







Cross-modal Bidirectional Translation via Reinforcement Learning
先说说这篇文章是做什么的,做跨模态的翻译,但是这里也没有翻译的亚子,只是能给文本呢以及图片选择匹配度最高的对象打个分。先看网络架构
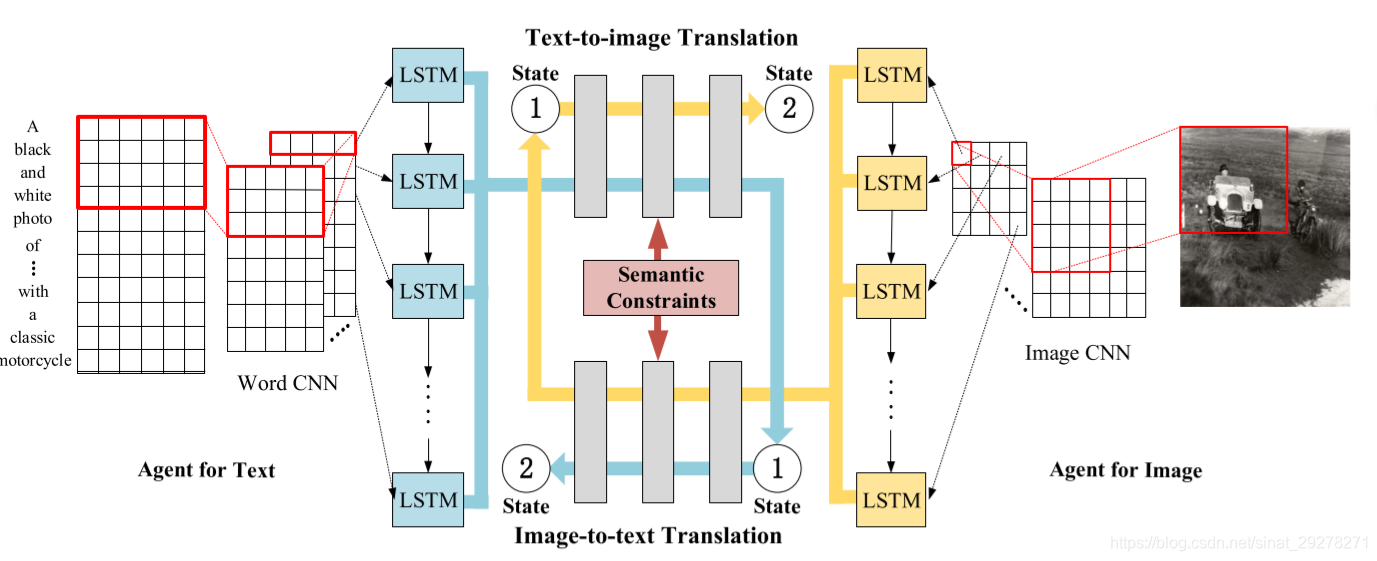
左边是一个textCNN, CNN 丢出输出后,丢给LSTM,LSTM 处理后,将所有的隐层加起来作为表征。而右边是一个CNN, CNN处理后把特征图(按图上理解)拉成一个长条也是喂给一个LSTM,中间饥饿几个全连接层用于翻译。我觉得右边在表征过程中应该丢失了一些空间信息的,因为按行拉长的话,本来两行之间距离很近的像素会距离在LSTM中距离会很长。第一行第一个第二行第一个的距离会很远。
而且,CNN+LSTM这种东西就很神奇,把词向量铺开之后,每个句子其实就是一个矩阵,右边的图片也是矩阵,应该是可以用同样的方式去做的。但这里左边CNN+LSTM,右边CNN+LSTM两个地方的CNN是不一样的,可以看到左边的卷积层宽度是一个词向量的长度。
我觉得这篇文章有用的想法就是,这里的损失函数是双向的,将左边文本空间的表征A通过一个全连接层f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3220
3220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









