







 本文详细梳理了Alexa Voice Service (AVS) SDK的代码流程,适合熟悉C/C++和Linux环境的读者。内容包括AVS SDK的框架组成、音频处理、唤醒词引擎、ACL与ADSL交互、Capability Agents以及认证过程。重点讨论了音频输入输出、回音消除、唤醒词适配和CA认证的移植要点。
本文详细梳理了Alexa Voice Service (AVS) SDK的代码流程,适合熟悉C/C++和Linux环境的读者。内容包括AVS SDK的框架组成、音频处理、唤醒词引擎、ACL与ADSL交互、Capability Agents以及认证过程。重点讨论了音频输入输出、回音消除、唤醒词适配和CA认证的移植要点。
1)本章主要讲解Amazon的AVS SDK框架代码流程说明,其他SOC厂商(MTK/海思/Mstar/Amlogic/SigmaStar/全志/RockChip平台)移植AVS的要点。分享给将要学习或者正在学习AVS的同学。
2)适用于对C/C++语言有基本的认识,以及对Linux环境有基本的掌握能力。
3)内容属于原创,若转载,请说明出处。
4)本人提供相关问题有偿答疑和技术支持。笔者曾经基于Amlogic/MTK/Rockchip等平台做过完整的方案,后面会说明如何认证的过程。
AVS简称(Alexa Voice Service)
AVS SDK官方源码地址https://github.com/alexa/avs-device-sdk
AVS SDK源码使用标准的C++14的语言编写,截至笔者写此文章,目前最新的版本是1.19.1
运行或者开发AVS的必备事项:
(a) 需要到Amazon官网申请注册一个免费的开发者账户
(b) 在开发者账户中创建设备类型等参数
(c) 将设备类型的clientId、productId、manufacturerName等信息写入到配置文件AlexaClientSDKConfig.json对应的参数中
(d) AVS运行需要认证,目前支持3种认证方式,常用的是CBL认证和CA认证方式,其中CBL是设备本身SDK自带认证方式,使用比较简单,运行期间可以直接认证;CA认证方式需要自己开发,同时需要APP端配合来完成,此文章基于amlogic的AVS音箱方案就是使用我们自己开发的CA认证方式
基本软件架构组成:
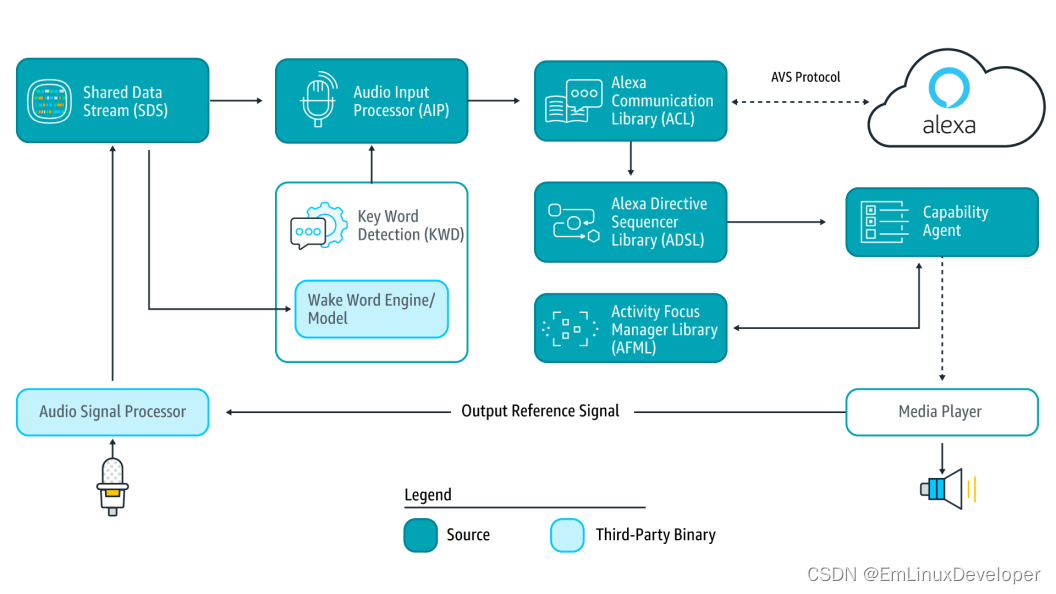
上面框架各个部分对应如下:
(1) Audio Input Processor (AIP) 用于处理音频数据,如麦克风输入的数据以及唤醒数据等
(2) Shared Data Stream (SDS) 用于缓存音频数据,实际是一个共享的ringbuffer
(3) Alexa Communication Library (ACL) 用于和Amazon服务端做数据或信息交互,使用http与服务端通信
(4) Alexa Directive Sequencer Library (ADSL) 用于分发Amazon服务下发的信息或者是数据
(5) Activity Focus Manager Library (AFML) 用于各种状态的监听以及管理等
(6) Capability Agent 执行一些命令或者控制等动作代理
(7) Audio Signal Processer (ASP) 用于音频数据的收集以及AEC的处理等
(8) Wake Word Engine (WWE) 用于监听系统唤醒等动作
(9) Media Player 用于播放系统各种音频等
因此,从上图中可以看到移植的重点是第三方的组件部分,即:音频Mic的数据采集,以及speaker数据的播放,以及回音消除(AEC),唤醒词(wake word)的适配等。外加前面说的CA认证。
从官方的github中获取一套完整的代码目录如下,上面的框架对应于下面的目录:(git clone https://github.com/alexa/avs-device-sdk.git)

对于AVS前端音频输入部分采用开源第三方PortAudio工具来捕获麦克风数据,对应的接口位置:PortAudioMicrophoneWrapper.h
下面详细分析一下对应的接口:
err = Pa_OpenDefaultStream(
&m_paStream,
NUM_INPUT_CHANNELS, //这里初始化麦克风输入的通道数目
NUM_OUTPUT_CHANNELS,
paInt16, // 初始化采样深度
SAMPLE_RATE, //初始化采样率
PREFERRED_SAMPLES_PER_CALLBACK,
PortAudioCallback, //注册回调,此回调会在音频捕获完毕以后回调
this);下面是回调函数:
int PortAudioMicrophoneWrapper::PortAudioCallback(
const void* inputBuffer,
void* outputBuffer,
unsigned long numSamples,
const PaStreamCallbackTimeInfo* timeInfo,
PaStreamCallbackFlags statusFlags,
void* userData) {
PortAudioMicrophoneWrapper* wrapper = static_cast<PortAudioMicrophoneWrapper*>(userData);
ssize_t returnCode = wrapper->m_writer->write(inputBuffer, numSamples); //在回调函数中将音频数据写入到SDS,注意这部分数据在实际应用中需要经过算法处理降噪
if (returnCode <= 0) {
ACSDK_CRITICAL(LX("Failed to write to stream."));
return paAbort;
}
return paContinue;
}算法降噪处理通常是使用第三方提供,国内有科大讯飞,通用微,地平线等等算法,代码位置是:AvsAudioInputStreamPort.cpp
bool AvsAudioInputStreamPort::initialize() { //算法初始化部分
...................
w32Ret = ALGO_Init(...);
w32Ret = ALGO_SetParams(...);
...................
}
bool AvsAudioInputStreamPort::rawDataWrite() {
................... //算法处理音频数据API
ALGO_OneFrame(pALGO_Object,
(W16*)(&kRawBuffer[BufferDefault->GetFrameCount() * (DEFAULT_MIC_PRE_CHANNEL-1)]), //两路或者是四路mic数据
(W16*)(&kRawBuffer[0]), //一路AEC数据
(W16*)(&kAsrBuffer[0]), //降噪后输出的3路信号,实际使用前两路用于ASR和唤醒,第3路保留
&tALGO_ClearStat);
.................
returnCode = m_writerWkp0->write(Wkp0AudioDataOut.data(), Wkp0AudioDataOut.size()); //双唤醒,将算法处理后的第一路数据写到SDS
if (returnCode <= 0) {
ConsolePrinter::prettyPrint("Failed to write to stream.");
return false;
}
returnCode = m_writerWkp1->write(Wkp1AudioDataOut.data(), Wkp1AudioDataOut.size());//双唤醒,将算法处理后的另外一路数据写到SDS
if (returnCode <= 0) {
ConsolePrinter::prettyPrint("Failed to write to stream.");
return false;
}
.................
}以上有的平台支持双路唤醒,实际一路即可,以上是完成了Audio输入的数据到SDS也即是(Audio Signal Processor框图中完成的部分);
从上图架构中可以看出SDS中的数据分两部分流到下一级,一路流到AIP部分。另外一部分流入到KWD。
下面先看一下AIP和KWD的初始化代码,代码位置:SampleApplication.cpp
bool SampleApplication::initialize( // 初始化接口
std::shared_ptr<alexaClientSDK::sampleApp::ConsoleReader> consoleReader,
const std::vector<std::string>& configFiles,
const std::string& pathToInputFolder,
const std::string& logLevel,
const std::string& runMode) {
............................
size_t bufferSizeWkp0 = alexaClientSDK::avsCommon::avs::AudioInputStream::calculateBufferSize(
BUFFER_SIZE_IN_SAMPLES, WORD_SIZE, MAX_READERS);
auto bufferWkp0 = std::make_shared<alexaClientSDK::avsCommon::avs::AudioInputStream::Buffer>(bufferSizeWkp0);
std::shared_ptr<alexaClientSDK::avsCommon::avs::AudioInputStream> sharedWkp0Stream = //分配用于第一路SDS的buffer
alexaClientSDK::avsCommon::avs::AudioInputStream::create(bufferWkp0, WORD_SIZE,MAX_READERS);
if (!sharedWkp0Stream) {
ACSDK_CRITICAL(LX("Failed to create shared data stream!"));
return false;
}
size_t bufferSizeWkp1 = alexaClientSDK::avsCommon::avs::AudioInputStream::calculateBufferSize(
BUFFER_SIZE_IN_SAMPLES, WORD_SIZE, MAX_READERS);
auto bufferWkp1 = std::make_shared<alexaClientSDK::avsCommon::avs::AudioInputStream::Buffer>(bufferSizeWkp1);
std::shared_ptr<alexaClientSDK::avsCommon::avs::AudioInputStream> sharedWkp1Stream = //分配用于第二路SDS的buffer
alexaClientSDK::avsCommon::avs::AudioInputStream::create(bufferWkp1, WORD_SIZE, MAX_READERS);
if (!sharedWkp1Stream) {
ACSDK_CRITICAL(LX("Failed to create shared data stream!"));
return false;
}
..............................
alexaClientSDK::capabilityAgents::aip::AudioProvider tapToTalkAudioProvider(
sharedWkp0Stream,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









