








📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


概述
面部表情图像预处理是面部表情识别的重要步骤,主要目的是在于提取特征之前排除一切与面部表情无关的干扰因素。例如,环境光照、姿势和不同背景等。在干扰排除后,将人类面部直接与公共参考系相对接、使每个面部特征对应的语义位置精准无误。人脸检测、人脸对齐、数据增强、人脸一是实现面部表情图像预处理的主要方法。
本文所涉及的所有资源的获取方式:这里
核心逻辑
人脸检测:
# 初始化字典,并保存Haar级联检测器名称及文件路径
detectorPaths = {
"face": "haarcascade_frontalface_default.xml"
}
'''
加载Haar级联检测器:
创建一个空字典detectors,用于存储加载的检测器。
使用cv2.CascadeClassifier()加载XML文件,并将检测器存储在detectors字典中。
'''
# 初始化字典以保存多个Haar级联检测器
print("[INFO] loading haar cascades...")
detectors = {}
# 遍历检测器路径
for (name, path) in detectorPaths.items():
# 加载Haar级联检测器并保存到map
path = os.path.sep.join([args["cascades"], path])
detectors[name] = cv2.CascadeClassifier(path)
'''
图像处理:
从磁盘读取输入图像,使用imutils.resize函数将图像宽度调整为500像素。
将图像转换为灰度图以便进行人脸检测。
'''
# 从磁盘读取图像,缩放,并转换灰度图
print(args['image'])
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
'''
执行面部检测:
使用人脸检测器执行面部检测,得到面部的边界框坐标。
'''
# 使用合适的Haar检测器执行面部检测
faceRects = detectors["face"].detectMultiScale(
gray, scaleFactor=1.05, minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
'''
眼睛和嘴巴检测:
对于每个检测到的面部,分别在面部ROI中应用眼睛和嘴巴检测器,得到相应的边界框坐标。
'''
# 遍历检测到的所有面部
for (fX, fY, fW, fH) in faceRects:
# 提取面部ROI
faceROI = gray[fY:fY + fH, fX:fX + fW]
# 在面部ROI应用左右眼级联检测器
eyeRects = detectors["eyes"].detectMultiScale(
faceROI, scaleFactor=1.1, minNeighbors=10,
minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)
# 在面部ROI应用嘴部检测
smileRects = detectors["smile"].detectMultiScale(
faceROI, scaleFactor=1.1, minNeighbors=10,
minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)
多人脸检测:
Haar是一种特征描述,随着时代的进步Haar也从Haar Basic的三种简单特征扩展到了Haar-Like以及到现在的Haar Extended。但是万变不离其宗,我们笼统得把他们分成三类:中心特征,线性特征, 边缘特征。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。

Haar原来就是一些固定的特征模型,在人脸识别这个特助的领域中可以局部的契合图像特征。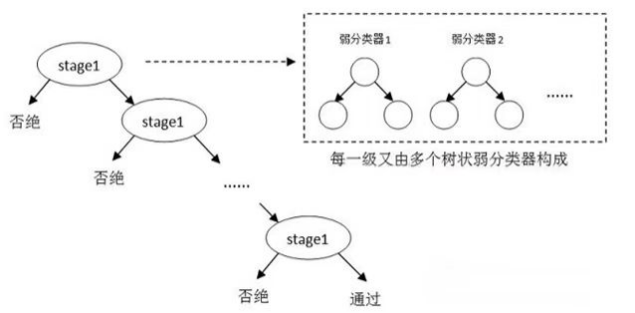
微表情识别 :
卷积神经网络,FaceCNN 类:
初始化:定义了一个包含卷积层、批量归一化、RReLU激活函数、池化层和全连接层的卷积神经网络结构。
前向传播方法 (forward):定义了模型的前向传播过程。

使用方式
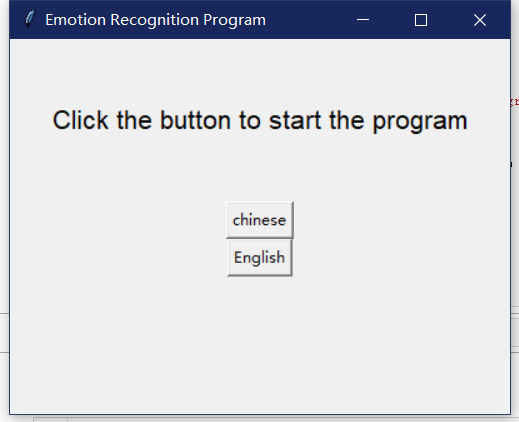
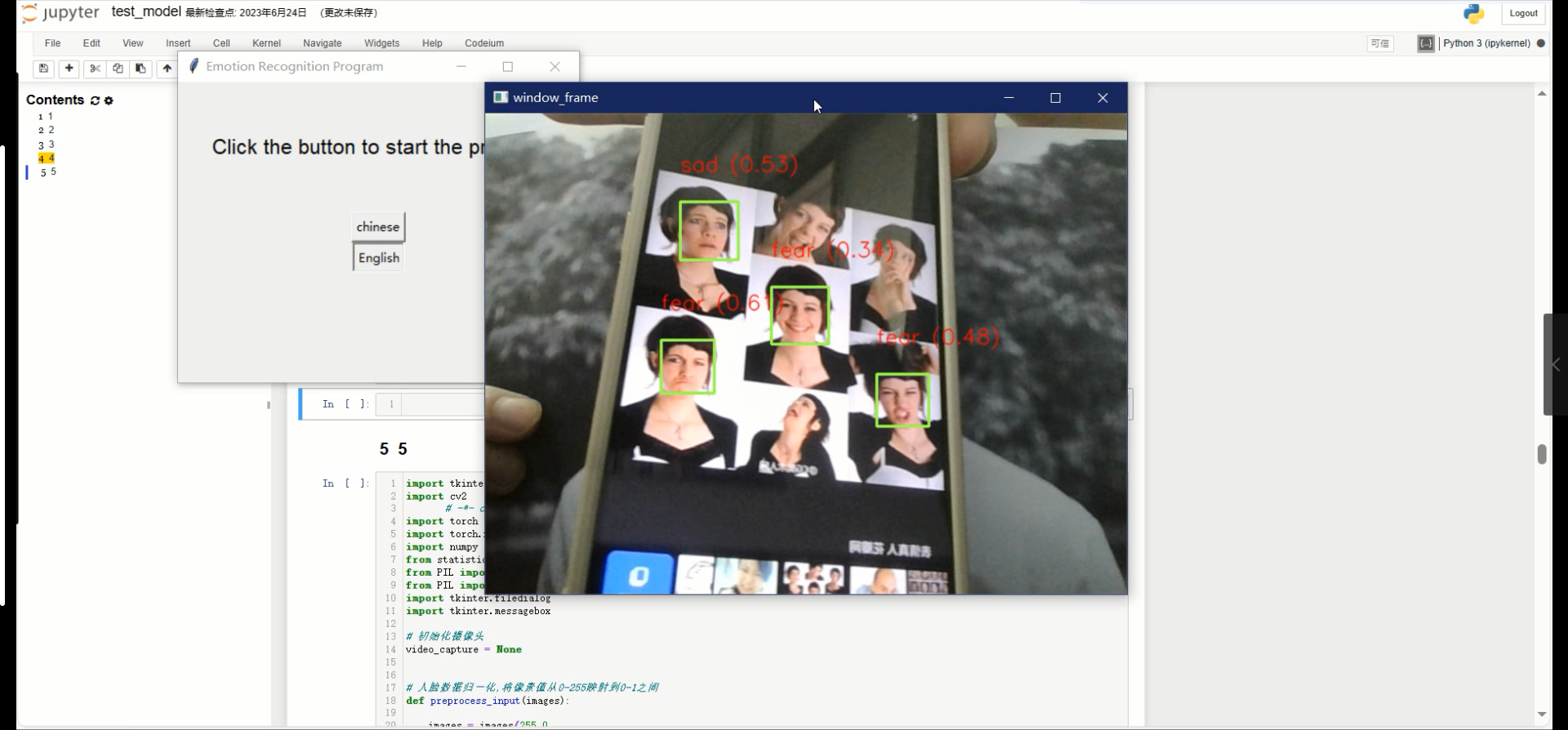
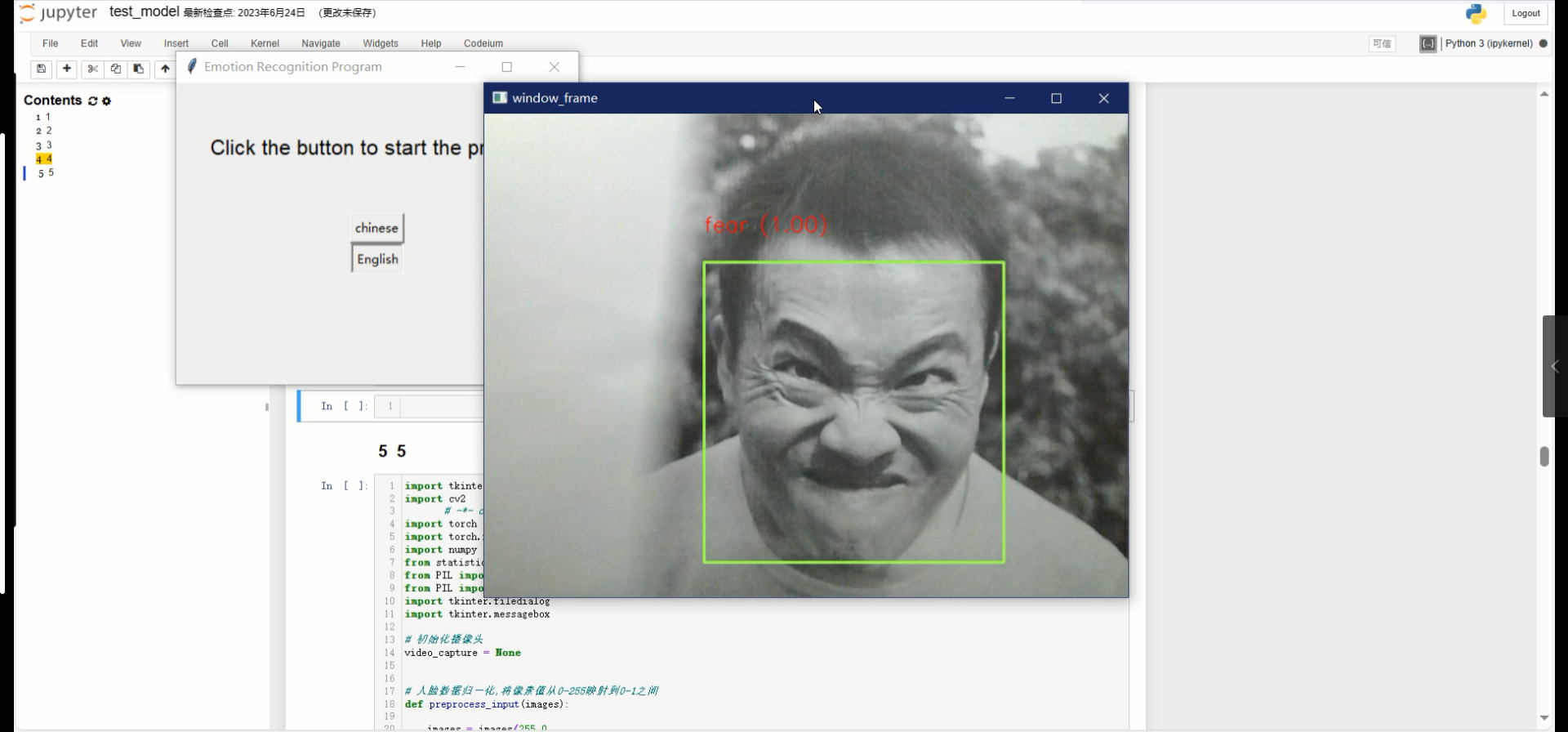
功能分别是中文显示识别结果以及用英文显示识别结果以及相应的置信度计算结果展示。
英文显示:
中文显示:
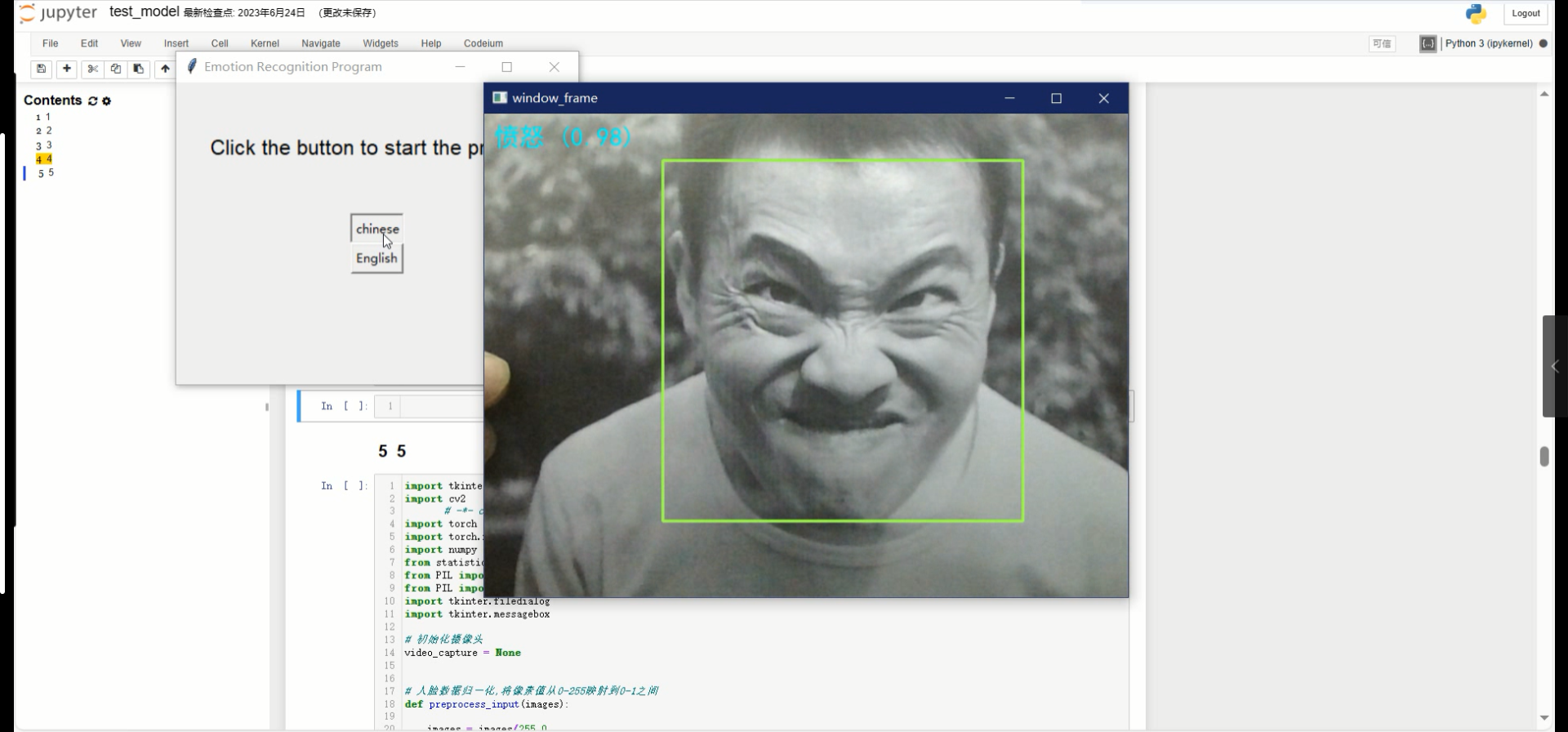
导入中文字体:
设置中文字体
font = cv2.FONT_HERSHEY_SIMPLEX
font_chinese = cv2.FONT_HERSHEY_SIMPLEX
指定中文字体文件路径,替换成你自己的中文字体文件路径
font_path = ''
font_chinese = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText()
确保你已经下载并设置好中文字体文件路径。
修改中文文字输出的位置和格式:
在矩形框上部,输出中文分类文字和置信度
text = f"{} ()"
cv2.putText()
将 cv2.putText 函数的 font 参数替换为 font_chinese,以确保使用中文字体。
置信度计算:



直接点击按钮运行,再运行界面按“z”停止程序。
模型训练文件在百度云盘下载,替换相应的相对路径位置后运行。
部署方式
main.ipynb 为运行文件。
路径文件不是相对地址,请用户自行调整路径后为项目存放地址后运行。
用户请先请阅读readme.txt文件。
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









