








概要:本篇文章提出了 一种无监督域自适应SIFA网络(图像与特征协同对齐)可以使分割网络有效的适应无标签的目标域(注意目标域无标签,源域有标签),旨在解决测试数据集在已通过训练数据集训练的分割网络上效果不佳的问题
域自适应:通过利用在训练数据集中得到的知识来提高模型在测试数据集上的性能
无监督域自适应的目标域不需要标签(无需标签,十分适用于医学图像,额外标签需要专业知识且价格昂贵),现有的无监督域自适应方法有两种,①图像对齐 ②特征对齐。本文同时使用以上两种方法,协同作用提高域自适应的性能
创新点:①在统一的框架中,同时利用图像对齐和特征对齐的优势,在互补协同作用下来提高域自适应的性能 ②MRI和CT图像之间可以双向转换③无监督,无需额外的标签④图像转换和分割网络共享编码器,参数共享,二者协同作用(反馈)达成更好的效果

上图为文章框架图,蓝色代表源域数据流 红色代表目标域数据流
图像对齐(应该可以理解为跨模态合成图片 只是图片没有输出 而是喂给了分割网络)

Gt和Dt用于图像对齐,转换源域图像外观生成类目标域图像,向Gt输入Xs 输出Xs->t,
Gt(Xs)=Xs->t
Dt用于鉴别生成的目标域图片还是真实的目标域图片

注意文中原句:转换来的图像应与目标域图像类似,但具有结构语义的原始内容要保持不变!


反向生成器Gs=E+U E为特征编码器 U为上采样解码器 Gs(Xs->t)=Xs->t->s Gs(Xt)=Xt->s

Ds用于鉴别是合成的源域图像还是真实的源域图像 Gs用于鉴别图片是Xs->t-s还是Xt->s,Ds如果成功分类 证明生成的图片Xs->t-s、Xt->s中包含S域和T域的特征

分割网络=E+C 特征编码器E+分类器C组成分割网络

文中提到分割网络使用{Xs->t,Ys}训练 可能就是所说的有监督机制
特征对齐

论文中介绍特征空间是高维空间,难以直接对齐,因此将特征空间映射到两个紧凑的低维空间(①语义预测空间 ②生成的图像空间),使用对抗性学习来增强特征分布的域不变性
语义预测空间
鉴别器Dp用于分类Xs->t 还是Xt的输出,语义预测空间代表人体解刨结构的信息,在不同成像模式下是一致的。如果特征对齐较好,说明则鉴别器无法分辨。当特征对齐效果不佳时,对抗性梯度反向传播到encoder编码器,最小化Xs->t和Xt之间特征分布的距离。
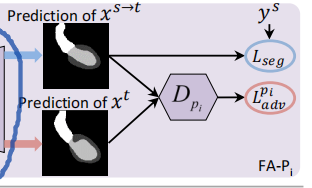
分割网络使用{Xs->t,Ys}训练 可能就是所说的有监督机制

生成图像空间
Gs用于鉴别图片是Xs->t-s还是Xt->s,即鉴别图片来自于Xs->t 还是来自Xt。

如果Gs能成功区分,说明生成的图片Xs->t、Xt中包含原始域(注意是其最初的域)的特征,符合下面的图片中原文


缺点:①本文使用二维网络进行图像分割任务,在三维模型中同时实现图像和特征对齐尚未被探索②源域和目标域中的数据量相对平衡,对不平衡数据集以及只有有限数量的目标域数据的有效无监督域适应效果未知

















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











