




 本文介绍了在TensorFlow2.0中使用卷积神经网络(CNN)处理猫狗图像的二分类模型,包括数据预处理、模型构建、训练过程、过拟合解决方案以及模型评估。通过图像增强技术,有效缓解了过拟合问题,提高了模型在验证集上的准确性。
本文介绍了在TensorFlow2.0中使用卷积神经网络(CNN)处理猫狗图像的二分类模型,包括数据预处理、模型构建、训练过程、过拟合解决方案以及模型评估。通过图像增强技术,有效缓解了过拟合问题,提高了模型在验证集上的准确性。
- Python版本: Python3.x
- 运行平台: Windows
- IDE: jupyter / Colab / pycharm
- 转载请标明出处:https://blog.csdn.net/Tian121381
- 资料下载,提取码:9bjp
一、前言
在上一部分中,我们讲解了tensorflow2.0的简单应用,会建立简单的NN,CNN模型。我们了解了如何使用CNN来提高对手写数字的识别效率。 在本部分,我们将把它带入一个新的水平,识别猫和狗的真实图像,以便将传入的图像分类为一个或另一个。 尤其是手写识别功能,因为所有图像均具有相同的大小和形状,并且均为单色,因此使的处理很简单。现实世界中的图像并非如此—它们具有不同的形状,宽高比等,而且通常是彩色的!同时,这一部分,我们也会讲解一下在具体应用中我们会遇到的问题,如过拟合,欠拟合等。
二、猫狗二分类模型
我们先按前面的知识点写一个猫狗二分类的模型,这里的图像与现实世界中的图像一致-------它们具有不同的形状,宽高比等,而且通常是彩色的!
用卷积神经网络处理更复杂的图像
因此,作为任务的一部分,需要处理数据—尤其是将其大小调整为一致的形状。
步骤如下:
- 探索猫和狗的示例数据
- 建立和训练神经网络以识别两者之间的差异
- 评估培训和验证的准确性
以下python代码将使用OS库来使用操作系统库,从而使您可以访问文件系统,并使用zipfile库来解压缩数据。
import os
import tensorflow as tf
import zipfile
读取数据
local_zip = '/content/drive/My Drive/Colab Notebooks/DateSet/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip,'r')
zip_ref.extractall('/content/drive/My Drive/Colab Notebooks/tmp')
zip_ref.close
.zip的内容被提取到基本目录/tmp/cats_and_dogs_filtered中,该目录包含用于训练和验证数据集的训练和验证子目录,该目录依次包含猫和狗的子目录。
简而言之:训练集是用来告诉神经网络模型“这就是猫的样子”,“这就是狗的样子”等的数据。验证数据集是猫和狗的图像神经网络不会作为训练的一部分,因此可以测试在评估图像中是否包含猫或狗时,神经网络的效果如何。
在此示例中要注意的一件事:我们没有将图像明确标记为猫或狗。如果还记得上面的手写示例,我们将其标记为“这是1”,“这是7”等。稍后,您将看到正在使用的称为ImageGenerator的东西-编码为从子目录读取图像,并从该子目录的名称中自动标记它们。因此,例如,将有一个“train”目录,其中包含一个“猫”目录和一个“狗”目录。 ImageGenerator将为您适当地标记图像,从而减少了编码步骤。
让我们定义以下每个目录:
#起始路径
base_dir = '/content/drive/My Drive/Colab Notebooks/tmp/cats_and_dogs_filtered'
#训练集,验证集路径
train_dir = os.path.join(base_dir,'train')
validation_dir = os.path.join(base_dir,'validation')
#训练集猫狗路径
train_cats_dir = os.path.join(train_dir,'cats')
train_dogs_dir = os.path.join(train_dir,'dogs')
#验证集猫狗路径
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
现在,让我们看一下cats和dogs训练目录中的文件名是什么样的(验证目录中的文件命名约定是相同的):
train_cat_fnames = os.listdir(train_cats_dir)
train_dog_fnames = os.listdir(train_dogs_dir)
print(train_cat_fnames[:10])
print(train_dog_fnames[:10])
结果:
['cat.127.jpg', 'cat.126.jpg', 'cat.125.jpg', 'cat.124.jpg', 'cat.123.jpg', 'cat.122.jpg', 'cat.121.jpg', 'cat.120.jpg', 'cat.119.jpg', 'cat.118.jpg']
['dog.127.jpg', 'dog.126.jpg', 'dog.125.jpg', 'dog.124.jpg', 'dog.123.jpg', 'dog.122.jpg', 'dog.121.jpg', 'dog.120.jpg', 'dog.119.jpg', 'dog.118.jpg']
让我们查看训练集和验证目录中猫和狗的图像总数:
print('total training cat images :', len(os.listdir(train_cats_dir)))
print('total training dog images :', len(os.listdir(train_dogs_dir)))
print('total validation cat images :', len(os.listdir(validation_cats_dir)))
print('total validation dog images :', len(os.listdir(validation_dogs_dir)))
结果:
total training cat images : 1000
total training dog images : 1000
total validation cat images : 500
total validation dog images : 500
对于猫和狗,我们都有1000张训练图像和500张验证图像。 现在,让我们看一些图片,以更好地了解猫和狗数据集的外观。首先,配置matplot参数:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
nrows = 4
ncols = 4
pic_index = 0
#输出8只猫,8只狗
fig = plt.gcf()
fig.set_size_inches(ncols*4,nrows*4) #图像大小
pic_index += 8
next_cat_pix = [ os.path.join(train_cats_dir,fname) for fname in train_cat_fnames[pic_index-8:pic_index] ]
next_dog_pix = [ os.path.join(train_dogs_dir,fname) for fname in train_dog_fnames[pic_index-8:pic_index] ]
#print(next_cat_pix[:10])
for i,img_path in enumerate(next_cat_pix+next_dog_pix):
sp = plt.subplot(nrows,ncols,i+1)
sp.axis('off')
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
结果:
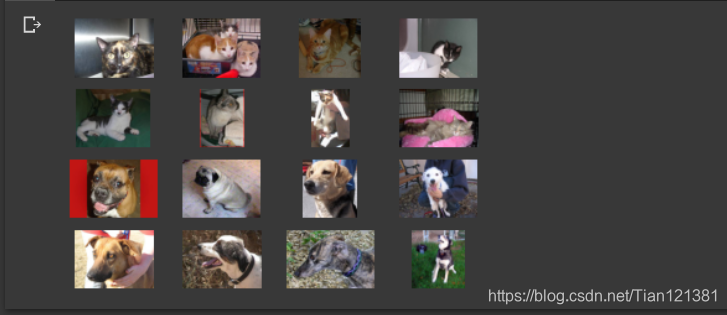
通过查看此网格中的图像可能不会很明显,但是这里需要注意的是,与上一课的显着区别是这些图像具有各种形状和大小。 在进行手写识别示例时,使用的是28x28灰度图像。这些是颜色,形状多样。在与他们一起训练神经网络之前,需要调整图像。 将在下一部分中看到。
好的,既然对数据的外观有所了解,那么下一步就是定义将要训练的模型,以从这些图像中识别猫或狗。
从零开始建立一个小模型,精度达到〜72%
在上一节中,看到图像具有各种形状和大小。 为了训练神经网络来处理它们,需要它们具有统一的大小。 因此我们选择了150x150。
让我们开始定义模型:
我们将像之前一样定义一个顺序层,首先添加一些卷积层。 注意这次输入的形状参数。 在较早的示例中,它是28x28x1,因为图像的灰度是28x28(8位,色深1个字节)。 这次大小为150x150,颜色深度为3(24位,3字节)。
然后,像前面的示例一样,添加几个卷积层,并将最终结果展平接入全连接层。
最后,我们添加全连接的层。
请注意,由于我们面临两类分类问题,即二进制分类问题,因此我们将以S型激活来结束网络,以便网络的输出将是介于0和1之间的单个标量,从而编码。当前图像是1类(而不是0类)。
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,(3,3),activation="relu",input_shape = (150,150,3)),
tf.keras.layers.MaxPool2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),activation="relu"),
tf.keras.layers.MaxPool2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),activation="relu"),
tf.keras.layers.MaxPool2D(2,2),
tf.keras.layers.Flatten() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









