前,深度学习好像还是只能处理像MNIST手写体分类这样的简单任务。说来也巧,这时候正举行了两届ImageNet比赛。这是一个比手写体分类复杂得多的图像分类任务,总共有100万张图片,分辨率300x300左右,1000个类别。前两届的冠军采用的都是传统人工设计特征然后学习分类器的思路。第一届是2010年,当时冠军的准确率(top 5精度)是71.8%,而2011年是74.3%。由于Hinton经常被其它研究人员“嘲讽”说深度学习在图像领域没有用,于是2012年,Hinton和他的学生Alex等人参赛,把准确率一下提高到84.7%。
当然,他们的成功借助了ImageNet这个足够大的数据集,借助了GPU的强大计算能力,借助了比较深层的CNN网络,借助了随机梯度下降(SGD)和Dropout等优化技巧,借助了训练数据扩充策略(Data Augmentation)。但无论如何,他们靠着深度学习震惊了机器学习领域,从此大量的研究人员开始进入这个领域,一发不可收拾。2013年是89%,2014年是93.4%,截止到现在(2015年5月份),ImageNet数据集的精度已经达到了95%以上,某种程度上跟人的分辨能力相当了。
关于文本,一个很重要的工作是词向量(word2vec)。词向量是指通过对大量文本的学习(不需要标注),根据前后文自动学习到每个词的语义,然后把每个词映射为一个紧凑的实数向量形式的表达,而且具有很多好的性质,比如vec(中国)减去vec(北京)约等于vec(英国)减去vec(伦敦)。这里强调一句,这种向量化的紧凑表达形式在深度学习中是非常重要和普适的。任何抽象的知识都可以建模成这种紧凑的向量形式。类似的还有很多扩展性工作,比如,人们研究如何把一句话映射为一个向量,甚至把一段文字映射为一个向量。
文本的各个词之间是有顺序的,而传统做法总是采用词袋模型忽略掉这些顺序。为了更好的挖掘和利用这个性质,人们渐渐倾向于采用递归神经网络(RNN)来描述它。RNN也不是什么新鲜事物,其实就是允许节点之间的连接有环的存在。不过就像我们之前说的,大数据、GPU、优化、深度学习在其它领域的突破等等又给它带来了新的活力。RNN做文本理解的大概思路是,按顺序处理一段话的每个单词,在它看到后面内容的时候,它的某些参数里还保留着对前面看到过的信息的“整合和抽象”。没错,它是有一定的记忆功能的,而且不需要人为告诉它应该记住什么,它会从训练数据中自然的进行学习,然后记忆在“环”里。可以想像,RNN的结构比普通神经网络复杂,而且优化过程更加困难,但目前已经有了BPTT、LSTM等很多解决方案,在这方面有着很多的相关工作,总体来看,结果让人觉得很有希望。
当然还有很多其他的应用,比如量化交易,金融,搜索广告CTR预估。
代表性人物
Geoff Hinton是深度学习学派的祖师爷,老爷子腰椎不好,经常得站着写代码到夜里一点,不能坐飞机,得坐火车从东边到西边去开会。

Geoff Hinton,deep learning 学派创始人之一
Yann Lecun 是 Geoff Hinton 三十年前的弟子。最近深度学习应用于智能理解特别广泛的模型是卷积神经网(ConvNet),就是 Yann Lecun 发明的 / 命名的。在学术上,这和传统的深度学习其他的模型有显著性差异 —— 我甚至认为这是思想性的巨大差异(世界可学性的假设)。

上图右为Yann Lecun,卷积神经网的发明者,Geoff Hinton的弟子
Yoshua Bengio教授( 个人主页)是机器学习大神之一,尤其是在深度学习这个领域。他连同Geoff Hinton老先生以及 Yann LeCun教授,缔造了2006年开始的深度学习复兴。他的研究工作主要聚焦在高级机器学习方面,致力于用其解决人工智能问题。

Andrew Ng 是 Michale Jordan( Berkeley 教授,图模型的泰斗)的明星弟子,Andrew 独立后,在Stanford,、Google 和 Baidu 做的反而是deep learning (有点武当弟子学了少林,或者少林弟子学了武当的意味)。后来做了网络公开课程Coursera后名声大噪,意义大大超越了其学术界的地位和范畴。

上图为吴恩达(Andrew Ng),百度首席科学家,在线教育平台coursera的创始人
相关资料
网上有很多的资料,给的再多也不如懂我。每个人的知识储备不一样,所需要的也不一样,这里只列出我自己接下来需要的阅读参考的资料(不定期更新补充):
书:
Deep Learning by Yoshua Bengio, Ian Goodfellow and Aaron Courville
教程:
UFLDL Tutorial 1
UFLDL Tutorial 2
视频:
Deep Learning, Self-Taught Learning and Unsupervised Feature Learning By Andrew Ng
Frameworks:
DeepLearning4J
更资料请到:
Deep learning Reading List















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









