







文章目录
1 DeepFashion2数据集介绍
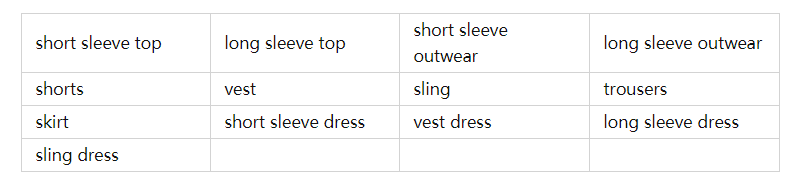
该数据集包含19W+训练样本和3W+测试样本,样本中包含各类服装的买家秀和卖家秀图像。并且,数据集包含style,bounding-box,dense landmarks和masks多种标签,可以用于训练服装检测、实例分割、关键点检测等多种任务的模型。数据集中的服装包括模特或买家穿在身上的服装以及未穿着的服装。针对DeepFashion数据集存在一些服装类别难以区分的情况,该数据集的服装类别标签改为以下13类,下图为各类别训练样本数量。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YzDx0w69-1606804433274)(C:\Users\Eason_Cai\Desktop\image-20201110093308076.png)]](https://i-blog.csdnimg.cn/blog_migrate/723b5ef4d8ef29275b90d74ea8cbf93f.png)
下图为DeepFashion2数据集中的一些数据实例,用于说明该数据集具有尺度、缩放、视角和遮挡等多样性,能够有效地帮助模型学习具有更好泛化能力的模型。

数据集的获取和详细介绍,请参见文尾链接:
2 数据集格式转换
2.1 DeepFashion 标注格式转为COCO标注格式
完成数据集的下载后,将数据集进行解压(解压密码通过上面的Github项目给出的链接,给官方发邮件申请,过程不长),我们得到train和validation的文件夹,文件夹结构如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OG69RXQI-1606804433280)(C:\Users\Eason_Cai\Desktop\image-20201110162225158.png)]](https://i-blog.csdnimg.cn/blog_migrate/b58559f23ece8af8306849307aab281f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LFSp9Evs-1606804433283)(C:\Users\Eason_Cai\Desktop\image-20201110162255352.png)]](https://i-blog.csdnimg.cn/blog_migrate/9e43ca80e8c74fc6fa380e983b4b2196.png)
其中,annos文件夹为标注文件,image文件内为原始图像文件。然后,使用这个链接的代码可以将DeepFashion的标注格式转换为COCO格式。
注意:在使用时代码时,根据处理的对象是train还是validation,相应地将代码的第244行的json_name变量改为"train.json"或者"valid.json"。并且,将第118行和第119行改成对应的文件路径。
然后,分别对训练集和验证集执行一次该代码,我们将会在DeepFashion2路径下面得到train.json和valid.json两个COCO格式标注的标注文件。由于图像数量很大,该转换过程需要执行一段时间,耐心等待即可。
2.2 转换成YOLO格式
由于我们这里只训练目标检测模型,仅需要获取标签文件中的位置标签。
- 首先,我们克隆这个链接的Format.py和example.py文件到DeepFashion2文件夹下面,并在该文件夹下面创建一个“fashion_classes.txt”文件,里面写入着装类别标签,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lpqkIj0i-1606804433286)(C:\Users\Eason_Cai\Desktop\image-20201110172552597.png)]](https://i-blog.csdnimg.cn/blog_migrate/a2c37b66a9852878474d3b8ccfc6a08f.png)
- 然后,我们对Format.py中的文件进行适当修改。原因是,该代码生成的格式是将每一幅图像的标注单独写成一个txt文件,而我采用的训练模型接受的标注文件格式与之不同,修改内容如下:
- 在Format.py中的YOLO类中添加如下两个成员函数:
def generate_v1(self, data):
try:
progress_length =len(data)
progress_cnt = 0
printProgressBar(0, progress_length, prefix='\nYOLO Generating:'.ljust(15), suffix='Complete', length=40)
result = {}
for key in data:
img_width = int(data[key]["size"]["width"])
img_height = int(data[key]["size"]["height"])
contents = ""
for idx in range(0, int(data[key]["objects"]["num_obj"])):
xmin = data[key]["objects"][str(idx)]["bndbox"]["xmin"]
ymin = data[key]["objects"][str(idx)]["bndbox"]["ymin"]
xmax = data[key]["objects"][str(idx)]["bndbox"]["xmax"]
ymax = data[key]["objects"][str(idx)]["bndbox"]["ymax"]
b = [xmin, ymin, xmax, ymax]
cls_id = self.cls_list.index(data[key]["objects"][str(idx)]["name"])
bndbox = "".join(["".join([str(e), ","]) for e in b])
contents = "".join([contents, " ", bndbox[:-1], ",", str(cls_id)])
result[key] = contents
printProgressBar(progress_cnt + 1, progress_length, prefix='YOLO Generating:'.ljust(15),
suffix='Complete',
length=40)
progress_cnt += 1
return True, result
except Exception as e:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
msg = "ERROR : {}, moreInfo : {}\t{}\t{}".format(e, exc_type, fname, exc_tb.tb_lineno)
return False, msg
def save_v1(self, data, save_path, img_path, img_type, manipast_path):
try:
progress_length = len(data)
progress_cnt = 0
printProgressBar(0, progress_length, prefix='\nYOLO Saving:'.ljust(15), suffix='Complete', length=40)
with open(manipast_path, "w") as manipast_file:
for key in data:
# manipast_file.write(os.path.abspath(os.path.join(img_path, "".join([key, img_type, "\n"]))))
key_path = "".join(["DeepFashion2/train/image/", key, img_type])
# with open(os.path.abspath(os.path.join(save_path, "".join([key, ".txt"]))), "w") as output_txt_file:
manipast_file.write("".join([key_path, " ", data[key], "\n"]))
printProgressBar(progress_cnt + 1, progress_length, prefix='YOLO Saving:'.ljust(15),
suffix='Complete',
length=40)
progress_cnt += 1
return True, None
except Exception as e:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
msg = "ERROR : {}, moreInfo : {}\t{}\t{}".format(e, exc_type, fname, exc_tb.tb_lineno)
return False, msg
- 将example.py的第58行、第61行的yolo.generate,yolo.save分别改成yolo.generate_v1和yolo.save_v1.
-
接着,在控制台运行如下指令:
(1) 生成训练集标签
python example.py --datasets COCO --img_path ./train/image/ --label train.json --convert_output_path YOLO/ --img_type ".jpg" --manipast_path train.txt --cls_list_file fashion_classes.txt
(2) 生成验证集标签
python example.py --datasets COCO --img_path ./validation/image/ --label valid.json --convert_output_path YOLO/ --img_type ".jpg" --manipast_path valid.txt --cls_list_file fashion_classes.txt
完成上述两个步骤后,会在当前文件夹生成"train.txt" 和“valid.txt"两个我们需要的标注文件,其标注格式为,如下图示例:
img_path xmin,ymin,xmax,ymax,cls_id1 xmin,ymin,xmax,ymax,cls_id2

其中,img_path为图片的路径,使用时可以通过修改 save_v1函数中”key_path = “”.join([“DeepFashion2/train/image/”, key, img_type])“里面的代码,将其改为你电脑上的绝对路径,然后只需要将两个标注文件放到项目路径下面。否则,你也需要将整个数据集按照如下结构组织,并放到项目路径下面:
- DeepFashion2
- train
- image
- validation
- image
3 使用YOLOv4模型进行训练
我用的是这个仓库下的代码https://github.com/bubbliiiing/yolov4-pytorch,这份实现包含了一些训练的tricks,比如Cosine scheduler learning rate,Mosaic,CutMix,label smoothing,CIoU等。
-
将刚刚生成好的数据标签文件train.txt和valid.txt放到项目的根目录下面(如果你的标注文件里面的文件路径采用的不是绝对路径,还需要把数据集的图像按照第二章所说的目录结构拷贝过来)。
-
项目原来的代码是将训练集中划出一定比例作为验证集,由于我们有验证集的标注,所以适当的修改代码。适当修改train_with_tensorboard.py 中的代码:
[line 142]:
- annotation_path = '2007_train.txt'
+ train_path = 'train.txt'
+ val_path = 'valid.txt'
[line 179]:
- val_split = 0.1
- with open(annotation_path) as f:
- lines = f.readlines()
- np.random.seed(10101)
- np.random.shuffle(lines)
- np.random.seed(None)
- num_val = int(len(lines)*val_split)
- num_train = len(lines) - num_val
+ with open(train_path) as f:
+ train_lines = f.readlines()
+ with open(val_path) as f1:
+ val_lines = f1.readlines()
+ np.random.seed(10101)
+ np.random.shuffle(train_lines)
+ np.random.shuffle(val_lines)
+ np.random.seed(None)
+ num_train = int(len(train_lines))
+ num_val = int(len(val_lines))
[line 208, line 245]:
- train_dataset = YoloDataset(lines[:num_train], (input_shape[0], input_shape[1]), mosaic=mosaic)
- val_dataset = YoloDataset(lines[num_train:], (input_shape[0], input_shape[1]), mosaic=False)
+ train_dataset = YoloDataset(train_lines, (input_shape[0], input_shape[1]), mosaic=mosaic)
+ val_dataset = YoloDataset(val_lines, (input_shape[0], input_shape[1]), mosaic=False)
[line 215, line 252]:
- gen = Generator(Batch_size, lines[:num_train], (input_shape[0], input_shape[1])).generate(mosaic = mosaic)
- gen_val = Generator(Batch_size, lines[num_train:], (input_shape[0], input_shape[1])).generate(mosaic = False)
+ gen = Generator(Batch_size, train_lines, (input_shape[0], input_shape[1])).generate(mosaic = mosaic)
+ gen = Generator(Batch_size, train_lines, (input_shape[0], input_shape[1])).generate(mosaic = mosaic)
然后,按照项目的说明文档操作即可。 我这次的训练由于GPU资源不能长时间使用,训练过程没结束就被终止了,结果不是特别好,VOC mAP评价指标如下图所示:
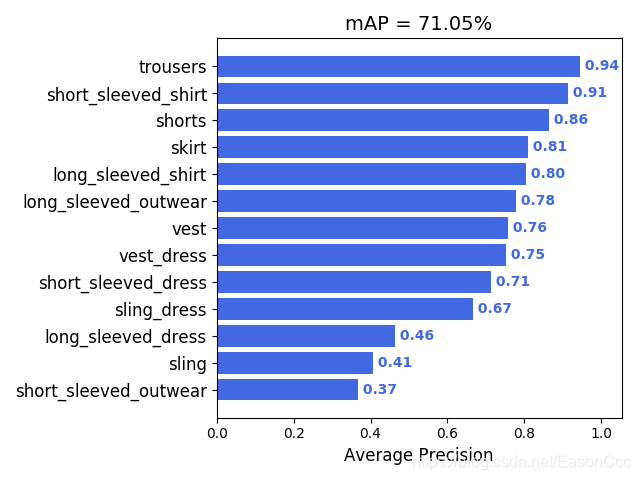
但是,跑开指标不谈,这个数据集还是训练出了泛化能力不错的模型,下面给出几幅该模型的预测结果图像:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P2x3XyFg-1606804433293)(C:\Users\Eason_Cai\Desktop\df1.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/e89a3ba25a9a2f6cb30da24ae42aa830.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1EUEZwqL-1606804433295)(C:\Users\Eason_Cai\Desktop\df2.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/3ef387ebc33d0413d375647e952623be.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P39B54cI-1606804433296)(C:\Users\Eason_Cai\Desktop\df3.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/09a30fd6f3247e2dca8ca6a6fb9a1a51.png)
4 Reference
https://arxiv.org/abs/1901.07973
https://github.com/switchablenorms/DeepFashion2
https://github.com/Manishsinghrajput98/A-Z-Deepfashion2-Impleamentation
https://github.com/Manishsinghrajput98/deepfashion2coco_to_yolo_
https://github.com/bubbliiiing/yolov4-pytorch



















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











