







根据北大TensorFlow2.0笔记的内容,总结搭建神经网络的六步法

以鸢尾花数据集实例来进行模型的搭建
import tensorflow as tf
from sklearn import datasets
import numpy as np
#导入训练集 以及训练集的标签
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
#实现对数据集的乱序
#seed( ) 用于指定随机数生成时所用算法开始的整数值。
#1.如果使用相同的seed( )值,则每次生成的随即数都相同;
np.random.seed(116)
np.random.shuffle(x_train) #打乱数据集
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
#搭建模型 神经元的个数 选用的激活函数 选用的正则化方法
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
#compile选用训练的配置方法 选择SGD优化器 学习率设置为0.1
#loss损失函数设置为SparseCategoricalCrossentropy
#from_logits=False 寻问是否是原始输出 由于前面使用了softmax激活函数的概率分布 所以是false
#metrics评测指标 如果选择accuracy 则对应情况为y_和y都是数值形式 y_=[1] y=[1]
#sparse_categorical_accuracy对应y_和y都是以独热编码或者概率分布形式给出
# y_=[1]是数值形式 但是模型输出为y=[0.256,0.695,0.048]
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
#测试集选择从训练集中划分 一次喂入多少组数据 batch_size 循环多少次
#validation_split告知从训练集中选择20%的数据作为测试集
#validation_freq 每迭代20次训练集要在测试集中验证一次准确率
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
#用summary打印出网络结构和参数统计
model.summary()
最终运行的结果



可以看到经过500次的迭代最终
训练集上的损失函数结果为0.4425,准确率 0.8583
而测试集上的损失函数结果为3130 准确率0.9667
网络结构有model.summary()可以得到
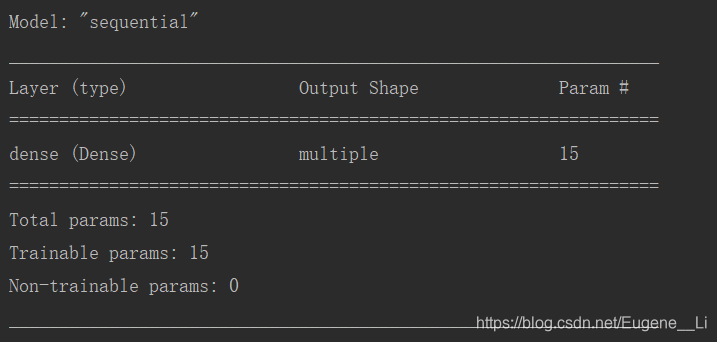
因为x_train的shape为 (150, 4)
一个隐藏层为3个神经元,所以加上偏置之后得到的参数总共为
(4+1)*3=15个参数














 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









