






多模态大型语言模型(MLLM)是人工智能领域的前沿创新,它结合了语言和视觉模型的功能,可以处理复杂的任务,如视觉问答和图像字幕。这些模型利用大规模预训练,集成了多种数据模态,以显著提高其在各种应用程序中的性能。

架构概览
较为常见的MLLM框架可以分为三个主要模块:接收且有效编码的多模态编码器、多模态之间数据对齐的投影器、和接收对齐信号并执行推理的大语言模型。当然各种项目总有自己的差异化设计,例如Chameleon或者Octo。
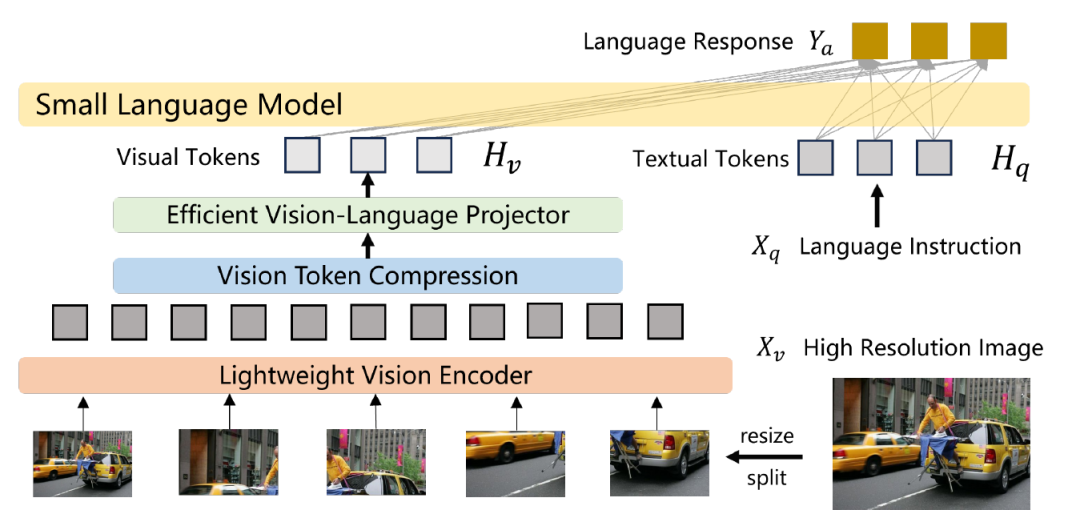
MLLM的主要的优化方向,在于处理高分辨率图像、压缩视觉标记(token)、多模态对齐、高效结构和利用紧凑语言模型等。
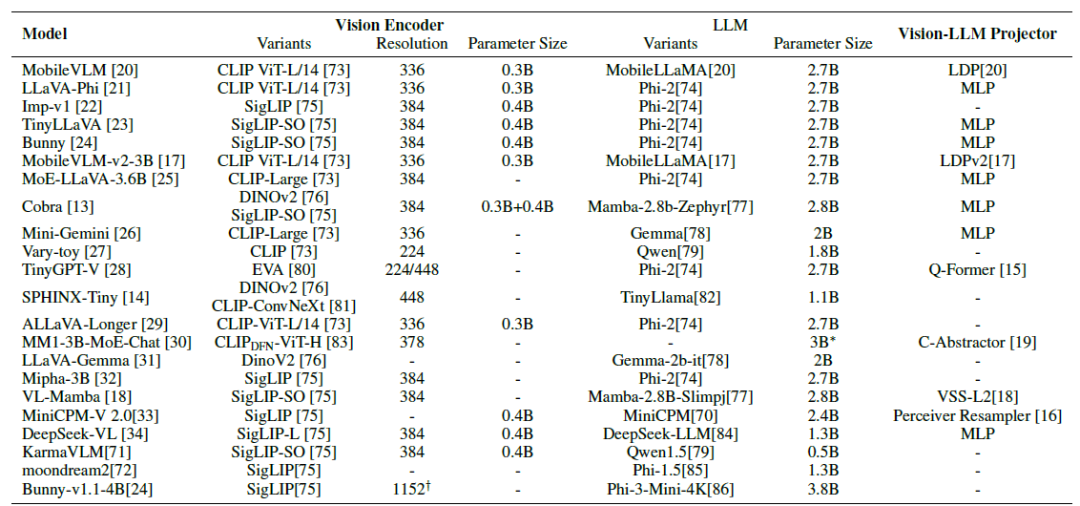
上图是一些MLLM的部分例子,将其中的基座LLM、视觉编码器、图像分辨率和投影器列具出来。

视觉编码器
来看看视觉编码器,与主流MLLM实践一致,基本上都是选择CLIP<链接查看详情!>的预训练模型。这种方法有助于更好地对齐视觉和文本输入的特征空间。视觉编码器在MLLM参数中所占比例相对较小,因此与语言模型相比,轻量级优化不是刚需。
单一的编码器肯定无法在不同的任务中始终表现出色,将各种偏差的数据编码器进行联动则能够产生令人惊讶的相似结果。
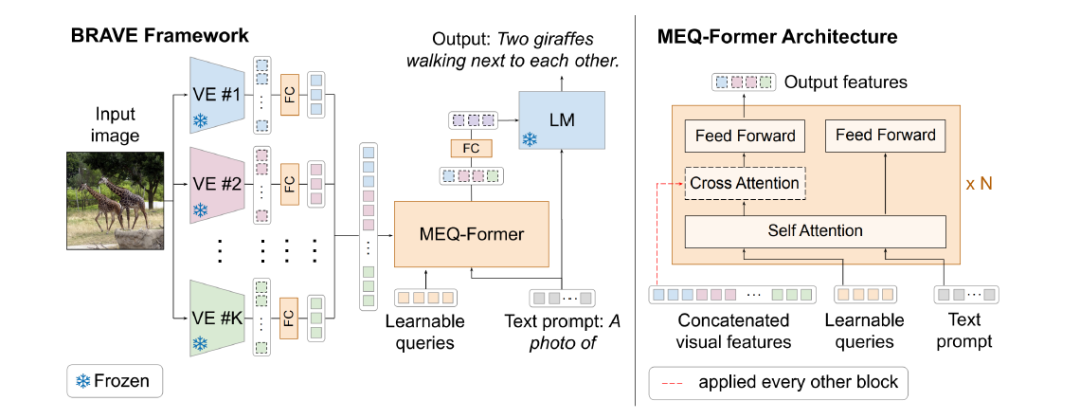
BRAVE的深度消融实验证明了上述的结论。BRAVE按顺序连接了K个不同视觉编码器的特征(上图左)。之后这些串联特征被MEQ-Former进一步提炼(上图右)。
多个视觉编码器的确有助于捕捉广泛的视觉表征,从而增强模型对视觉数据的理解。Cobra将DINOv2和SigLIP集成为其视觉主干,其原理是将DINOv2的低级空间特征与 SigLIP提供的语义属性相结合将提高后续任务的性能。SPHINX-X采用两个视觉编码器DINOv2和CLIP-ConvNeXt。
鉴于这些基础模型已经通过不同的学习方法(自监督与弱监督)和网络架构(ViT与 CNN)进行预训练,应该能够提供互补和复杂的视觉表征。
这些术语将在后续的文章中逐一讲解!可以关注“具身智能”专栏!
轻量级视觉编码器Vision Transformer架构在实际应用中由于硬件和环境限制而面临挑战。ViTamin代表一种轻量级视觉模型,专门针对视觉和语言模型量身定制。依照下图所示,通过两层的MBC外加一层的注意力块完成视觉编码,然后和文本一起进行对比学习。
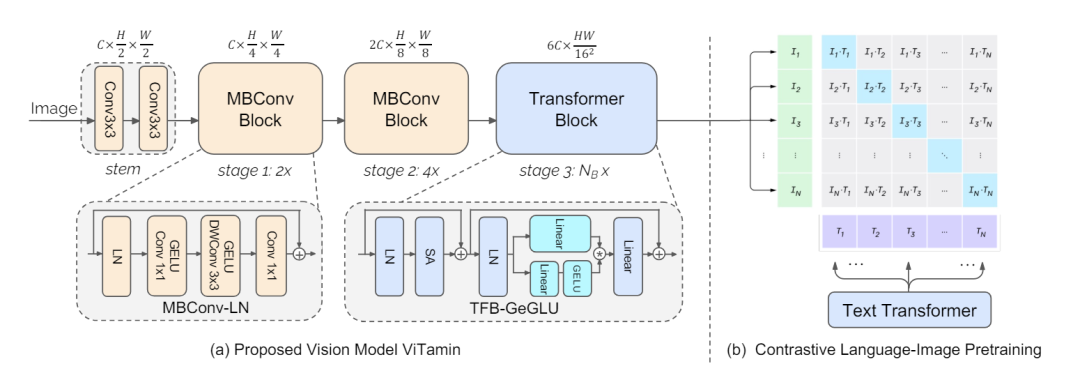
值得一提,ViTamin-XL的参数数量只有436M,却达到了ImageNet zero-shot 82.9%的准确率,超过了EVA-E的准确率82.0%。要知道EVA-E的参数数量为4.4B。

视觉投影器
视觉投影器的目的在于将视觉嵌入(Visual embeddings)等输入映射到文本空间(Text Embeddings)中。换句话说也就是将不同模态进行对齐。
1)投影,相信读者最直观的就是线性投影仪或多层感知器(MLP)来实现,可以理解就是最普通的神经网络。比如几层的神经网与非线性激活函数组合而成。
2)部分的投影基于注意力机制。BLIP2引入Q-Former,这是一种轻量级转换器,它使用一组可学习的查询向量从冻结的视觉模型中提取视觉特征。
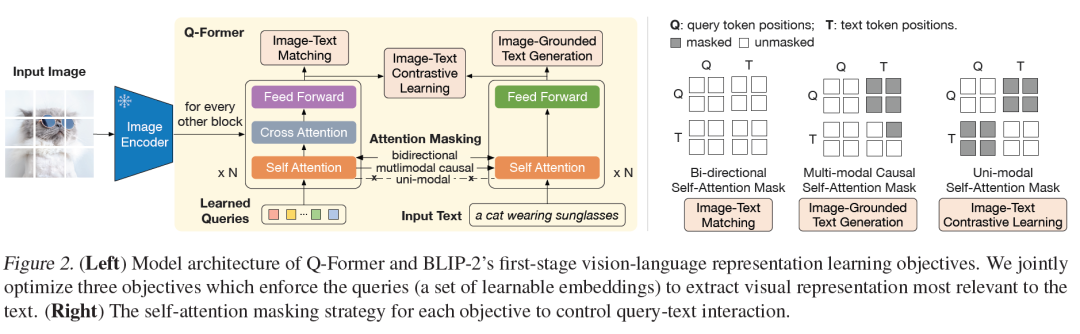
Q-former基于对比学习进行训练,上图右侧展示了由Flamingo提出的感知重采样器(Perceiver Resampler)考虑在交叉注意力中使用earned Queries(上图彩色序列块)作为Q,而图像特征展开与Q连接起来,在交叉注意力中充当K和V。
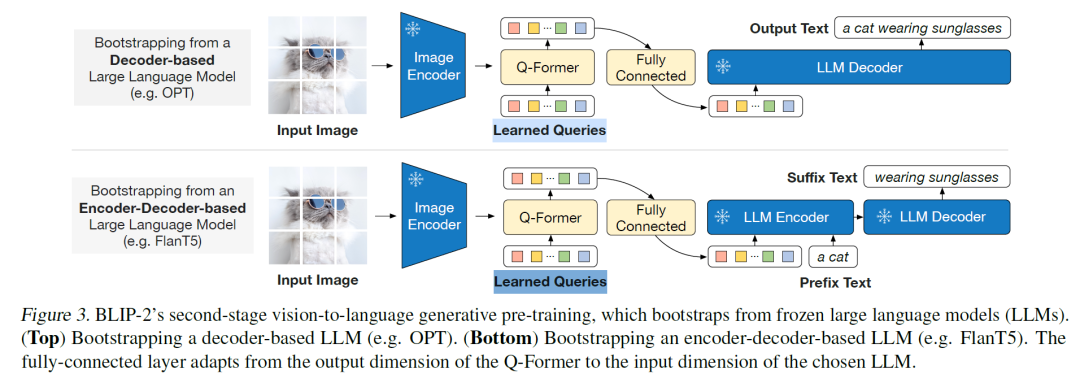
上图为BLIP-2的第二阶段架构,通过这种方式,在Learned Queries的相应位置的转换器输出被作为视觉特征的聚合表示,从而将可变长度的视频帧特征标准化为固定大小的特征。
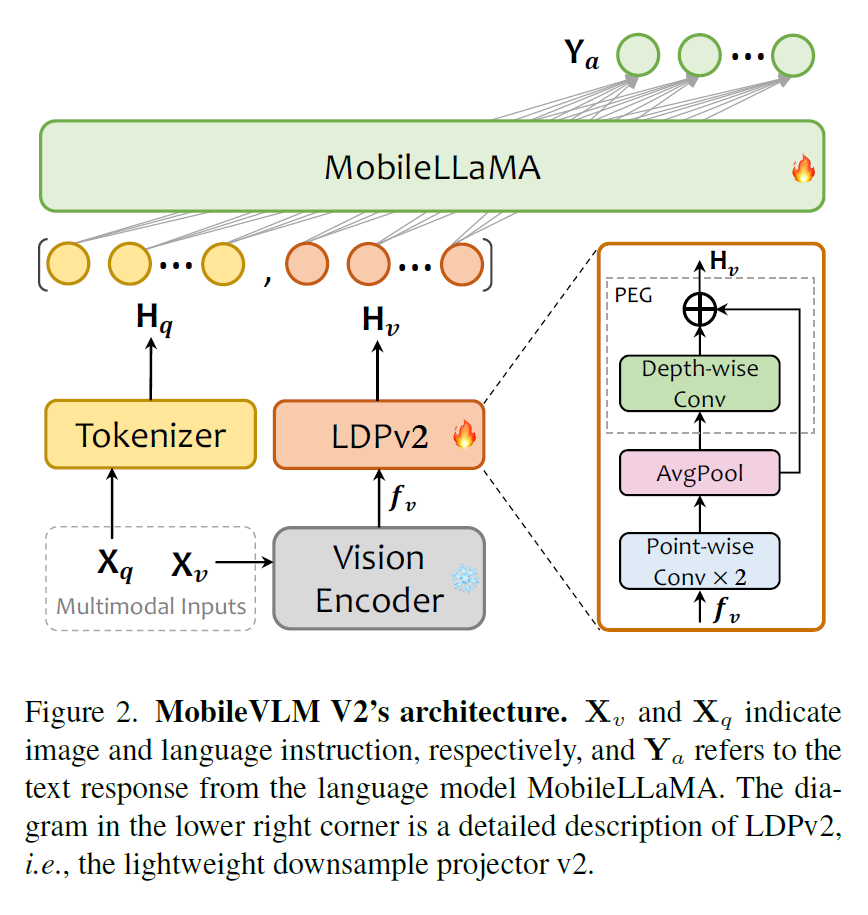
3)部分的投影基于CNN。MobileVLMv2提出了LDPv2,这是一种新的投影。由三部分组成:特征转换、Token压缩和位置信息增强。通过使用逐点卷积层、平均池化和具有跳跃连接的PEG模块,LDPv2实现了更高的效率,与原始LDP相比,参数减少了99.8%,处理速度略快。
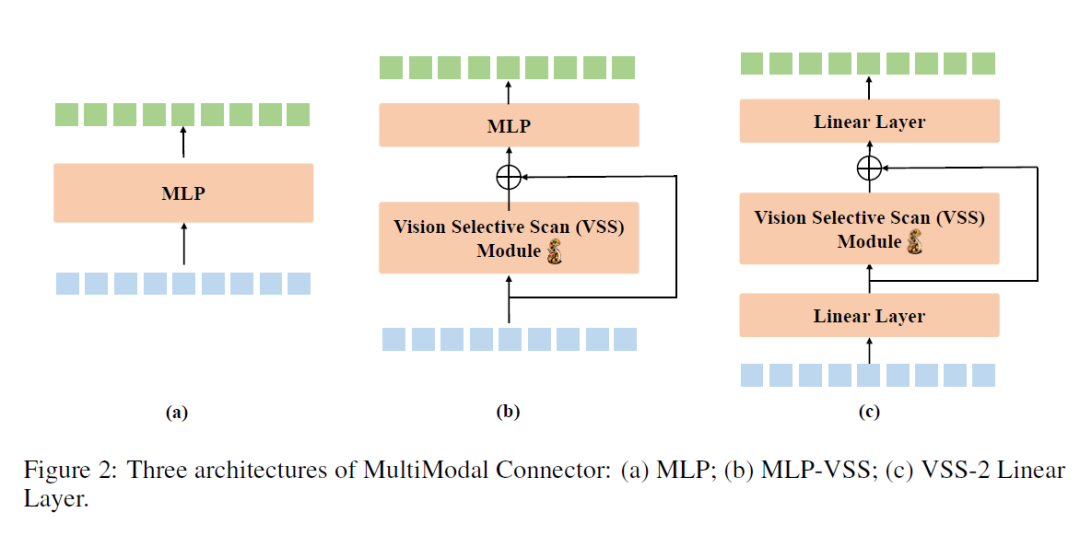
4)最后还有基于大名鼎鼎的Mamba,VL-Mamba在其视觉语言投影仪中实现了2D视觉选择性扫描(VSS)技术,促进了不同学习方法的融合。
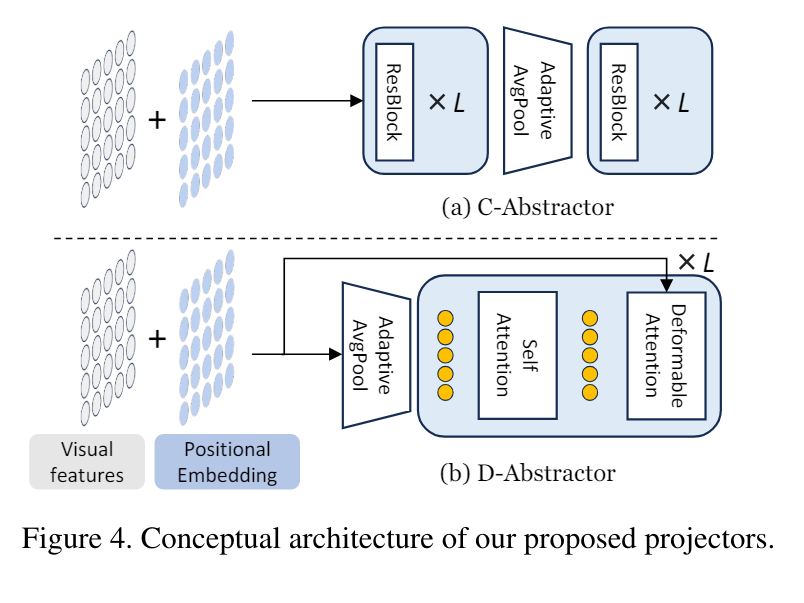
5)和所有武功都有最后一式一样,投影可以采用混合架构。Honeybee提出了两种视觉投影仪的组合,即C-Abstractor和D-Abstractor,它们遵循两个主要设计原则:(i)在视觉Token数量生成方面提供适应性,以及(ii)有效地维护本地上下文。下图详细的展示了Honeybee的投影混合架构:
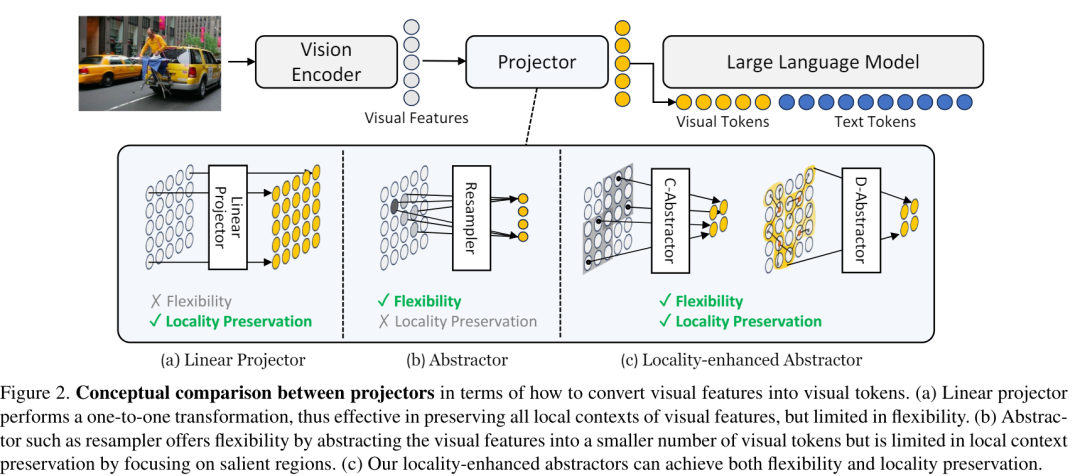
C-Abstractor,或卷积抽象器,专注于通过采用卷积架构来熟练地对局部上下文进行建模。该结构由L个ResNet块组成,然后紧接着是额外的L个ResNet块,这有助于将视觉特征抽象为任意平方数量的视觉标记。而D-Abstractor是基于Deformable注意力的Abstractor。

视觉Token压缩
MLLM在需要复杂识别的任务中面临着相当大的挑战,尤其是带有OCR的场景。尽管提高图像分辨率可以解决,然而增加视觉Token的数量给MLLM带来了巨大的计算负担,这主要是由于Transformer架构中计算成本与输入Token数量呈二次比例,因此如何优化则成为这个领域很热门的主题。
直接使用高分辨率视觉编码器进行细粒度感知的成本高,并且不符合实际使用要求。为了让MLLM能够感知细节且实现低分辨率的编码能力,一般会利用全局视图进行图片规模的压缩以及通过拆分衍生局部的图像块(Patch)。
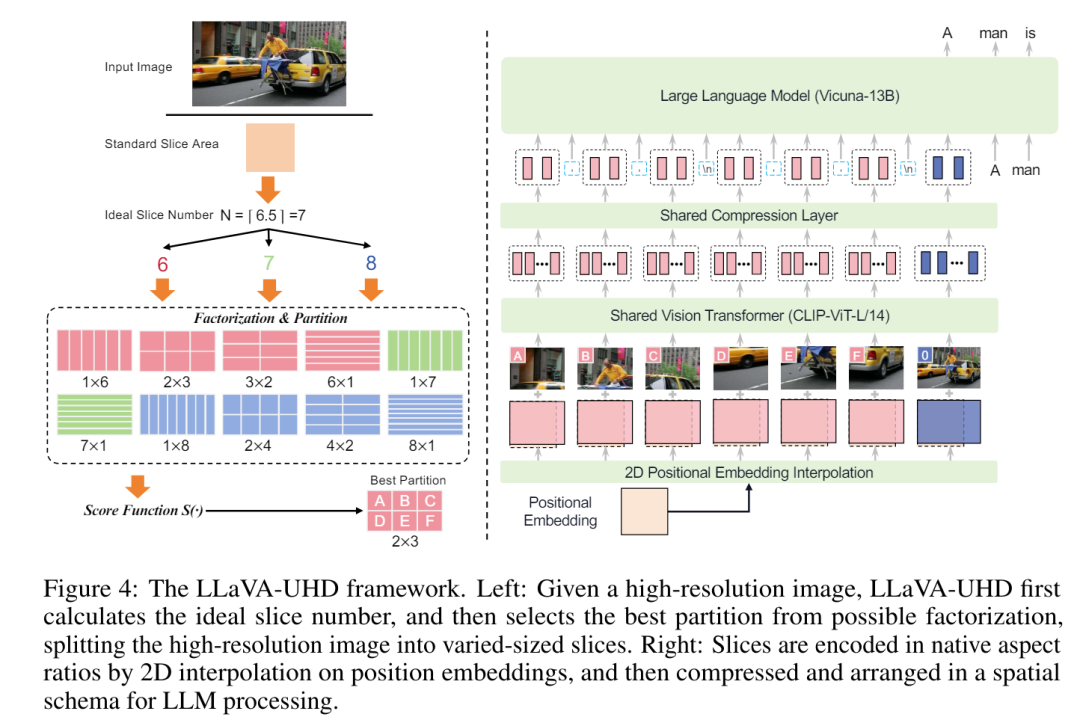
LLaVA-UHD提出了一种图像模块化策略,将原生分辨率的图像划分为更小的可变大小切片,以实现高效和可扩展的编码。注意下图左侧,这个框架自动的选择最优的切分方案。
此外,InternLM-XComposer2-4KHD 引入了一种通过自动布局排列动态调整分辨率的策略,不仅可以保持图像的原始纵横比,还可以自适应地改变Patch布局和计数,从而提高图像信息提取的效率。

通过对不同分辨率的图像实施自适应输入策略,可以在感知能力和效率之间实现平衡。如上图所示,说白了就是将原图压缩和切块一起进行编码。
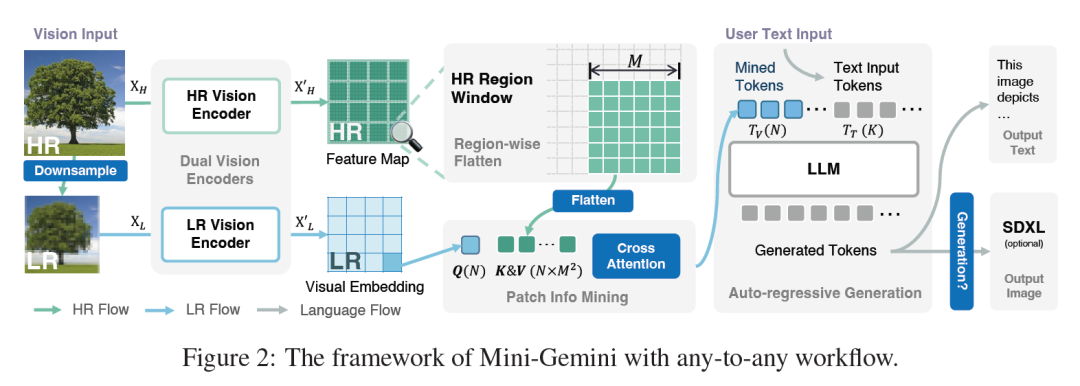
Mini-Gemini由两个编码器组成,一个用于高分辨率图像,另一个用于低分辨率视觉嵌入。它提出了patch的信息挖掘,它使用低分辨率的视觉嵌入作为查询,通过交叉注意力从高分辨率候选者那里检索相关的视觉线索。
Scaling on Scales表明,多尺度较小模型的学习能力与较大模型相当,并且预训练较小的模型可以在MLLM基准测试上匹配甚至超过较大模型的优势,同时计算效率更高。
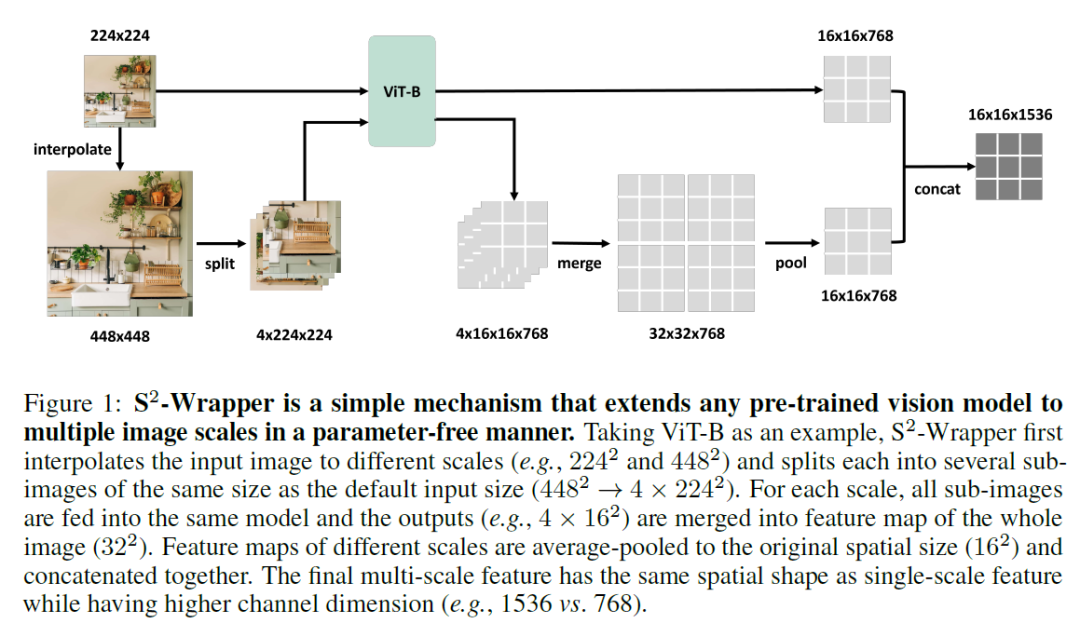
S2-Wrapper是一种简单的机制,它可以以无参数的方式将任何预训练的视觉模型扩展到多个图像尺度。以ViT-B为例,S2-Wrapper将输入图像插值到不同的尺度(例如2242和4482),然后将每个尺度分割成几个与默认输入大小相同的子图像(4482→4×2242)。对于每个尺度,所有子图像都被输入到同一个模型中,输出(例如4×162)被合并到整个图像的特征图中(322)。不同尺度的特征图被平均池化到原始空间大小(162)并连接在一起。最终的多尺度特征具有与单尺度特征相同的空间形状,但有更高维度(例如1536 vs 768)。

小结
MLLM的主要问题是资源需求,训练这些模型需要大量的计算资源,通常只有拥有大量预算的大型企业才能使用。例如,在 NVIDIA A100 GPU上训练像MiniGPT-v2这样的模型需要超过800个GPU小时,这对于许多学术研究人员和小公司来说成本是巨大的。此外,推理的高计算成本进一步加剧了这个问题,使得在边缘计算等资源受限的环境中部署这些模型变得困顿。OpenAI的GPT-4V和谷歌的Gemini等模型通过大规模预训练取得了显著的性能,但它们的计算需求限制了它们的使用。
目前应对这些挑战的方法集中在优化MLLM的效率上,需要MLLM采用多种创新技术来解决资源消耗问题。其中包括引入更轻的架构,旨在降低参数和计算复杂性。例如,MobileVLM和LLaVA-Phi等模型使用视觉Token压缩和高效的视觉语言投影器来提高效率。
通过采用Token压缩和轻量级模型结构,这些模型实现了计算效率的显著提高,并拓宽了其应用范围。例如,与以前的型号相比,LLaVA-UHD支持处理分辨率高达6倍的图像,只需94%的计算量。这使得在学术环境中训练这些模型成为可能,一些模型只需23小时即可使用8个A100 GPU进行训练。值得一提的是,这些效率的提高不是以牺牲性能为代价的。
既然大模型现在这么火热,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下风口,是一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









