









 博客引用深度学习与自动文摘案例,介绍实际处理问题和训练模型时常见的棘手问题及解决方法。如特征输入可结合多种信息,关键词借用指针思想链接解码,解码段用attention机制处理重复,大词表用mini batch词汇构成词汇表,还引入新网络思想迭代优化,NLP和CV领域可相互借鉴。
博客引用深度学习与自动文摘案例,介绍实际处理问题和训练模型时常见的棘手问题及解决方法。如特征输入可结合多种信息,关键词借用指针思想链接解码,解码段用attention机制处理重复,大词表用mini batch词汇构成词汇表,还引入新网络思想迭代优化,NLP和CV领域可相互借鉴。
最近挺忙的,看了很多关于对抗样本生成及防御的相关文章、并做了一些实践研究与探索。
但是在这里先不讨论这个,后期忙完、整理好了再分享。
今天去听了一上午的nlp课程,虽然主要接触的是图像相关的知识处理,但是感觉两者之间还是有非常大的联系的,很多知识都是相互借鉴的。
所以多了解一些还是非常有帮助的,在之前做的nlp相关的任务当中,遇到了很多问题、很是不解,正好今天讲到了,所以很是深刻拿来与大家分享。
在这当中同时分享在图像处理过程当中遇到的相关同样技巧处理,两者可谓不谋而合,相扶相助、共同成长。
具体的理论背景、细节就不多介绍了,在这里课堂是引用的深度学习与自动文摘的案例。自动文摘很好理解,就是文章的关键词、关键句等抽取简练组合成最终精华的部分。
基本框架流程:
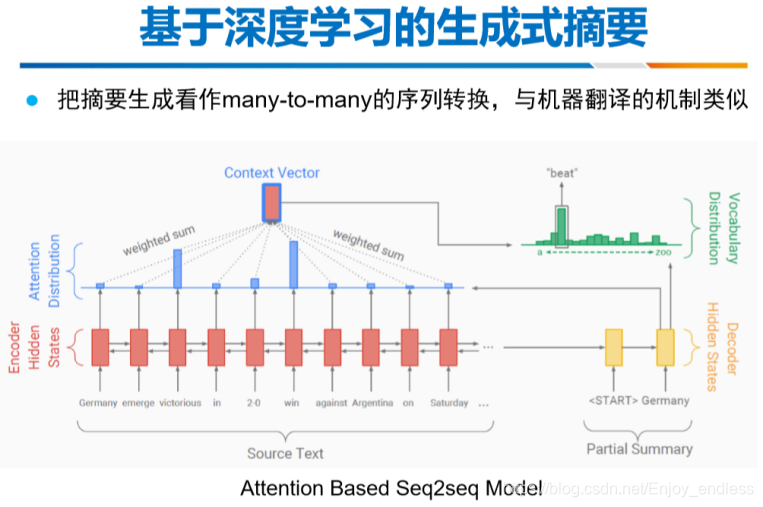
下面直接进入主要部分,就是在平时我们自己处理实际问题、训练模型当中经常遇到的相关棘手问题,并给与相关方法解决。详情如下:

下面就如上问题进行一一解答,并在每张图片下附上相关论文链接:
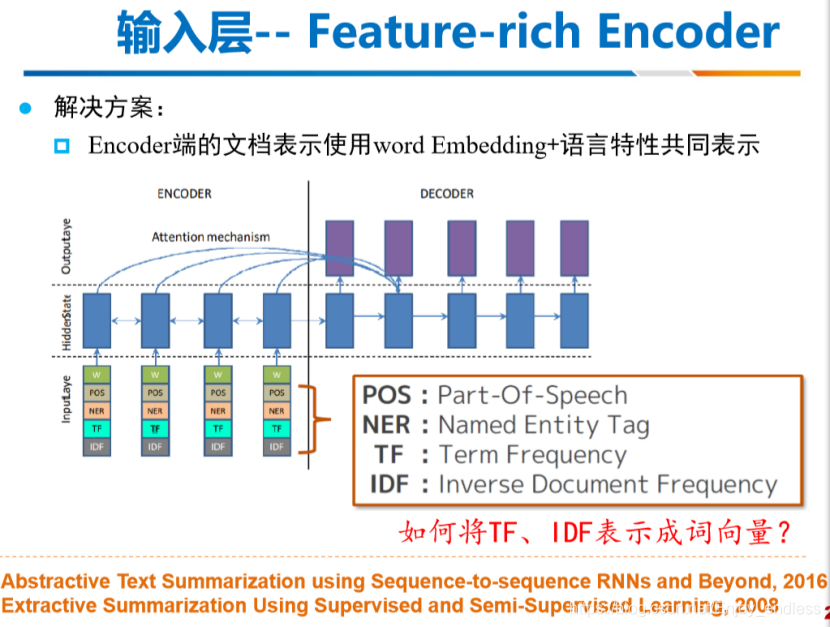
特征输入:一个是基本的词嵌入,相对单一一些,我们可以利用一些其他基本知识进行相互组合输入,比如加上相关的位置信息、实体标注、词频、文档频率等相关特征。
之前在做场景文本检测的时候,同样利用了位置信息进行输入加强,效果也是提升明显。
包括大火的transformer当中也是利用了位置信息进行加强。
而tfidf应该是传统方法当中最好的思想表达了,所以将传统方法经典思想借鉴转移还是非常有帮助的。
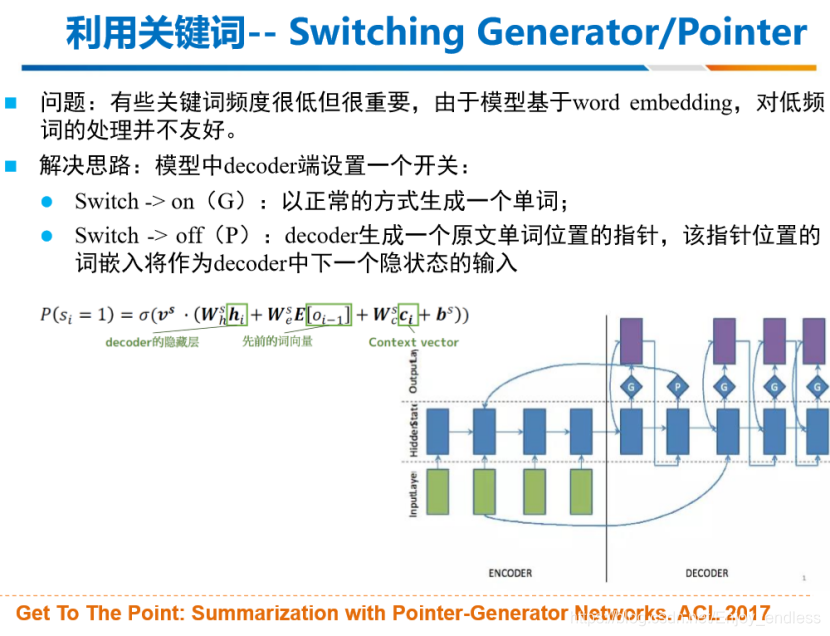
关键词频率很底但是很重要,他这里借用了类似于指针的思想,将那些重点关键词直接进行链接解码;具体原理详见图像下方论文。

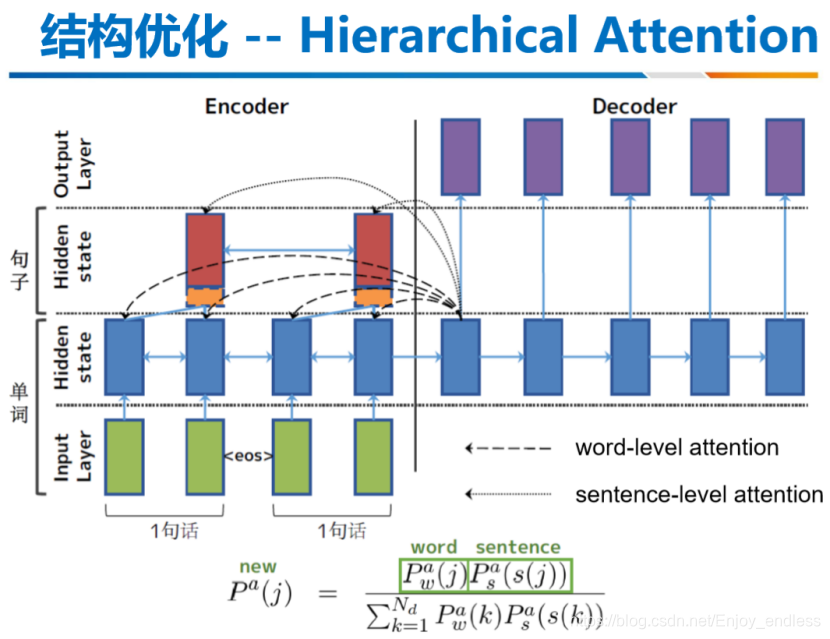
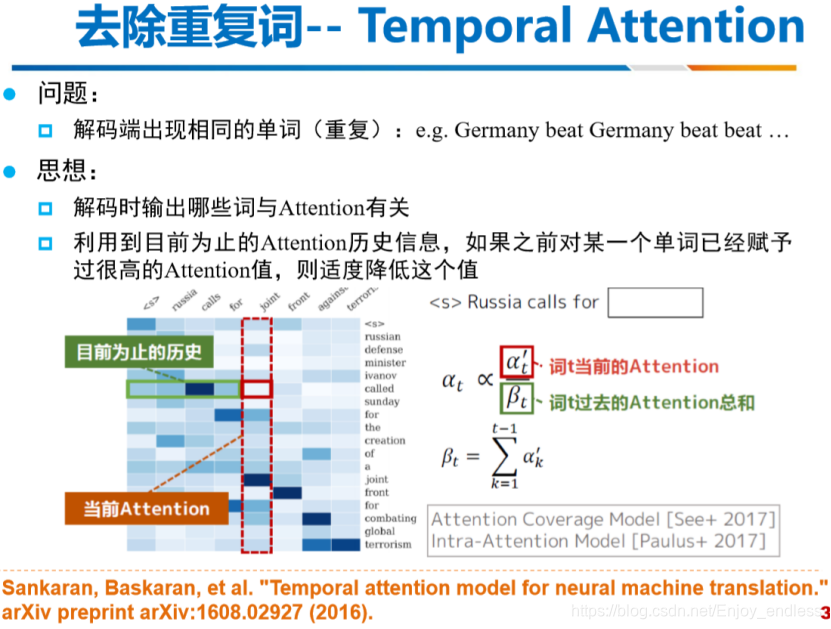
解码段出现重复的字母、单词应该是很常见的,在之前做的场景文字识别当中,解码出来同样会出现很多连续的重复词,当时引入了分隔符进行分隔识别,若连续重复字母当中无分隔符时,则结果只保留一个字母。这里利用了attention机制,根据先前的attent历史信息逐步降低之前attention值较高的值,这样做的具体效果如何,个人表示是有些疑惑的,还需要根据最后论文链接进行实地研究学习。

大词表问题更是非常常见,当时做过一个相关的任务,组成的核心词表好几万个,如果最后再利用softmax进行计算的,无疑是灾难性的。当时也是想了各种办法,并没有找到直接处理的好方法。这里利用mini batch中的词汇构成每一步的词汇表,可以说是一个非常好的思想,有时间可以具体针对之前的问题进行相关尝试解决。


在这里是引入了两种新的网络思想,进行相关反馈迭代优化,很直接也很好理解,多模型之间的学习、了解和融合还是非常值得借鉴和学习的。


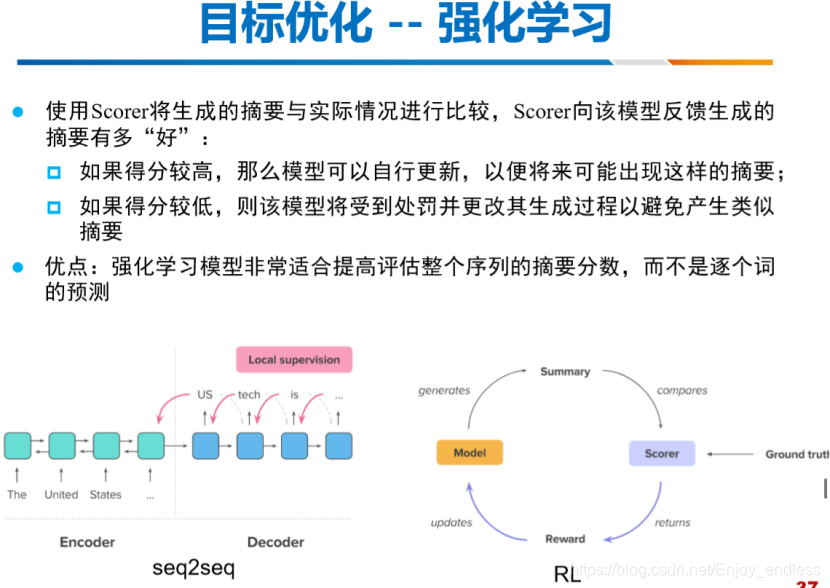
这些问题和解决方案都是非常常用和实际,可能等你真正实践过才会有所感触。另一个是这些问题、方案不论是在nlp还是在cv领域很多都是相通,且相互借鉴的;再一个对于传统方法、深度学习方法、以及多网络模型融合之间,都是具有很多的尝试、借鉴意义的,所以,多学习、了解、贯通一下,还是非常有必要的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









