










声明:本文笔记来源《一个贯穿图像处理与数据挖掘的永恒问题》,作者为左飞,原文地址: 更多细节点击这里。
# 1. 算法基础部分:求解一个3*3矩阵的中位数,常常用在图像处理中的patch处理。
# 2. R语言基础部分:读取数据,预处理,Kmeans算法实现。
算法基础
假如有一个矩阵为
这里用一个9维矩阵代表一个3*3的patch,寻找其中的中位数,实际上对应的是medfilter,对于椒盐噪音的处理真的是非常棒!
这里直介绍最简单的方法,分析如下(源于原文):
首先对窗口内的每一列分别计算最大值,中值和最小值,这样就得到了3组数据
最大值组:Max0 = max[P0,P3,P6],Max1 = max[P1,P4,P7],Max2 = max[P2,P5,P8]
中值组: Med0 = med[P0,P3,P6],Med1 = med[P1,P4,P7], Med2 = med[P2,P5,P8]
最小值组:Min0 = Min[P0,P3,P6],Min1 = Min[P1,P4,P7],Min2 = max[P2,P5,P8]
由此可以看到,最大值组中的最大值与最小值组中的最小值一定是9个元素中的最大值和最小值,不可能为中值,剩下7个;中值组中的最大值至少大于5个像素,中值组中的最小值至少小于5个像素,不可能为中值,剩下5个;最大值组中的中值至少大于5个元素,最小值组中的中值至少小于5个元素,不可能为中值,最后剩下3个要比较的元素,即
最大值组中的最小值Maxmin,中值组中的中值Medmed,最小值组中的最大值MinMax;找出这三个值中的中值为9个元素的中值。
采用上述方法,会大大降低计算量。
另外文中的另一种方法采用的是两个有序链表的找中位数的方法,充分利用有序的性质,然后直接对两个链表分别取中间数然后比较取即可,思路简单,但是很有用,毕竟二分归并排序的复杂度为O(nlogn),这里一旦有了顺序的先验理论上肯定有了加速,也就是文中曾提到的O(logn)*的复杂度,原理不难,不再赘述。
R语言笔记
本笔记实现的是对数据进行的Kmeans的聚类,博主采取技巧是在EXCEL里面先生成一个xls文件,然后输入完毕之后另存为csv格式的文件,这样可以在R语言里面直接进行读取。
Kmeans简单思想:
- 选取K个数据点作为初始聚类中心
- 将每个点收归到举起最近的质心,形成K个类
- 重新计算每类的质心
- 重复以上步骤,直到知心不再发生变化
实例操作(引用文中内容):
一组来自世界银行的数据统计了30个国家的两项指标,我们用如下代码读入文件并显示其中最开始的几行数据。可见,数据共分散列,其中第一列是国家的名字,该项与后面的聚类分析无关,我们更关心后面两列信息。第二列给出的该国第三产业增加值占GDP的比重,最后一列给出的是人口结构中年龄大于等于65岁的人口(也就是老龄人口)占总人口的比重。

笔记:
1. read.csv函数为读入相应地址的文件并命名为countries.
2. head为展现文件内容
为了方便后续处理,下面对读入的数据库进行一些必要的预处理,主要是调整列标签,以及用国名替换掉行标签(同时删除包含国名的列)。

笔记:
1. ”$“负号代表文件的次级表示,因此代码第一行为文件countries下countries这一类.
2. as.character转换变量类型,将相应内容转化为字符型内容,因此var就是对应元素的字符了。
3. dimnames就是dimensions name即为维数的名称,该实例中就是行标签 1 2 3 4 5 6,列标签为 countires, services of GDP, aged65 above of total。同时这里也表明了R语言存储框表的数据结构,即真实内容为表内的数据,而行标签和列标签与其有着明确的界限。提取的函数,有dimnames, rownames, colnames等
Note:
这里本人做了一点儿尝试代码如下:
countries = read.csv("C:/Users/DidiLv/Desktop/data.csv")
head(countries)
var = as.character(countries$countries)
dimnames(countries)[1]结果如下:
> dimnames(countries)[1]
[[1]]
[1] "1" "2" "3" "4" "5" "6"这里发现出现了“[[1]]”所以要想看清楚真正的内容为:
dimnames(countries)[[1]]
这样才是真正的内容,国家名。
下面的就是for循环,实际上就是个赋值啦,但是赋值肯定赋值到行标签上,但是,本人亲测貌似不对,所以改为以下代码,
countries = read.csv("C:/Users/DidiLv/Desktop/data.csv")
head(countries)
var = as.character(countries$countries)
rownames(countries) = var具体结果见下面输出结果:
countries services.of.GDP ages65.above.of.total
Belgium Belgium 76.7 18
France France 78.9 18
Denmark Denmark 76.2 18
Spain Spain 73.9 18
Japan Japan 72.6 25
Sweden Sweden 72.7 19
注意,最左边的列是标签,跟内容没任何关系,只是为了下面标注的时候更加明显些,接下来就是取值
类似matlab直接取列,下面就是换名了。原文中说的是删除列,实际上没删除,只是取了其中2-3列然后重新复制,最后达到了删除列的结果。
4. Kmeans函数及其画图没什么难度,毕竟都是人家电脑默默地付出而已。
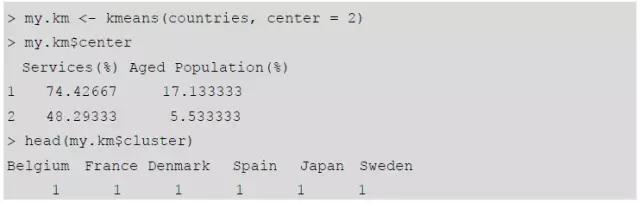
对于聚类结果,如果用图形来显示的话,可能更易于接受。下面是示例代码。

由于生成的样本少,只能看看是怎么写的了。
结束
本文只为学习笔记,欢迎讨论,大多数图片源于原文,对原作者致谢。

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









