目录
1.文件系统中的缓冲区
2.buffer和cache有何不同
3.Buffer Cache VS Page Cache
4.Dentry Cache VS Inode Cache
5.打开文件到底做了什么
5.1 引入
5.2 查找过程概述
6.Buffer Cache技术
6.1引入
6.2 buffer cache 头数据结构
6.3 ext2文件系统超级块的组织形式
6.4内核如何从磁盘中获取inode信息-源码
7.小结,参考资料和思考问题
1.文件系统中的缓冲区
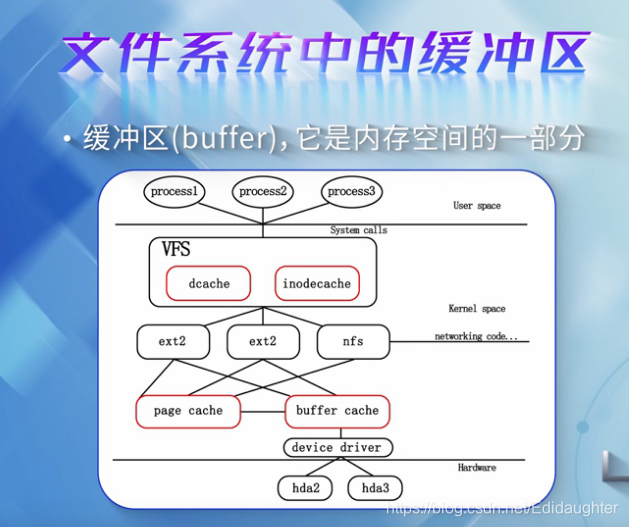
缓冲区是内存空间的一部分,也就是说在内存空间中预留了一定的存储空间,
这些存储空间用来缓冲输入或者输出的数据,这部分预留的空间就叫做缓冲区.
如图中的红色框,在整个文件系统中,有四种类型的缓冲区,
(1)dcache
(2)inodecache
(3)page cache
(4)buffer cache
2.buffer和cache有何不同
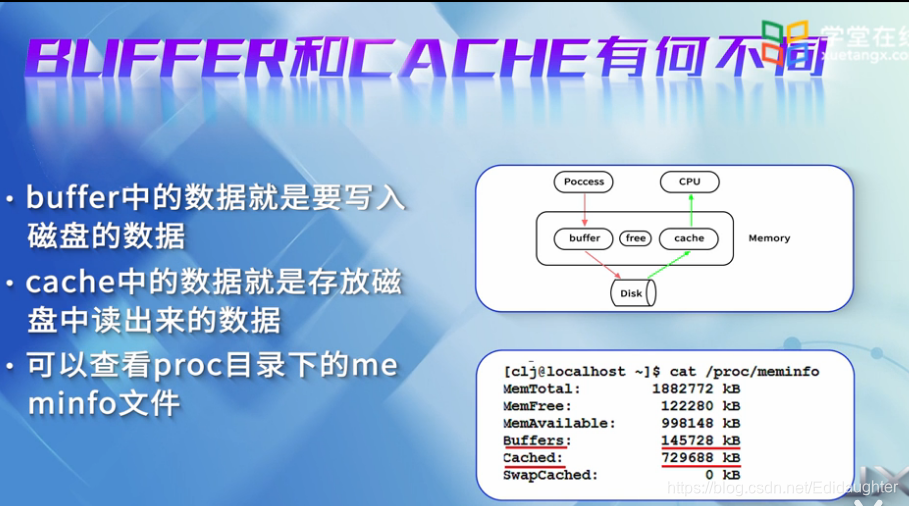
BUFFER是内存中的缓冲区,是各个进程产生的文件临时存储区,在一定的时间内
会统一写到磁盘,减少磁盘的碎片或者磁盘的反复寻道,从而提高系统性能.
简单来说,buffer中的数据就是要写入磁盘的数据.
CACHE也是内存的缓冲区,经常被用在磁盘的I/O请求上,如果有文件被频繁地访
问到,系统会将文件缓存在CACHE上,共CPU进程来访问,简单来说,CACHE中的数
据就是存放磁盘中读出来的数据.
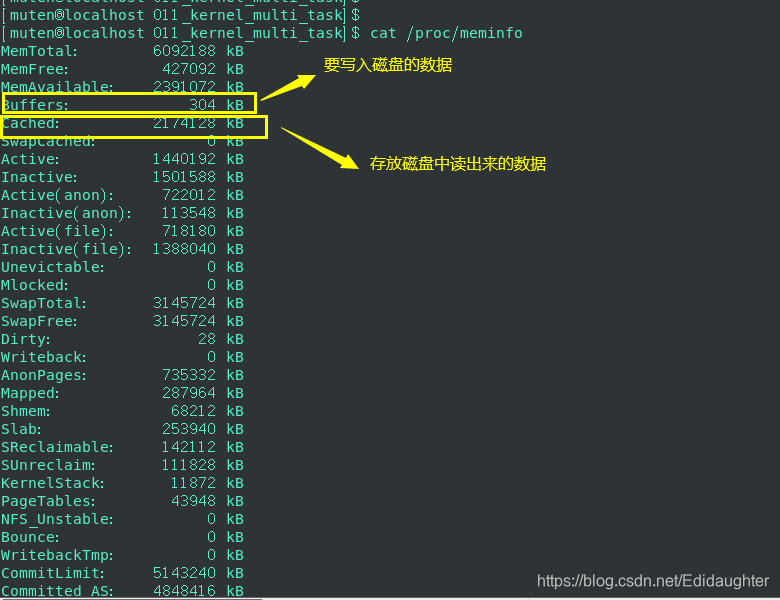
在机器上可以通过cat /proc/meminfo查看Buffer和Cache的大小.
3.Buffer Cache VS Page Cache
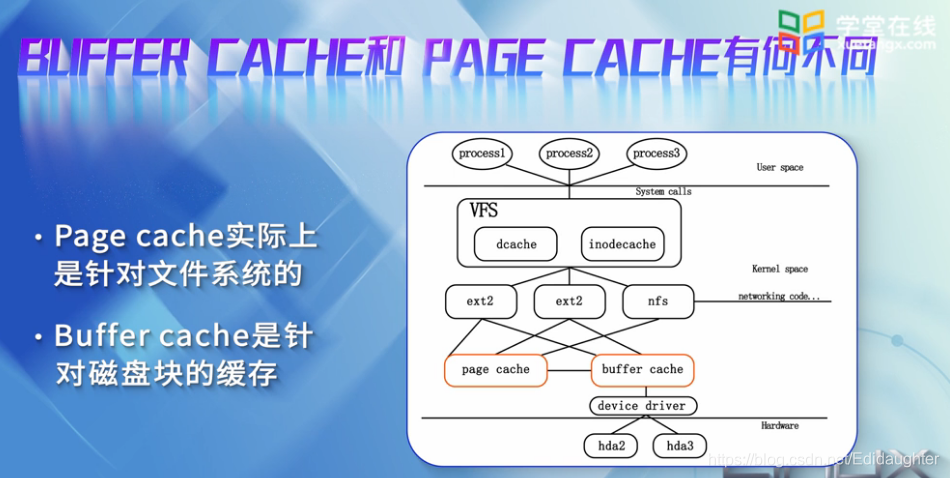
Page Cache
实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到Page Cache中.
文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成,当Page Cache
的数据需要刷新时,Page Cache的数据就会交给Buffer Cache.
Buffer Cache
是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接操作的数据会缓存到Buffer
Cache中,例如文件系统中的元数据会缓存到Buffer Cache中.
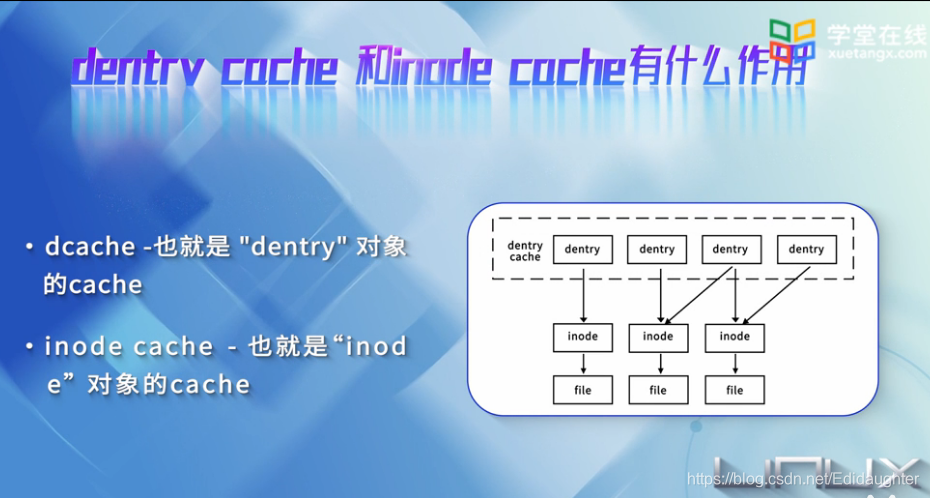
4.Dentry Cache VS Inode Cache
5.打开文件到底做了什么
5.1 引入
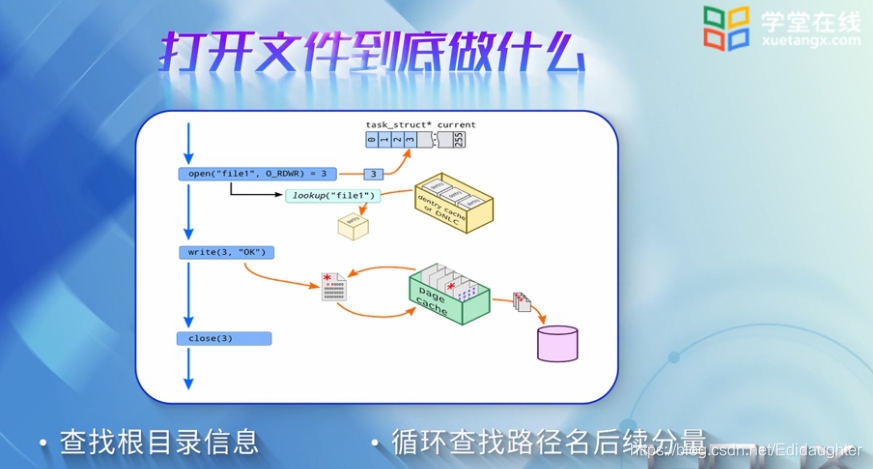
打开文件到底做了什么,它和我们说的缓冲有什么样的关系呢?
打开文件的核心是查找,通常内核将查找过程分为两部分:
第一部分是查找根目录的系统,主要是判断目录是系统根目录还是当前工作目录,
以获取后序循环查找的起始位置,这里的位置是指具体的文件系统挂载的位置以及
从哪个目录开始.
第二部分是循环查找路径名后序分量,以起始位置开始,循环查找后序的每个分量.
5.2 查找过程概述
查找过程看起来很简单,但实际上内核实现还是比较复杂的,涉及到众多的cache技术.查找的关键接口
为do_lookup,其主要过程如下:
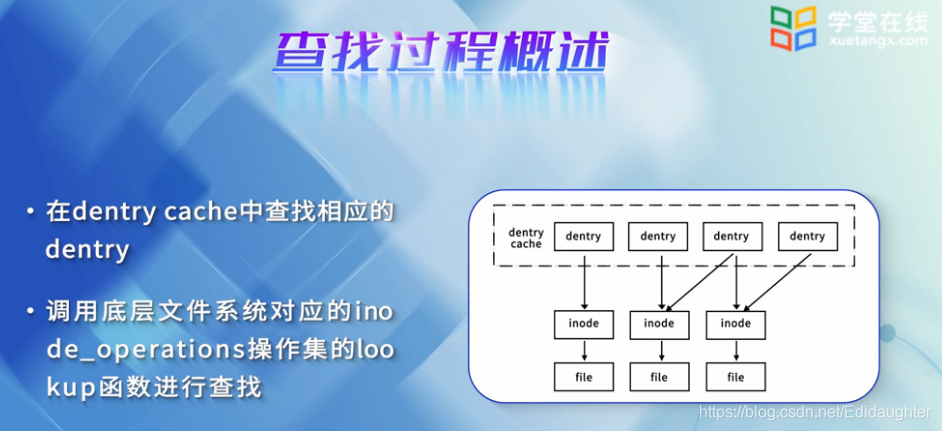
对于dentry的查找:
在dentry cache中查找相应的dentry,若找到则直接返回;若没有找到,则必须去底层文件系统中查找对应
的dentry,调用底层文件系统中对应的inode_operations操作集的lookup函数进行查找.
对于inode的查找:
首先在inodecache中查找时是否存在对应的inode,如果有,则返回,如果没有则必须去更底层的磁盘查找对应的inode信息.
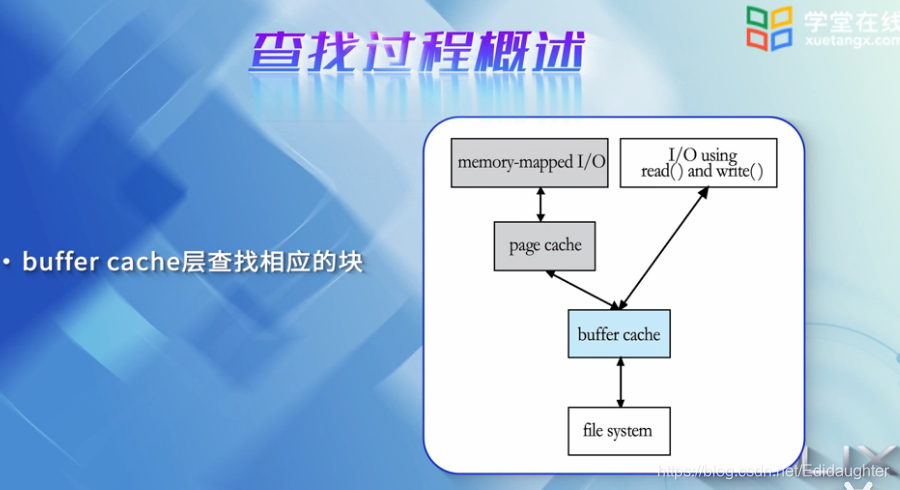
去磁盘查找inode信息的时候,首先去buffer cache层查找相应的块,如果有相应的块存在,则从相应的
buffer cache中提取inode信息,并将其转换成对应文件系统的inode结构.
目录项缓存的组织和查找:
由于块设备速度比较慢,可能需要很长时间才能找到与一个文件名关联的inode信息,所以要引入dentry
cache.
目录项缓存的组织包括:
一个散列表,它包含了所有活动的dentry对象,散列表由dentry哈希表组成,
dentry通过d_hash字段链接入哈希表中.
一个LRU链表,dentry结构中由d_lrt链表组织.
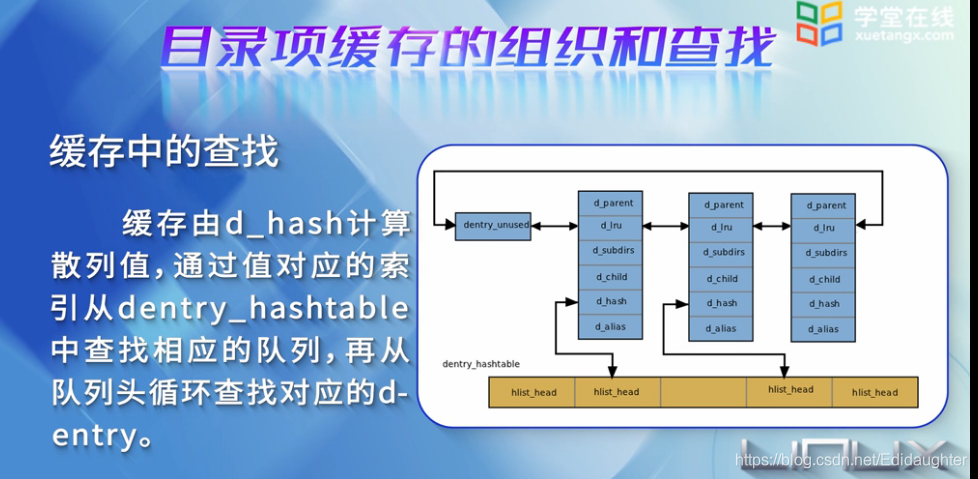
缓存中的查找:
缓存有d_hash计算散列值,通过值对应的索引从dentry_hashtable中查找响应的队列,再从队列头循环
查找对应的dentry.也就是先从哈希表中查找,再从lru链表中查找.
问题:这里不太懂啊,为什么要找到队列??这里不是一个个的dentry节点组成的链表吗?为什么会
有队列?直接通过dentry_hashtable中查找响应的dentry对象不就好了吗?为什么还要从队列里循环
查找对应的dentry?这个到底是怎么组织的呢?这里的队列是指dentry对象的意思吗?
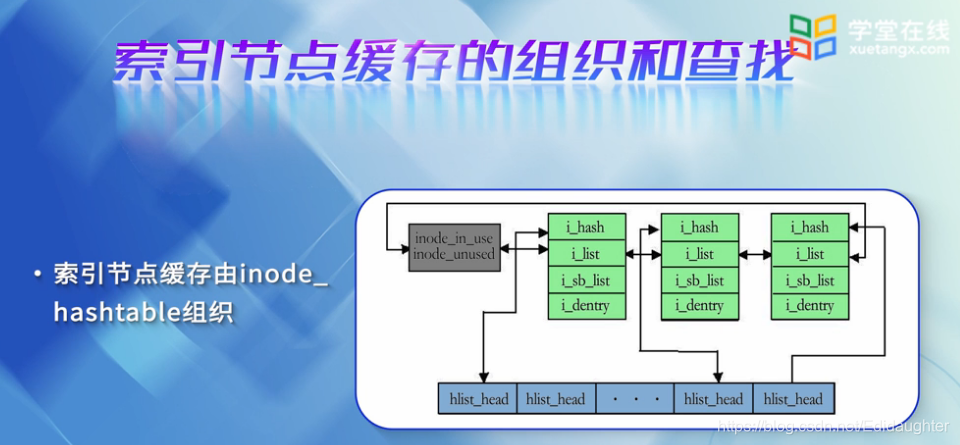
索引节点缓存的组织与查找:
同样为了加速查找,引入了索引节点缓存,也就是inodeCache,索引节点缓存由inodehashtable组织,如上图.
6.Buffer Cache技术
6.1引入
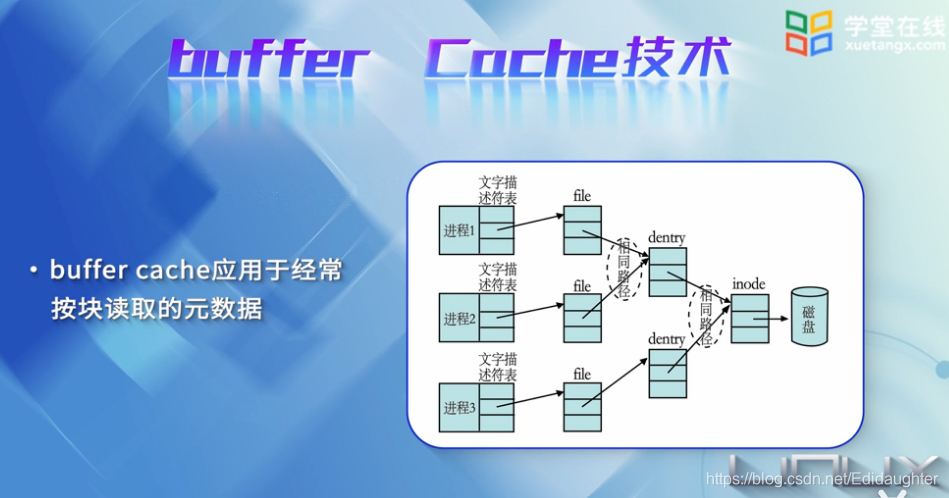
如果要查找的inode不在inode cache中,此时就要从磁盘中读取数据了,此时就涉及到buffer cache技术.
buffer cache技术应用于经常按块读取的元数据,例如在查找的过程中,为了获取inode的信息,需要首先
从磁盘读取super_block的信息.
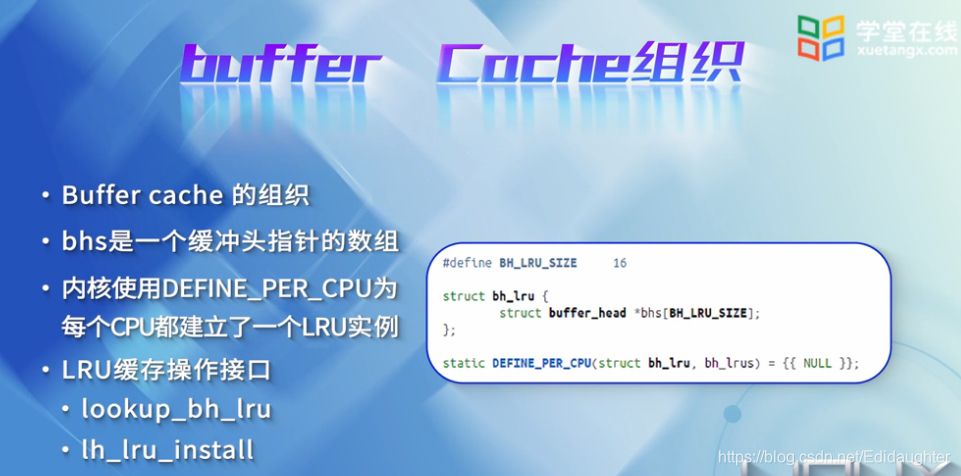
buffer cache的组织:
它的组织采用LRU链表,上图是源码的截图.
bhs是一个缓冲头指针的数组,是用作实现LRU算法的基础,内核使用DEFINE_PER_CPU为每一个CPU都建立了
一个LRU实例以改进对CPU高速缓存的利用率.
LRU缓存操作接口,此处给出两个:
1.lookup_bh_lru--查找所需数据项是否在块缓存中;
2.lh_lru_install--将新的缓冲头添加到缓冲中.
6.2 buffer cache 头数据结构

6.3 ext2文件系统超级块的组织形式
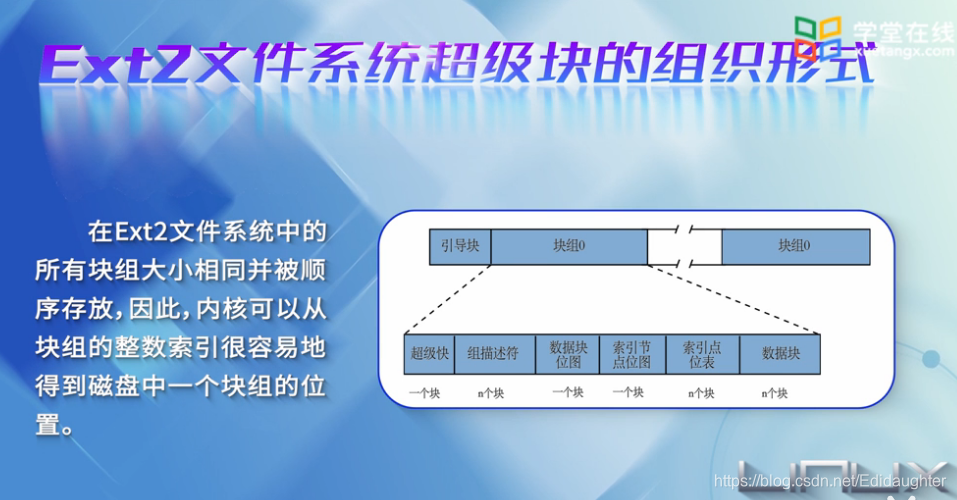
任何一个ext2分区中的第一个块不受ext2文件系统的管理,因为这块是由分区的引导扇区所
保留的,ext2的其余部分被分成块组blockgroup.
6.4内核如何从磁盘中获取inode信息-源码
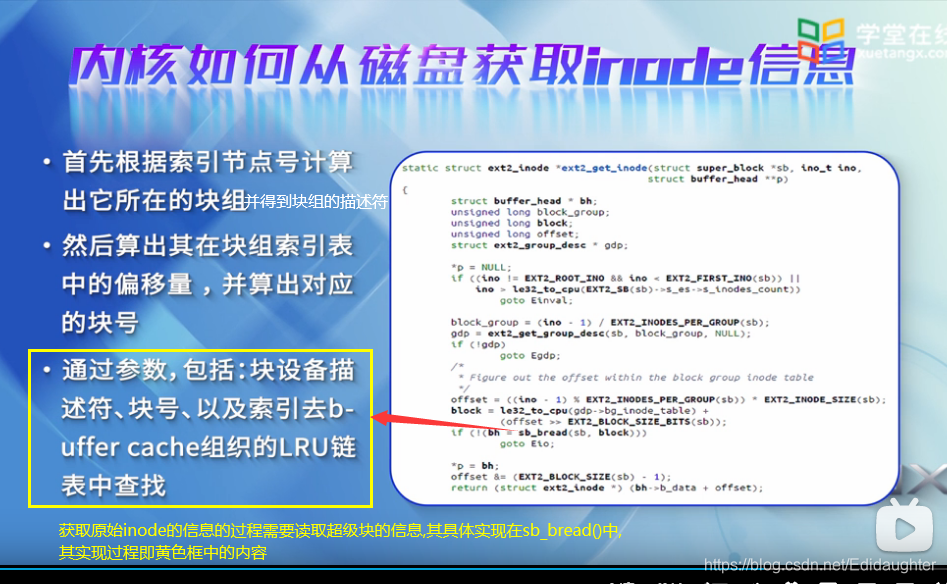
通过参数,包括块设备描述符,块号以及索引去block cache组织的LRU链表中查找.
如果缓冲区首部都在LUR块高速缓存中,则返回对应的buffer head类型的缓冲区
首部.如果不在,则需要去页高速缓冲中查找,看是不是在页高速缓冲中,如果存在
则返回页高速缓存中对应的块缓冲区所对应的缓冲区的首部.这里仅仅对基于缓冲
区的查找过程给一个简单的介绍.
7.小结,参考资料和思考问题
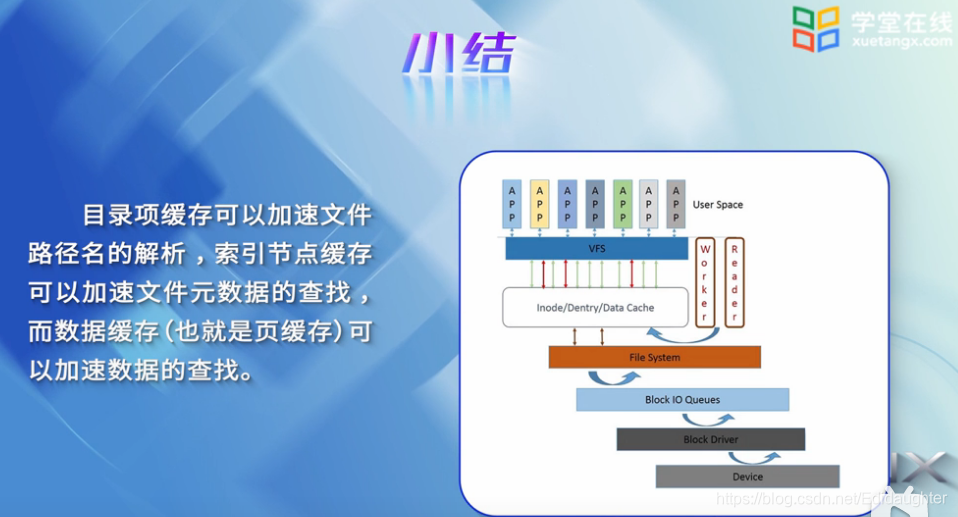
目录项缓存可以加速文件路径名的解析;
索引节点缓存考科一加速文件元数据的查找;
数据缓存(页缓存)可以加速数据的查找.
这些数据通过文件系统传递给块的IO层,然后封装成IO请求给驱动程序,驱动程序最终从设备上读取数据,
这方面相关的内容将在块设备这一节中进行具体的讲解.










 本文详细介绍了文件系统中的缓存机制,包括目录项缓存、索引节点缓存及数据缓存等关键技术,并探讨了它们如何加速文件路径名解析、元数据查找及数据查找的过程。
本文详细介绍了文件系统中的缓存机制,包括目录项缓存、索引节点缓存及数据缓存等关键技术,并探讨了它们如何加速文件路径名解析、元数据查找及数据查找的过程。

















 4661
4661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









