







网上很多博客写得模模糊糊的,对我这个新手可是一点都不友好。
昨天一天都在研究这个东西,分享一下自己的拙见。
百度搜“WQS二分”的第一篇,搜“WQS的一个细节及证明”的第一篇质量还是可以的,用来大致理解和细节理解,本文前部分借鉴了上述两篇博客。
我这个就是实战理解吧。。。
应用分析
WQS \text{WQS} WQS 二分通常用来解决下面这类问题:
给定若干 n n n 个物品,要求从中恰好选 m m m 次,最大化 / 最小化 选的物品权值和。
使用条件:
- 设 g ( i ) g(i) g(i) 选 i i i 个物品的最优答案,将所有 ( i , g ( i ) ) (i,g(i)) (i,g(i)) 的点画出来,必须组成一个 凸包 (上凸包、下凸包均可)。
因为是凸包,对应性质为斜率 递增 / 递减。
这种题目往往有下列特点:
- 如果不限制选的个数,那么很容易求出最优方案。(所以一般用来优化 d p dp dp)
- 选的物品越多,权值越 大 / 小。
判断能否使用的方法:
- 打表看 ( i , g ( i ) ) (i,g(i)) (i,g(i)) 拟合出的图形是凸包。
- 满足两个特点。
常用第二种方法,感性理解。感觉可以用 WQS \text{WQS} WQS 二分,那就大胆用 WQS \text{WQS} WQS 二分。
综上。
判断能否使用 WQS \text{WQS} WQS 二分的流程:
题目能转化成: 一共有 n n n 个数,要求刚好选 m m m 次,有某种限制,以某种方式计算每次选的物品的某个属性和,选多少次以及怎么选都会影响到答案。
然后能设 d p ( i , j ) : dp(i,j): dp(i,j): 到 i i i 为止,选了 j j j 次的最优答案。
然后有转移: d p ( i , j ) = max / min ( d p ( k , j − 1 ) + c o s t ( k , i ) ) dp(i,j)=\max/\min(dp(k,j-1)+cost(k,i)) dp(i,j)=max/min(dp(k,j−1)+cost(k,i)) 类似的。
复杂度不管怎么优化都至少是 O ( n m ) O(nm) O(nm) 及以上的。
无法接受。
打表发现形成凸包 、斜率单调 / 满足特点。
且如果这题没有恰好选 m m m 个的限制就可以 d p dp dp 降维转移。
就可以用 WQS \text{WQS} WQS 二分降维。
时间复杂度 O ( n log V ) O(n\log V) O(nlogV)。
算法分析
Part 0:前提假设。
算法分析均假设题目要求是最大化权值。
算法分析均假设 ( i , g ( i ) ) (i,g(i)) (i,g(i)) 拟合出的图形是上凸包。
Part 1:二分的部分。
先不考虑 m m m 的限制。
二分一个 m i d mid mid,表示选一次物品的附加权值。
- 注意:是『选一次』,不是『选一个』。因为有的题目选一次对应一段区间,即多个物品。
则选的次数越多,权值越大。
所以当最优方案选的物品次数大于 m m m 时,就减小 m i d mid mid,否则增加 m i d mid mid。
最后答案去掉 m i d mid mid 的影响即可。
part 2:二分
check
\text{check}
check 的部分。
Ⅰ
我们先看一下 ( i , g ( i ) ) (i,g(i)) (i,g(i)) 构成的凸包样子。
二维平面坐标系中,横坐标 x x x 轴表示:选 x x x 次物品;纵坐标 y y y 轴表示:选 x x x 次情况下的最大答案。
显然只要求出 x = m x=m x=m 对应凸包上的点即可,即 g ( m ) g(m) g(m)。
但问题就是不能很快速地求出 g ( m ) g(m) g(m) 。
也就是说 这个凸包暂时是求不出来的,但是可以知道这个凸包的形状——上凸包。
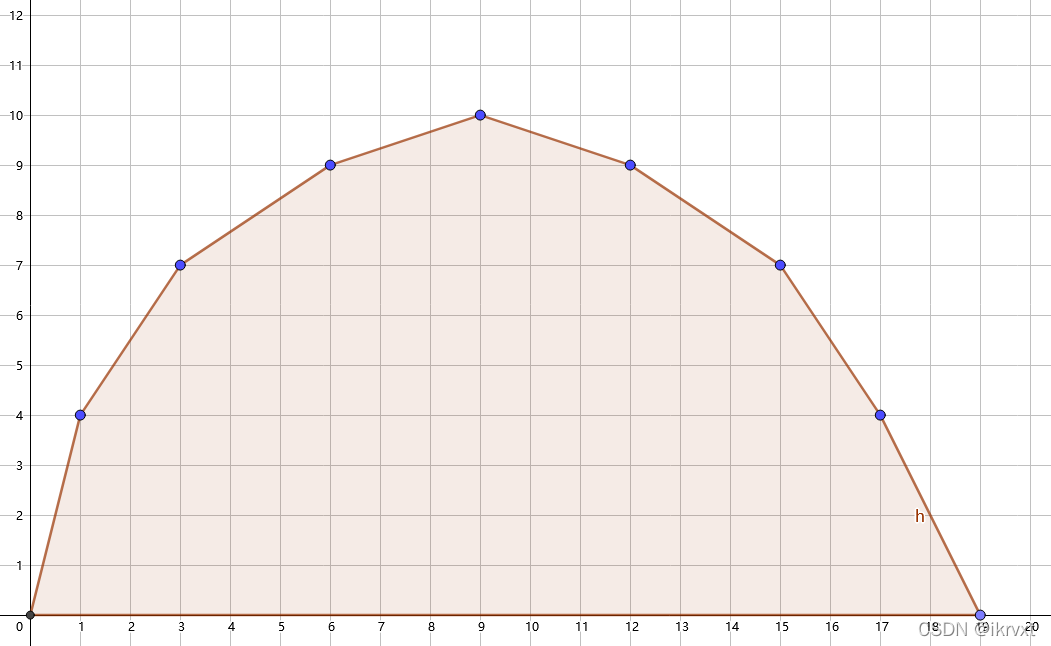
于是考虑 用直线去切凸包 。
显然可以得到一个最大值(最先切到的点就是最优答案选物品的次数以及最大答案)
同时,也显然这个最大值点不一定全都是恰好在 x = m x=m x=m 处的。
e.g. 假设
m
=
12
m=12
m=12,随便用一条斜率为
k
k
k 的直线去切,红色直线就切在了
x
=
6
,
x
=
9
x=6,x=9
x=6,x=9 的点。
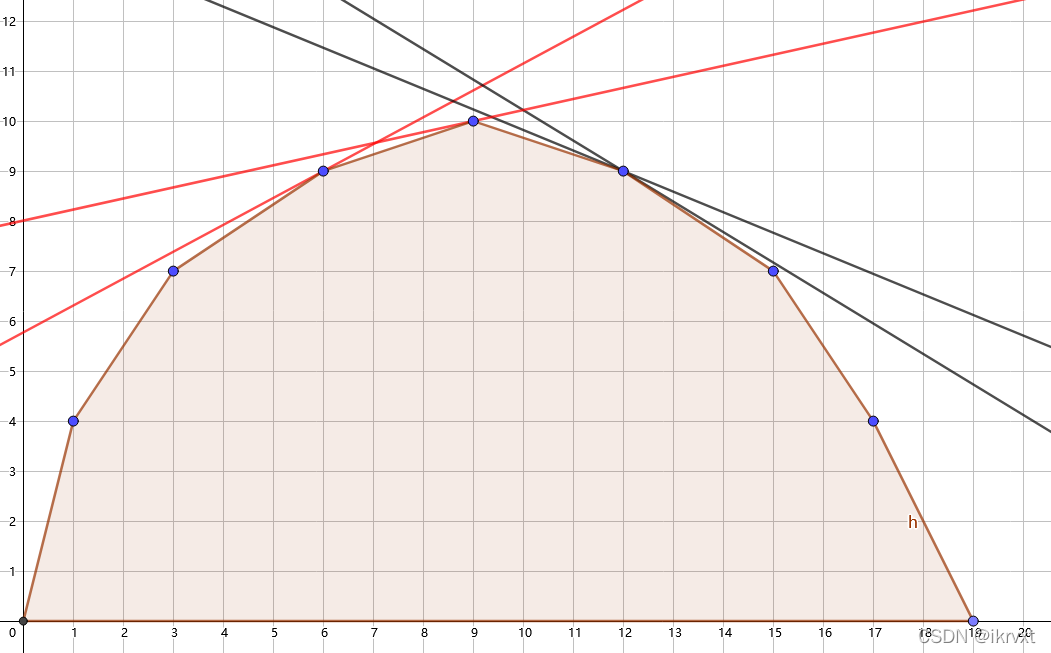
上面说到,斜率为 k k k 的直线切凸包,每次最先切到的点就是最优答案。
所以我们可以通过 调整斜率 k k k 来使得直线切到不同的位置点。
由于 g ( x ) g(x) g(x) 的斜率单调,所以直线斜率 k k k 切到的点同样具有单调性。
e.g. 如图,斜率越小,切到凸包的点越往右,即越大。
Ⅱ
假设一个斜率为 k k k 的直线,考虑如何求得该直线最先切在凸包的位置,即 ( x , g ( x ) ) (x,g(x)) (x,g(x))。
发现,斜率为 k k k 的直线在凸包上切到的所有点,可以和 k k k 一起唯一地刻画一条完整直线 y = k x + b y=kx+b y=kx+b 。
且最先切的点,即要求的位置,和 k k k 刻画的直线的截距 b b b 一定是最大的。如图。
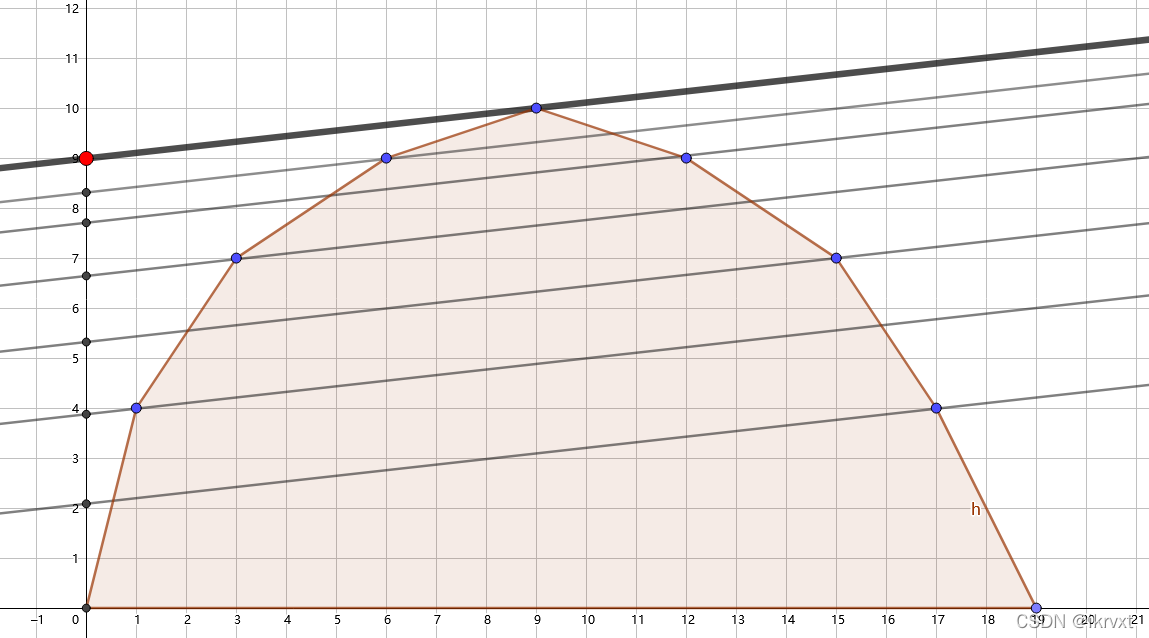
根据小学初中知识,截距
b
=
y
−
k
x
b=y-kx
b=y−kx。具体地,截距
b
(
x
)
=
g
(
x
)
−
k
∗
x
b(x)=g(x)-k*x
b(x)=g(x)−k∗x。
观察这个式子,发现式子等价于:只要把每次选择获得的权值和 − = k -=k −=k,然后正常求 在选任意次物品情况下最大的答案是多少 即可。
这个最大答案就是最大的截距。
而这种问题用 d p dp dp 是线性 O ( n ) O(n) O(n) 可做的。
并且 d p dp dp 的同时可以知道最大值点在凸包的位置,那么我们就知道了 ( x , g ( x ) ) (x,g(x)) (x,g(x))。
这样就可以返回然后判断二分了。
Ⅲ
综上需要明确的是 WQS \text{WQS} WQS 二分模板代码中:
二分的是切凸包的直线斜率 k k k。调整斜率就是调整二分的额外贡献。即附加贡献就是斜率。
二分的检查函数(带额外权值的)中的 d p dp dp 算的是直线的截距。
WQS二分精髓的两点细节(博客重点!)
建议先做个模板题,再做个加强题,最好加强题半对半错,然后晕乎乎地过来哈哈哈
如果你有把最后二分出的斜率对应的检查函数中的最大值点输出出来看过,发现貌似这个最大值点也不等于 m m m 。
如果你发现自己最后二分出的斜率 ± 1 ±1 ±1 可能就会过掉这个题,或者过的点更多。
如果你觉得最后的答案不应该用 m m m 乘以附加权值再被去掉。而应该用附加权值对应的最大值点来乘。
等等等等 … \dots …。
那么证明你已经走到了 WQS \text{WQS} WQS 的精髓部分了。
那就是初学者都要疑惑的两点 :
-
你觉得最后的答案不应该用 m m m 乘以附加权值再被去掉。而应该用最优方案实际选的次数来乘。
这个问题如果你有,证明你没有搞明白二分的究竟是什么,检查函数 d p dp dp 算的又究竟是什么。
再声明一下,二分的是斜率,检查函数算的是该斜率对应的最优方案的截距。
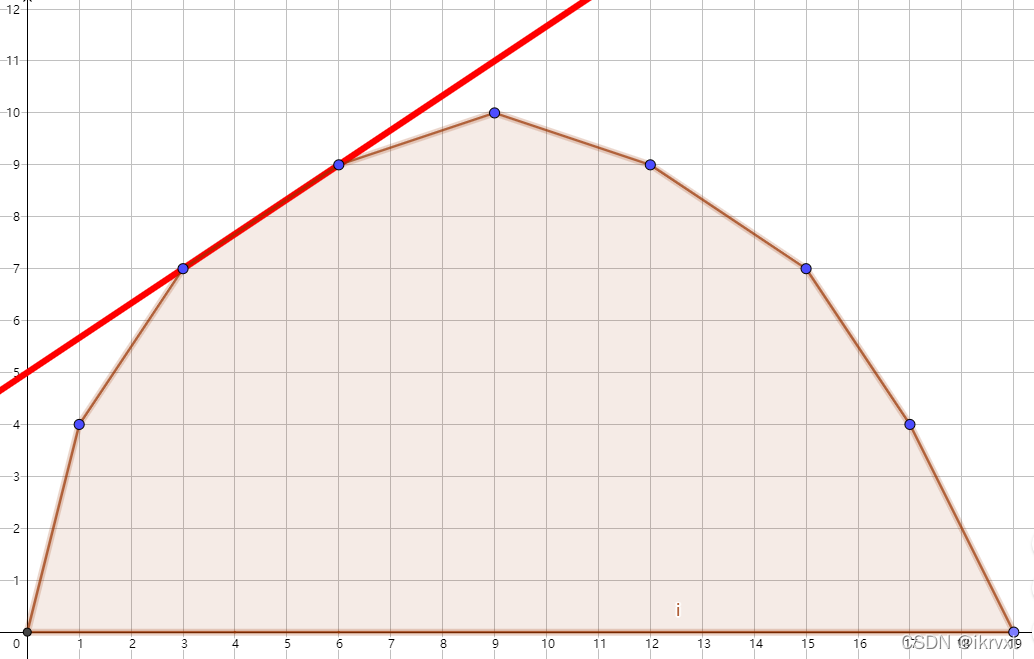
仔细观察,这张图暗藏玄机!
你有没有发现这条直线切了 x = 3 , 4 , 5 , 6 x=3,4,5,6 x=3,4,5,6 的点!(最先切到的可能同时是一段点)
这也是为什么 m i d mid mid 时最优点 < m <m <m ; m i d + 1 mid+1 mid+1 时最优点 > m >m >m。
也即是前面说的,斜率在一定范围内都是切的一个点。
我们现在的最佳直线就是这条红线,而我们记录的凸包上的点也许是 x = 3 , x = 6 x=3,x=6 x=3,x=6,而最后 m = 4 / 5 m=4/5 m=4/5。
但是这些点都是在直线上的,而我们用 d p dp dp 出来的最大截距 b b b 要 + k ∗ m +k*m +k∗m 才能 = g ( m ) =g(m) =g(m)。
所以的确是要去掉 m ∗ m* m∗ 最后二分定的斜率。
-
假设最后斜率为 m i d mid mid 最大值点 < m <m <m ;而斜率为 m i d + 1 mid+1 mid+1 最大值点又 > m >m >m。也就是说,似乎必须要附加权值为小数,才能求出 x = m x=m x=m 的情况。
但你如果写小数二分,那就会遇上 TLE \text{TLE} TLE 的结果。
事实上,是可以不用二分到小数的。
我们在排序上做点手脚,使得当选的次数 ≥ m \ge m ≥m 是更新答案。(符号 $\ge,\le $ 看对应排序和二分写法)
理论的分析就是上面那张图。由于 x x x 是一个整数,切出来的直线的斜率 k k k 在一个范围 [ k l , k r ] [k_l,k_r] [kl,kr] 内都是落在同一个 x x x 点上。
注意每个属性都要定义偏序关系
根据题目是求最大值还是最小值,来定二分的边界是在负数还是在正数还是都有。
还有自己是写的额外加贡献还是额外减贡献,最后去掉答案的时候要对应。
一定要搞清楚自己二分造成的影响是会使得选的次数增多还是减小。
这些都是每个人不同的代码习惯造成的差异。
e.g求分若干组的最大值,假设二分是在负数内l=-1e6,r=0,并且写得是减法,也即是分的组数越多获得的额外贡献越大。所以当最优答案 ≥ \ge ≥ 限制时更新,并且减少增加的额外贡献,对应r=mid-1。e.g.求分若干组的最大值,假设二分时在正数内l=0,r=1e6,并且写的减法,也即是分的组数越多获得的额外贡献越小(是负的),所以当最优答案 ≤ \le ≤ 限制时更新(减多了,才会使得分的段数变少),并且增加获得的额外贡献,对应r=mid-1。但实际上 ≤ , ≥ \le,\ge ≤,≥ 要看第二属性的排序。
最后我们强调一下为什么要“每个属性都定义偏序关系”!
首先你要知道凸包上的所有点并不是都存了下来的,比如上面图的凸包就是只存在蓝点。
为什么只存在蓝点,是因为我们的第二属性偏序使得当直线截距相同时我们只存储最小值 / 最大值(最左边点/最右边点)
而你的 x = m x=m x=m 答案点就在相同截距最左边点的右边,最右边点的左边。
如果不写当第一属性相同时,第二属性怎么排,你的凸包可能刻画出来就是有问题的。
这里说第一属性,第二属性可能你压根不理解。具体可见下面三道真题分析。
真题分析
[国家集训队]Tree Ⅰ
对全部边进行排序,跑最小生成树,我们可以得到最优的答案,但是白边不一定恰好是要求的条数。
二分白边的额外权值。再跑最小生成树。
如果白边少了,说明白边整体权值比较大,所以没被选中。那我就对白边都减少额外权,这样的话,被选中的白边会增多。
同理,如果被选白边数量多了,我就给白边们都多加一点额外权。
这里当白边边权和黑边边权相同时,我们必须钦定先选白边还是先选黑边。
如果我们排序是先选白边,那么求得就是在二分的斜率切到的所有点中最靠右的点,二分写法得用 ≥ \ge ≥ 判断更新;
反之,边权相同时先选黑边,那么求得的就是切到的所有点中最靠左的点(最小点),二分写法得用 ≤ \le ≤ 更新判断。
因为最左边点 ≤ m ≤ \le m\le ≤m≤ 最右边点。
这里的两个属性分别是边权(第一属性)和颜色(第二属性) 。
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define maxn 100005
struct node { int u, v, w, c; }E[maxn];
int u[maxn], v[maxn], w[maxn], c[maxn], f[maxn];
int cnt, ans, n, m, k;
int find( int x ) { return f[x] == x ? x : f[x] = find( f[x] ); }
void check( int x ) {
cnt = ans = 0;
for( int i = 1;i <= m;i ++ )
if( c[i] ) E[i] = (node){ u[i], v[i], w[i], c[i] };
else E[i] = (node){ u[i], v[i], w[i] - x, c[i] };
sort( E + 1, E + m + 1, []( node x, node y ) { return x.w == y.w ? x.c < y.c : x.w < y.w; } );
iota( f + 0, f + n, 0 );
for( int i = 1;i <= m;i ++ ) {
int fu = find( E[i].u ), fv = find( E[i].v );
if( fu == fv ) continue;
f[fv] = fu;
cnt += (E[i].c ^ 1);
ans += E[i].w;
}
}
signed main() {
scanf( "%lld %lld %lld", &n, &m, &k );
for( int i = 1;i <= m;i ++ )
scanf( "%lld %lld %lld %lld", &u[i], &v[i], &w[i], &c[i] );
int l = -100, r = 100, ret;
while( l <= r ) {
int mid = l + r >> 1;
check( mid );
if( cnt >= k ) ret = mid, r = mid - 1;
else l = mid + 1;
}
check( ret );
printf( "%lld\n", ans + ret * k );
return 0;
}
忘情
先化式子:
(
(
∑
i
=
1
n
x
i
×
x
ˉ
)
+
x
ˉ
)
2
x
ˉ
2
=
x
ˉ
2
(
∑
i
=
1
n
x
i
)
2
+
2
x
ˉ
2
∑
i
=
1
n
x
i
+
x
ˉ
2
x
ˉ
2
=
(
∑
i
=
1
n
x
i
)
2
+
2
(
∑
i
=
1
n
x
i
)
+
1
=
(
∑
i
=
1
n
x
i
+
1
)
2
\frac{\Big((\sum_{i=1}^nx_i\times \bar{x})+\bar{x}\Big)^2}{\bar{x}^2}=\frac{\bar{x}^2(\sum_{i=1}^nx_i)^2+2\bar{x}^2\sum_{i=1}^nx_i+\bar{x}^2}{\bar{x}^2}=(\sum_{i=1}^nx_i)^2+2(\sum_{i=1}^nx_i)+1=(\sum_{i=1}^nx_i+1)^2
xˉ2((∑i=1nxi×xˉ)+xˉ)2=xˉ2xˉ2(∑i=1nxi)2+2xˉ2∑i=1nxi+xˉ2=(i=1∑nxi)2+2(i=1∑nxi)+1=(i=1∑nxi+1)2
设
f
(
i
,
j
)
:
f(i,j):
f(i,j): 前
i
i
i 个数分成
j
j
j 段的最小值。
f ( i , j ) = min { f ( k , j − 1 ) + ( s u m [ i ] − s u m [ k ] + 1 ) 2 } f(i,j)=\min\Big\{f(k,j-1)+(sum[i]-sum[k]+1)^2\Big\} f(i,j)=min{f(k,j−1)+(sum[i]−sum[k]+1)2}。
直接 WQS \text{WQS} WQS 二分:每分一次段就 + x +x +x。
那么 d p dp dp 就变成一维了,斜率优化部分就不再多说了。
这里是段分的越多,获得的额外价值就越多。
而我想要的是最小值。
注意斜率优化里面的弹队列的写法, = = = 问题我也弹出了,也就是说第一属性相同时我选择了第二属性较大的。
这里第二属性就是到 i i i 位置分的段数,即最后斜率切的最右边的点。
那么限制 m m m 应该在这个点的左边,所以写法是 g [ n ] ≥ m g[n]\ge m g[n]≥m 才更新。
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define maxn 100005
int n, m;
int x[maxn], f[maxn], g[maxn], q[maxn], sum[maxn];
double slope( int x, int y ) {
return ( (f[x] - (sum[x] << 1) + sum[x] * sum[x]) - (f[y] - (sum[y] << 1) + sum[y] * sum[y]) ) * 1.0 / (sum[x] - sum[y]);
}
void check( int x ) {
int head = 1, tail = 0; q[++ tail] = 0;
for( int i = 1;i <= n;i ++ ) {
while( head < tail and slope( q[head], q[head + 1] ) <= (sum[i] << 1) ) head ++;
f[i] = f[q[head]] + (sum[i] - sum[q[head]] + 1) * (sum[i] - sum[q[head]] + 1) + x;
g[i] = g[q[head]] + 1;
while( head < tail and slope( q[tail - 1], q[tail] ) >= slope( q[tail], i ) ) tail --;
q[++ tail] = i;
}
}
signed main() {
scanf( "%lld %lld", &n, &m );
for( int i = 1;i <= n;i ++ ) scanf( "%lld", &x[i] );
for( int i = 1;i <= n;i ++ ) sum[i] = sum[i - 1] + x[i];
int l = 0, r = 1e16, ans;
while( l <= r ) {
int mid = ( l + r ) >> 1;
check( mid );
if( g[n] >= m ) ans = mid, l = mid + 1;
else r = mid - 1;
}
check( ans );
printf( "%lld\n", f[n] - ans * m );
return 0;
}
星际广播
给定一个长为 n n n 的字符串 s s s,第 i i i 个星球的编号 s i s_i si 只可能为 R / B / Y R/B/Y R/B/Y。
现在可以给长度为 l l l 的区间进行星际广播,使得区间内的所有广播站编号全部变为指定编号。
限制最多只能进行 m m m 次广播。
剩下的想改变的广播站只能单独进行电话连线发出改变成指定编号的指令。
求最少需要和多少个星球单独电话才能使得 n n n 个星球的编号统一。
solution
显然这个最多可以变成恰好,因为广播不带来代价,我们肯定是能用则用。
所以开始现特判当 m ∗ l ≥ n m*l\ge n m∗l≥n 时,输出 0 0 0。
我们直接枚举最后统一的编号是哪种。假设为 c h ch ch,然后对每一种都进行下列算法。
现在 m ∗ l < n m*l<n m∗l<n,贪心的策略告诉我们存在一种最优方案使得广播的区间一定是不交的。
我们肯定是用广播尽可能地覆盖不同编号的星球。
如果列出暴力 d p dp dp 及转移方程,可以发现能 WQS \text{WQS} WQS 降维。这里不再重复。
直接二分斜率(每广播一次带来的额外代价)。
设 f ( i ) : f(i): f(i): 到 i i i 为止被改变编号的星球个数。
设 g ( i ) : g(i): g(i): 到 i i i 为止最少使用的广播次数。
记 c ( i ) = ∑ j = 1 i [ s j ≠ c h ] c(i)=\sum_{j=1}^i[s_j\ne ch] c(i)=∑j=1i[sj=ch]。
则有转移 f ( i ) = max 1 ≤ j ≤ i − l { f ( j ) + c ( i ) − c ( i − l ) } f(i)=\max_{1\le j\le i-l}\{f(j)+c(i)-c(i-l)\} f(i)=max1≤j≤i−l{f(j)+c(i)−c(i−l)}。
即被改变的星球个数是第一属性,使用的广播次数是第二属性。
这里我指定最小广播次数优,所以求得的是凸包相同斜率的最左边点,所以二分要用 ≤ m \le m ≤m 判断。
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define maxn 1000005
int n, m, l;
char s[maxn];
int f[maxn], g[maxn], c[maxn], q[maxn];
int check( int x ) {
int pos = 0;
for( int i = 1;i <= n;i ++ ) {
if( l < i ) {
if( f[pos] < f[i - l] or (f[pos] == f[i - l] && g[pos] >= g[i - l] ) ) pos = i - l;
f[i] = f[pos] + c[i] - c[i - l] + x;
g[i] = g[pos] + 1;
}
else f[i] = c[i] + x, g[i] = 1;
}
pos = 0;
for( int i = 1;i <= n;i ++ )
if( f[i] > f[pos] or (f[i] == f[pos] and g[pos] < g[i] ) ) pos = i;
return pos;
}
int solve( char x ) {
for( int i = 1;i <= n;i ++ ) c[i] = c[i - 1] + (s[i] != x);
int l = -1e6, r = 0, ans;
while( l <= r ) {
int mid = l + r >> 1;
int pos = check( mid );
if( g[pos] <= m ) ans = mid, l = mid + 1;
else r = mid - 1;
}
int pos = check( ans );
return c[n] - (f[pos] - m * ans);
}
signed main() {
scanf( "%lld %lld %lld %s", &n, &m, &l, s + 1 );
if( m * l >= n ) return ! puts("0");
int ans1 = solve( 'R' );
int ans2 = solve( 'B' );
int ans3 = solve( 'Y' );
printf( "%lld\n", min( ans1, min( ans2, ans3 ) ) );
return 0;
}














 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









