







先来感受一下语言的魅力吧!
一帅哥去高铁站接她女朋友,女朋友给他打电话说:
要是你到了,我还没到,你就等着吧。
要是我到了,你还没到,你就等着吧!
…
这两句话什么意思,大家都懂吧,哈哈哈 ?
一、函数重载
如果同一作用域内的几个函数名字相同但形参列表不同,我们称之为函数重载(overloaded)。
- 形参列表不同:
参数个数、类型、不同类型参数的顺序- 函数重载是用来处理功能类似但是数据类型不同的问题
- 仅仅函数返回值不同,不能构成重载
- main 函数不能重载
例如:
int add(int left, int right);
double add(double left, double right);
long add(long left, long right);
这三个函数接受的形参类型不一样,但是执行的操作非常类似,当调用这些函数时,编译器会根据传递的实参类型推断想要的那个函数。
看代码:
#include <iostream>
int add(int left, int right)
{
return left + right;
}
double add(double left, double right)
{
return left + right;
}
long add(long left, long right)
{
return left + right;
}
int main(void)
{
std::cout << "[int] res = " << add(10, 20) << std::endl;
std::cout << "[double] res = " << add(10.1, 10.2) << std::endl;
std::cout << "[long] res = " << add(10L, 20L) << std::endl;
return 0;
}
编译(编译环境: CentOS 7)执行:
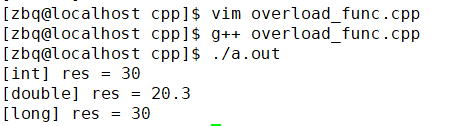
果然得到了我们想要的结果,函数重载也在一定程度上减轻了起名字、记名字的负担
下面我们测试一下仅仅返回值不同的两个函数是否能构成函数重载
看代码:
#include <iostream>
short add(short left, short right)
{
return left + right;
}
int add(short left, short right)
{
return left + right;
}
int main(void)
{
add(1, 2);
return 0;
}
编译运行(编译环境: CentOS 7):

直接报错了,没有通过编译,
证明仅返回值不同的两个函数,不能构成重载
二、C 语言为什么不支持函数重载?
我们换句说吧,为什么C++ 支持函数重载?
其实是编译器的原因,我们都知道,C语言编译器和C++编译器是完全不同的两个编译器,而C++在编译过程中对函数重命名的规则保证了重载函数在重命名后函数名的唯一性:
重命名函数名 = (返回值类型)作用域+原始函数名+参数列表
而C语言在编译过程中并不会对函数重命名。
Linux CentOS 7中,我们使用命令
objdump -d a.out > log.txt
我们把这个程序的反汇编代码放到了 log.txt 这个文件中,我们打开这个文件,看不懂没关系,我们找三行能看懂的,如下图:

int add(int left, int right) ====> _Z3addii
double add(double left, double right) ====> _Z3adddd
long add(long left, long right) ====> _Z3addll
有对比才有突出:
我们来写一段C语言代码
#include <stdio.h>
int add(int left, int right)
{
return left + right;
}
int main(void)
{
add(10, 20);
return 0;
}
编译,然后打开反汇编:

这么看,就很清晰了吧,C++ 编译器确实对函数名重写了!!!
那么我就有一个疑问了:
C++ 中能否将一个函数按照C的风格来编译?
有的朋友可能会觉得我的这个问题问的很废啊,C++ 支持函数重载,而C 语言不支持,原因是C++编译过程对函数进行重命名,而C语言编译过程中不进行函数重命名,你刚刚说了的嘛。所以肯定不行啦!
但是你有没有想过,我的这几个函数不重载,我仅仅是想在C++ 代码中让这个函数或者这几个函数按照C风格编译,其实是可以的,我们写一段代码测试一下:
#include <iostream>
char Add(char x, char y)
{
return x + y;
}
#ifdef __cplusplus
#include <stdio.h>
extern "C"
{
#endif
int add(int x, int y)
{
return x + y;
}
#ifdef __cplusplus
}
#endif
int main(void)
{
std::cout << add('a', 'b') << std::endl;
printf("%d\n", add(10, 20));
return 0;
}
编译运行:
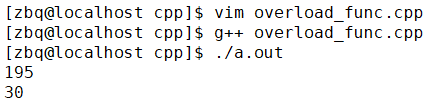
我们采用:
#ifdef __cplusplus
extern "C"
{
#endif
// ...
// n 个函数
// ...
// 注意:这里写的代码都是C语言代码,是不支持函数重载的
// C语言里代码怎么写,这里也怎么写!
#ifdef __cplusplus
}
#endif
这种方式,可以支持C和C++的混合编译!!!
三、如何解析函数重载?
- 重载函数的调用匹配
为了估计哪个重载函数最合适,需要依次按照下列规则来判断:
- 精确匹配:
参数匹配而不做转换,或者只做微乎其微的转换,如数组名到函数指针、函数名到指向函数的指针。- 提升匹配:
即整数提升(如 bool 到 int , char 到 int , short 到 int , float 到 double )- 使用标准转换匹配
- 使用用户自定义匹配
- 使用省略号匹配:… 可变参数列表
如果在最高层有多个匹配函数找到,调用者将被拒绝,因为有歧义。
看下面代码:
void print(int);
void print(const char*);
void print(double);
void print(long);
void print(char);
void h(char c,int i,short s, float f)
{
print(c);//精确匹配,调用print(char)
print(i);//精确匹配,调用print(int)
print(s);//整数提升,调用print(int)
print(f);//float到double的提升,调用print(double)
print('a');//精确匹配,调用print(char)
print(49);//精确匹配,调用print(int)
print(0);//精确匹配,调用print(int)
print("a");//精确匹配,调用print(const char*)
}
定义太少或太多的重载函数,都有可能导致模棱两可
看个例子:
#include <iostream>
void f1(char);
void f1(long);
void f2(char*);
void f2(int*);
void k(int i)
{
f1(i);//调用f1(char)? f1(long)?
f2(0);//调用f2(char*)?f2(int*)?
}
int main(void)
{
k(1);
return 0;
}
编译执行:

error: call of overloaded ‘f1(int&)’ is ambiguous
error: call of overloaded ‘f2(int)’ is ambiguous
编译器报错,将错误抛给用户自己处理
- 编译器如何解析重载函数调用

这个四个解析步骤所做的事情大致如下:
- 由匹配文法中的函数调用,获取函数名;
- 获得函数各参数表达式类型;
- 语法分析器查找重载函数,符号表内部经过重载解析返回最佳的函数
- 语法分析器创建抽象语法树,将符号表中存储的最佳函数绑定到抽象语法树上
四、调用约定
常用的调用约定;
- _cdel(C 调用约定. The default calling convention)
C/C++ 缺省调用方式:
1) 压栈顺序:函数参数从右到左
2) 参数栈维护:由调用函数把参数弹出栈,传送参数的内存栈由调用函数来维护。
3)函数修饰名约定:VC 将函数编译后会在函数名前面加下划线作为前缀
4) 每一个调用它的函数都包含清空栈的代码,所以产生的可执行文件会比调用 _stdcal 函数大
更多调用约定,请查看大佬的博客:C/C++调用约定















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









