






论文:《ImageNet Classification with Deep Convolutional Neural Networks》
全文翻译:https://blog.csdn.net/hongbin_xu/article/details/80271291
参考资料:https://blog.csdn.net/qq_25800609/article/details/86509645#33_29
AlexNet的特点
- 使用ReLu函数作为激活函数
- 使用dropout防止过拟合
- 使用重叠最大池化
- 提出了LRN层
- 多GPU训练
图片预处理
(1)大小归一化
将图像进行下采样到固定的256×256分辨率,给定一个矩形图像,首先缩放图像短边长度为256,然后从结果图像中裁剪中心的256×256大小的图像块
(2)减去像素平均值
所有图片的每个像素值都减去所有训练集图片的平均值
网络结构
1. 使用ReLu函数作为激活函数
对一个神经元模型的输出的常规套路是,给他接上一个激活函数:
f
(
x
)
=
t
a
n
h
(
x
)
f(x)=tanh(x)
f(x)=tanh(x)或者
f
(
x
)
=
(
1
+
e
−
x
)
−
1
f(x)={(1+e^{−x})}^{−1}
f(x)=(1+e−x)−1。就梯度下降法的训练时间而言,这些饱和非线性函数比非饱和非线性函数如f(x)=max(0,x)慢得多。使用ReLUs做为激活函数的卷积神经网络比起使用tanh单元作为激活函数的训练起来快了好几倍。如下图所示,该图展示了对于一个特定的四层CNN,CIFAR-10数据集训练中的误差率达到25%所需要的迭代次数。从这张图的结果可以看出,如果我们使用传统的饱和神经元模型来训练CNN,那么我们将无法为这项工作训练如此大型的神经网络。

2. 局部相应归一化(LRN层)
提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
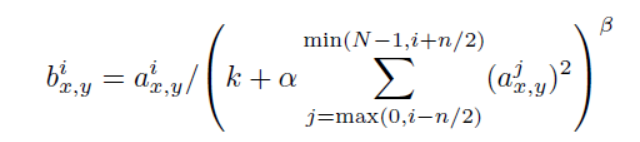
3.使用重叠最大池化
此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且一般的池化层因为没有重叠,所以步长和池化核尺寸一般是相等的,而在AlexNet中提出让步长比池化核的尺寸小,那么就会产生覆盖的池化操作,提升了特征的丰富性,得到更准确的结果。在top-1和top-5中使用覆盖的最大池化操作分别将错误率降低了0.4%和0.3%。论文中说,在训练模型过程中,覆盖的池化层更不容易过拟合。
4.整体框架结构

 这幅图分为上下两个部分的网络,论文中提到这两部分网络是分别对应两个GPU,只有到了特定的网络层后才需要两块GPU进行交互,这种设置完全是利用两块GPU来提高运算的效率,其实在网络结构上差异不是很大。为了更方便的理解,我们假设现在只有一块GPU或者我们用CPU进行运算,我们从这个稍微简化点的方向区分析这个网络结构。网络总共的层数为8层,5层卷积,3层全连接层。
这幅图分为上下两个部分的网络,论文中提到这两部分网络是分别对应两个GPU,只有到了特定的网络层后才需要两块GPU进行交互,这种设置完全是利用两块GPU来提高运算的效率,其实在网络结构上差异不是很大。为了更方便的理解,我们假设现在只有一块GPU或者我们用CPU进行运算,我们从这个稍微简化点的方向区分析这个网络结构。网络总共的层数为8层,5层卷积,3层全连接层。
第1层:卷积层1,输入为 224×224×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11×11×3;
stride = 4, stride表示的是步长, pad = 0, 表示不扩充边缘;然后进行 LRN, 后面跟着池化pool_size =
(3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map 第2层:卷积层2,
输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5×5×48;
pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3),
stride = 2; 第3层:卷积3, 输入为第二层的输出,卷积核个数为384, kernel_size = (3×3×256),
padding = 1, 第三层没有做LRN和Pool 第4层:卷积4, 输入为第三层的输出,卷积核个数为384, kernel_size
= (3×3), padding = 1, 和第三层一样,没有LRN和Pool 第5层:卷积5, 输入为第四层的输出,卷积核个数为256, kernel_size = (3×3), padding = 1。然后直接进行max_pooling, pool_size = (3,
3), stride = 2;
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
减少过拟合
1.数据增强(Data Augmentation)
方法一:水平翻转和图像变换(随机裁剪)
训练时,从256×256图像中随机提取224×224的图像块(及其水平映射),所以数据增大了
(
250
−
224
)
2
=
2048
(250-224)^2=2048
(250−224)2=2048倍。在测试时,网络通过提取5个224×224的图像块(四个角块和中心块)以及它们的水平映射(因此总共包括10个块)来进行预测,并求网络的softmax层的上的十个预测结果的均值。
方法二:在整个ImageNet训练集的图像的RGB像素值上使用PCA。对于每个训练图像,我们添加多个通过PCA找到的主成分,大小与相应的特征值成比例,乘以一个随机值,该随机值属于均值为0、标准差为0.1的高斯分布。
2.使用dropout防止过拟合
训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
训练细节
使用随机梯度下降法来训练模型,每个batch有128个样本,动量(momentum)为0.9,权重衰减(weight decay)为0.0005。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









