







stable diffusion web ui地址
https://github.com/AUTOMATIC1111/stable-diffusion-webui
在项目readme里面找到Installation and Running,可以用colab在线使用,无需配置环境**(前提是可以连上Google)**
点击List of Online Services
跳转到有多种不同人维护的colab在线仓库
地址给到下面
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services
这里我们选择第二个maintained by camenduru
地址给到下面
https://github.com/camenduru/stable-diffusion-webui-colab

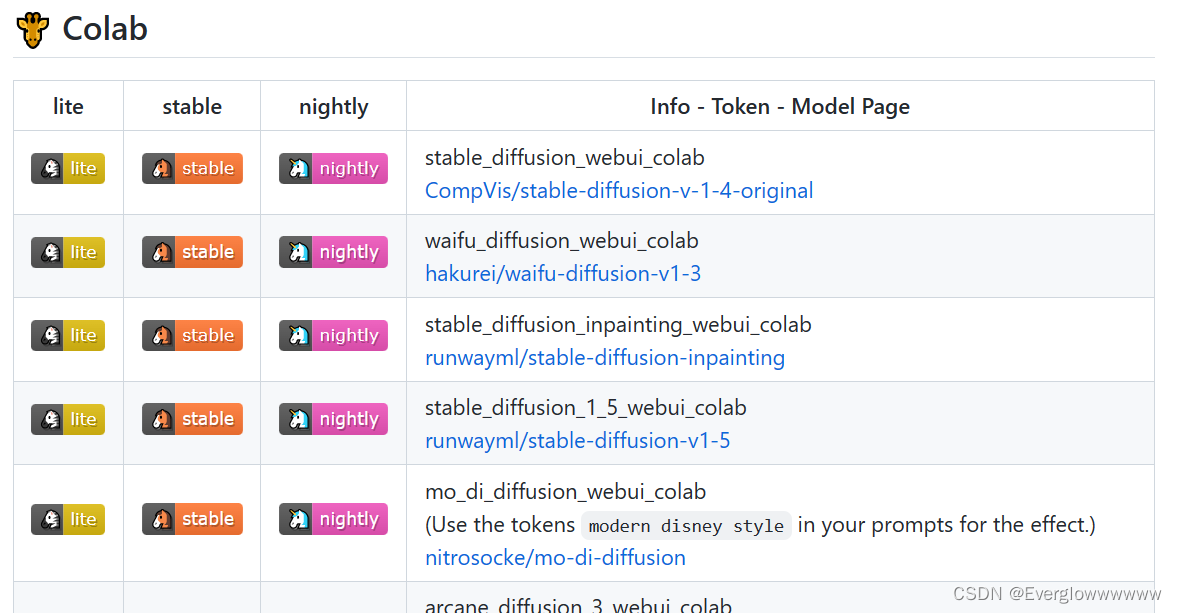
下拉readme,可以看到如下表格,lite、stable、nightly三个版本的区别在上面有介绍,这里选择第一行stable版本的,点击后跳转进入colab
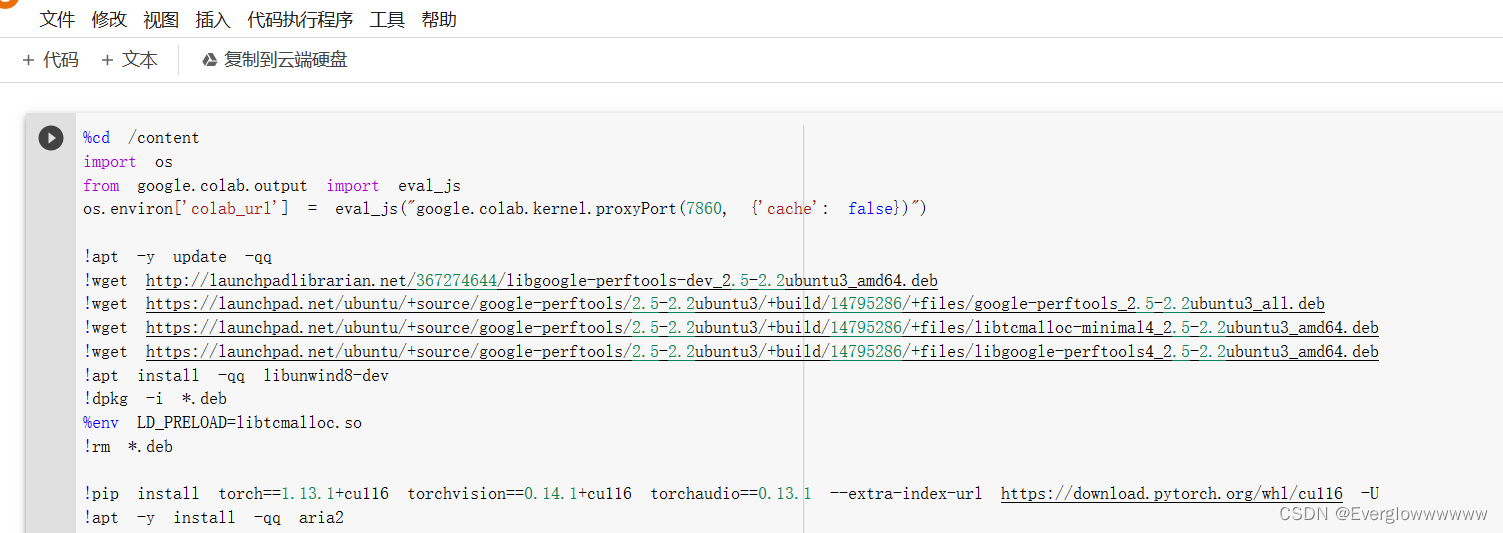
可以看到如下代码,只有一个代码块,colab运行代码之前要先登录,没有号用手机注册一个
登陆了先别急,要在代码执行程序里更改运行时类型,这样才能跑stable diffusion web ui
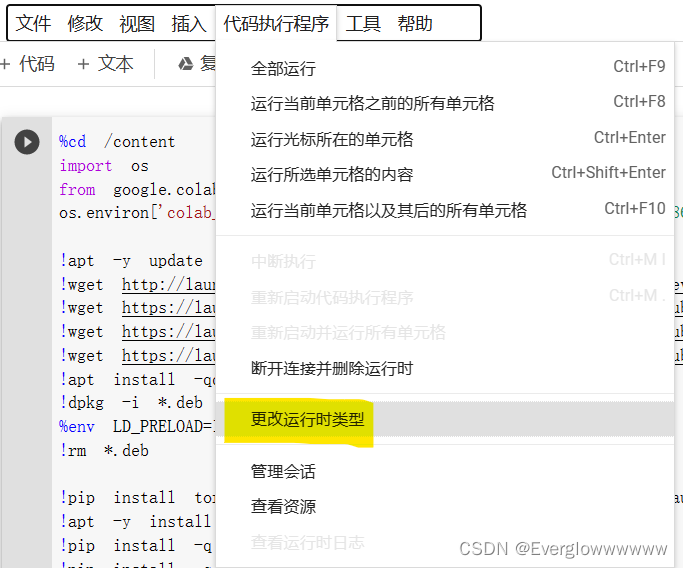
改成GPU
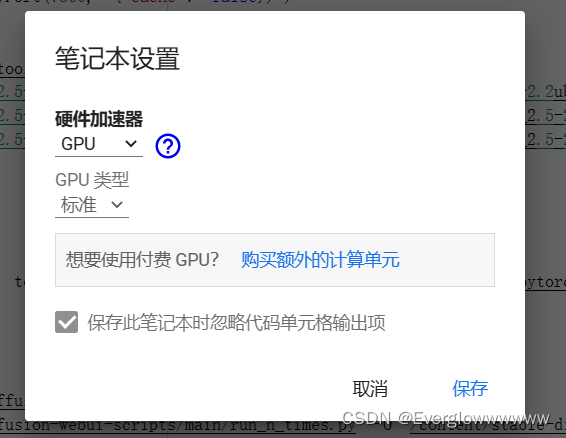
更改了之后就可以运行了(会警告非本地文件,选择仍要运行即可)
等待几分钟后,可以看到输出了两个链接,点下面这个后缀是.com的,点击后会自动跳转,等一会才能加载出

可以看到stable diffusion web ui界面显示在网页中了
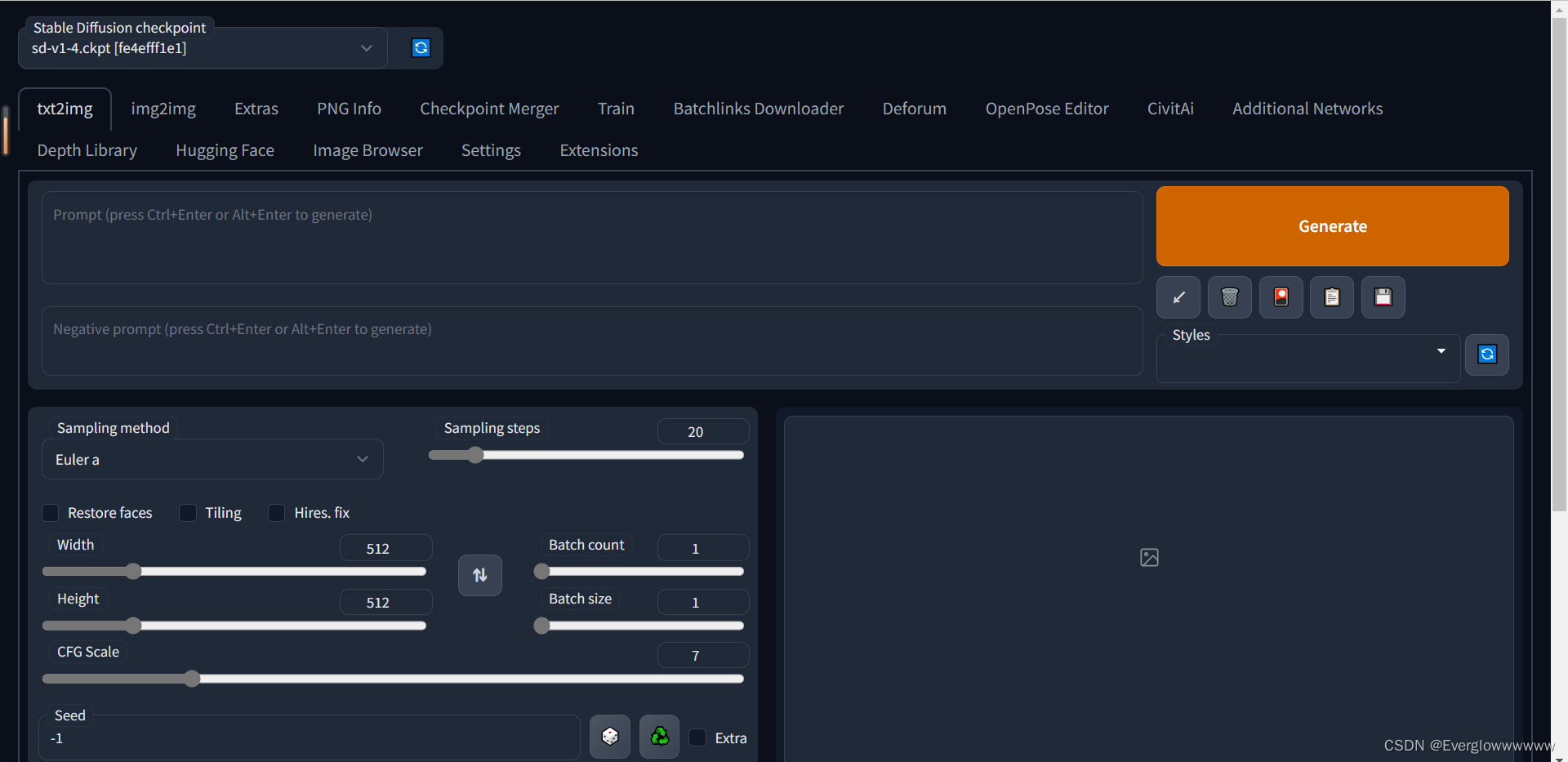
下面就可以开始ai绘图了~
要载入lora模型绘图之前,要下载基础模型ChilloutMix。点击导航栏里的civitai

按照下面标的顺序填写信息,我们现在要下载的是ChilloutMix,ChilloutMix属于Checkpoint类型,勾选Search by term?,然后在Search Term里面输入ChilloutMix,然后点get list就会搜索到ChilloutMix这个模型,然后再选择需要的版本,然后再选择Model Filename。Trained Tags (if any)和Download Url都是自己填充的。
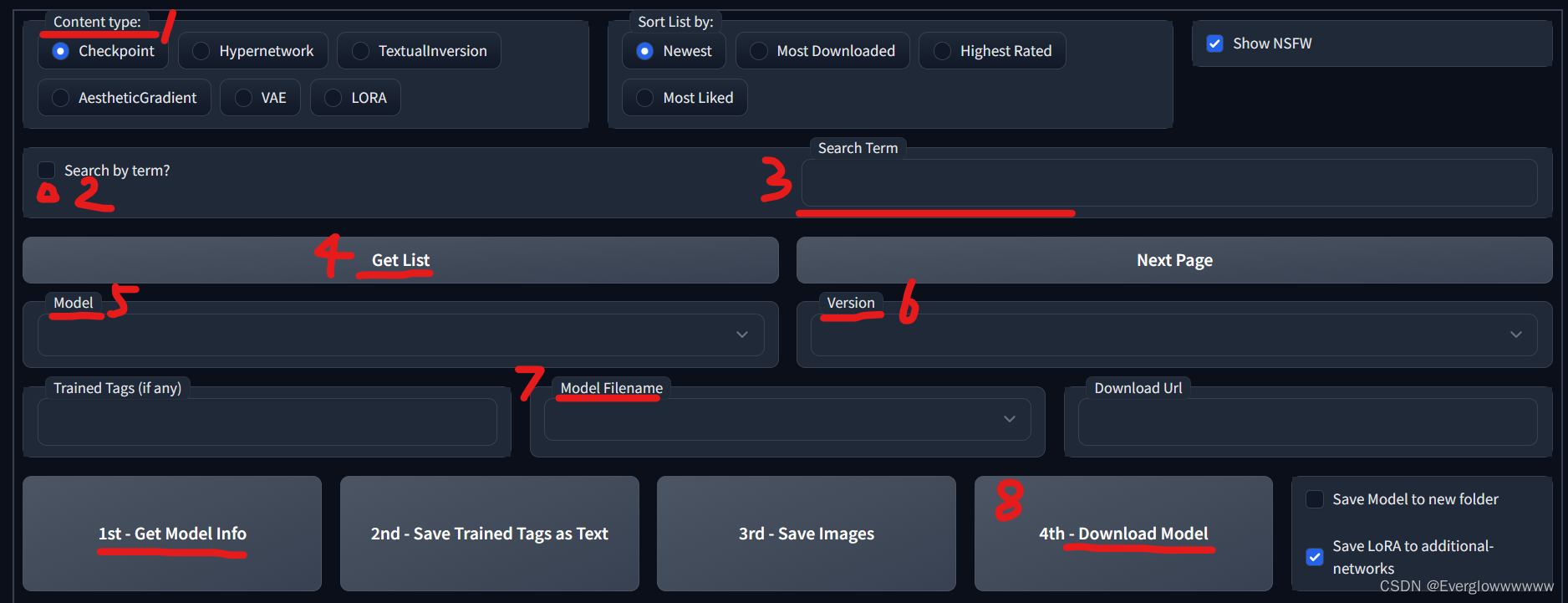
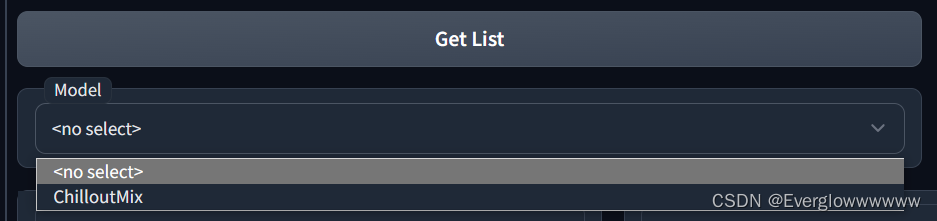
信息填写完毕后,点击4th - Download Model,后台就会下载模型,可以切回到colab页面里看下载进度。


等到下载完后,页面的左上角就可以切换到我们刚才下载的ChilloutMix模型了。
后面下载lora模型一是一样的方法,类型改成lora就行,然后根据自己想要的模型搜索term即可。
在civitai看到合适的模型,可以在此处复制别人的prompt
civitai网站
https://civitai.com/
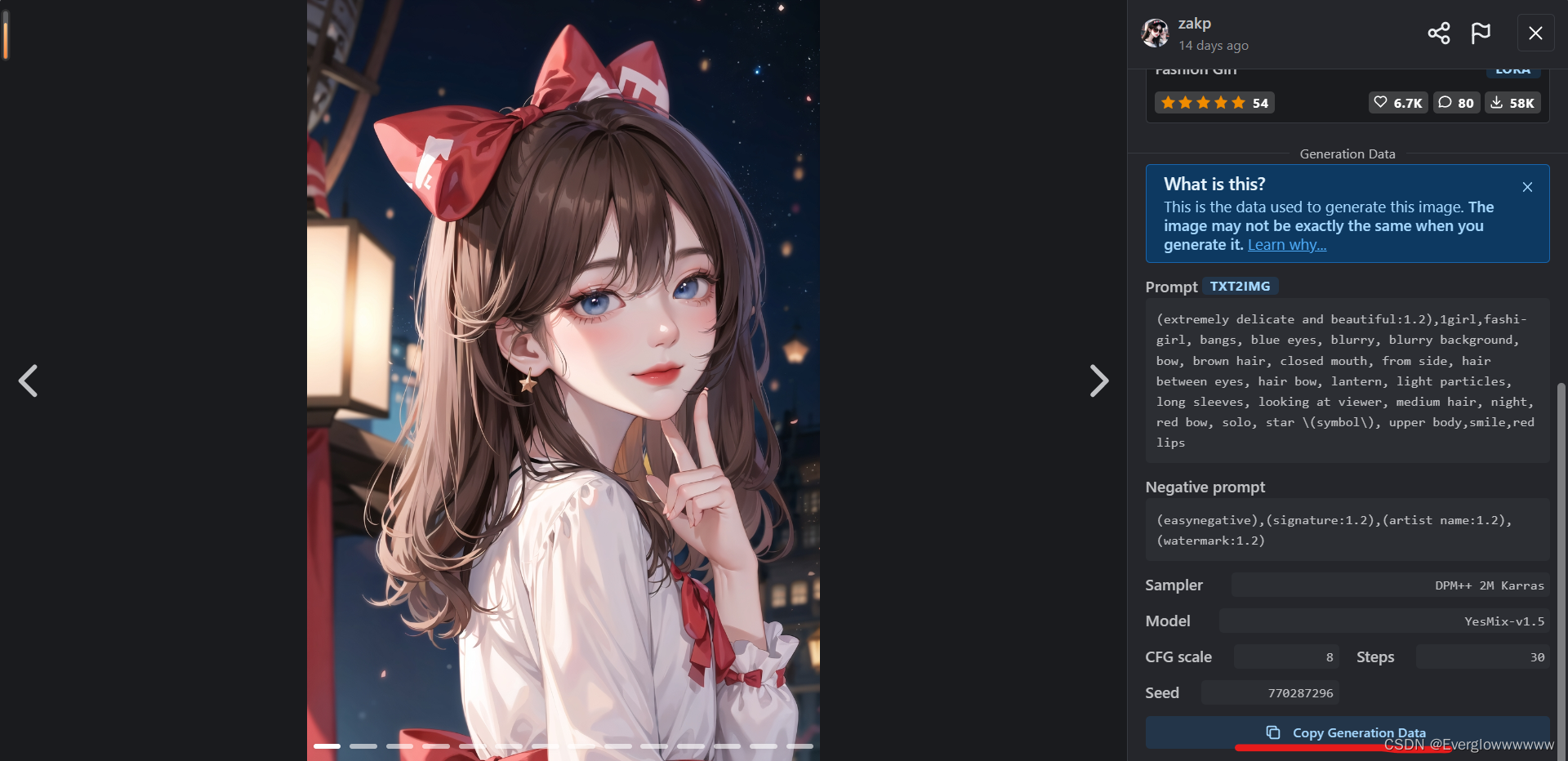
全部粘贴到1所在的框中,然后点击2就可以解析粘贴的文本,自动填充。填充好后了点击generate就可以生成想要的图片~


















 3667
3667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









