







基本特点
- 主从集群结构相对简单,主与从协作
- 主:单点,数据一致好掌握
- 缺点:单点故障,集群整体不可用;压力过大,内存受限
- 解决方案:
- 单点故障:
高可用方案HA(High Available):
多个NN,主备切换 —— 即当NameNode故障后,其备用的服务器会替换姑臧的服务器,作为主NameNode
(HADOOP 2.x只支持HA的一主一备) - 主压力过大,内存受限:
联邦机制Federation(元数据分片):
多个NN,管理不同的元数据
注意:单点故障和压力过大是两个不同的问题,需要分开思考。
HDFS-HA解决方案

-
client只会与一个NameNode交互,即NN Active。当NN Active出现故障后,client会自动与NN Standby交互,client无感。
-
Name Node存储信息:client操作,写入的元数据;DataNode向NameNode汇报block信息。
-
存在问题:
1)NN Standby获取DataNode block数据 —— DataNode向NN Standby汇报block信息
2)client切换NN,如何保证元数据满足数据一致性 —— 同步机制。
同步机制涉及到同步模式:
若采用阻塞机制,保证数据强一致性,将会导致client在一定时间内无法可用,破坏可用性。
若采用异步模型,client进行操作后,NN Active将操作发送给NN Standby,不等待NN Standby返回结果,直接返回给client,破坏一致性。
折中处理:选择可靠的Node,让NN Active发送给该Node,再由该Node发送给NN Standby,达到最终一致性。因此,增加了一群Node,如图所示JN(Journal Node)。当一半以上的Node都返回了ok给NN Active,则认为写入成功,NN Active将返回ok给client。当NN Standby读取的时候,也采用过半方案,则一定能读取到最新 的数据,保证了最终一致性。 -
CAP原则:
1)Consistency:一致性
2)Availability:可用性
3)Partition tolerance: 分区容忍性(由于网络不稳定,所以当部分节点不可用的时候,功能可用)
这三个原则难以同时满足;CA:关系型数据库;CP:radis,mongodb等 -
采用Paxos算法保证数据一致性,Paxos是一种基于消息传递的一致性算法。一般每种技术都会根据自己技术对其进行简化算法实现。
-
简化思路:
1)分布式节点是否明确:是否每个节点都知道其他节点
2)节点权重是否明确:占比和前提条件
3)强一致性破坏可用性,过半通过可以中和一致性和可用性
4)最简单的自我协调实现:主从(在Node节点群中选择出主从)
主的选举:明确节点数量和权重。
主从职能:主:增删改查; 从:查询,增删改传递给主; -
利用zookeeper实现选主的操作,当NN故障后,自动更换到NN Standby
选主
- zookeeper
- 其是目录树结构,存在一个抢锁操作
- 某个节点抢到锁后,其将作为主(NN Active)
- 当节点故障后,触发回调机制,重新触发抢锁操作。
- 当FailloverController Active该进程与zk通信失败,也会触发释放锁操作。
- FailloverController Active
- 是一个进程,和NN处于同一个物理机(若不在同一物理机,受到网络印象,网络不可靠),三个作用:
1)监控NN Active
2)与zookeeper交互
3)当NN Active故障后,zookeeper选择出新的主后,其会向原NN Active交互,查看其是否工作正常。 - 若原NN Active确实故障,则新主将变为新NN Active;
- 若NN Active仍旧正常工作,但FailloverController Active挂掉了,则会将NN Active降级,将新主从NN Standby升级为NN Active。
- 若NN Active仍旧正常工作,且FailloverController Active也正常工作,但FailloverController Active与ZK突然断开连接,但新主NN Standby无法与原NN Active交互了,该现象概率极低,且不和常理。补救方式:利用串口,直接将对方NN Active断电,并升级自身为Active
总结:
HA方案:
- 多台NN主备模式,Active和Standby状态
- 增加 Journal Node
- 增加哦zkfc角色(与NN同台),通过zookeeper集群协调NN主从
- HA模式中没有SNN角色,NN Standby将取代SNN角色的工作;同时注意,NN Standby是实时同步变化数据,而SNN是间隔时间去取。非HA模式,都存在SNN这个角色。
Journal Node
Federation解决方案
- NN压力过大,内存受限问题:
1)元数据分治,复用DN存储

2)元数据访问隔离性 —— 某个元数据只在一个NN中,其他NN无法查询到;不同的NN可以存储相同的文件,该文件会放到不同的block中。

- 需要注意的是,一般来说使用多台NN的时候,直接指定部分用户使用一个NN,另一部分用户使用另一个NN…由此实现了NN的隔离,不同client的隔离。降低了内存的占用。
- 如下图所示: client a只能访问NNa,只能看到Filex的数据。但不能看到Filey的所有文件(增删改查都不行)

- 若需要可以共享文件,则增加一层抽象层,如图所示:

此时,client访问的时候,只需要去查看a和b即可看到所有的文件。甚至可以访问FTP等其他类型的FS。
3)DN目录隔离block。
HA模式搭建
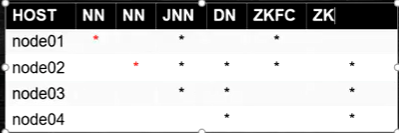
- 角色分配:zookeeper集群,zkfc(也就是监控NN的进程),NN,DN,JN集群
*
- 配置文件
- 修改NameNode配置,将原先的主机名和端口号改成一个别名,并定义别名,实现逻辑的一对多以及逻辑和物理的映射关系
core-site.xml
<property>
<name>fs.defaultFs</name>
<value>hdfs://mycluster</value>
</property>
hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:5007</value>
</property>
- 配置journal node,hdfs-site.xml中
包含journode启动位置以及jourNode数据存储位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdatahadoop/ha/dfs/jn</value>
</property>
- 免密配置
- zkfc,用于和NN以及远端NN执行操作
- 管理脚本,用于启动hdfs
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfigureFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>/sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
exampleuser: 根据当前的user进行更换,比如换成/root/.ssh/id_dsa
4. zk和zkfc配置
core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181;node03:2181;node04:2181</value>
</property>
hdfs-site.xml文件
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
命令:格式化zookeeper, hdfs zkfc -formatZK
- 部署细节
- 在完成配置后,必须开启JournalNode daemouns,执行命令
hadoop-daemon.sh start journalnode—— 这是由于HA模式下,元数据不仅存放在本地,还存放在其他节点,所以必须先启动JN,再去格式化NN,不然格式化NN后,又会从其它节点拉取元数据。需要注意的是,只能在一台服务器中执行NN格式化。其它服务器只需要同步。
- 流程
1)基础设施
ssh免密:
- 启动start-dfs.sh脚本的机器需要将公钥分发给别的节点;
- 在HA模式下,每个NN会伴随这ZKFC启动,ZKFC会用免密的方式控制自己与其他NN节点的状态
2)应用搭建 - HA以来ZK,搭建ZK集群
- 修改hadoop配置文件,并集群同步
3)初始化启动 - 启动JN
hadoop-deamon.sh start journalnode - 选择一个NN做格式化
hdfs namenode -format - 启动格式化的NN
hadoop-daemon.sh start namenode - 在另一台机器中
hdfs namenode -bootstrapStandby - 格式化zk
hdfs zkfc -formatZK start-dfs.sh















 4068
4068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









