






OpenAI 的“12 Days of Shipmas”渐渐变得没什么看点啦,就在昨晚,它仅仅发布了一个炒冷饭的 AI 搜索。
然而,一直被 OpenAI 压制的谷歌,却悄悄地发布了其全新的视频生成模型 Veo2 ,还有改进版的 Imagen 3 ,以及非常好玩的混图工具 Whisk 。在上周发布了 Gemini 2 之后,谷歌再次压过了 OpenAI 一头,连续第二周夺走了 OpenAI 的风头呢。

在漫长的时光里,网友们许的愿似乎总是石沉大海,仿佛被遗忘在角落。然而,这一次,他们的愿望终于迎来了奇迹般的应验。那一瞬间,仿佛黑暗中的一束光,照亮了他们的期待,让他们感受到了命运的眷顾,心中满是惊喜与感慨,这一次,愿望真的实现了。

Veo 2 着实厉害呀,它能够生成高达 4K 分辨率且长达 2 分钟的视频呢。瞧,那原本被寄予厚望的 Sora 呀,脸好像被打得“piapia”的。快来瞧瞧这 4K 的效果呀,好多人都说,这就是他们心中想象中 Sora 的模样呢。单独拿一个我觉得特别炸裂的视频来说,这视频有运镜,有灯光,还有远景,虽说肯定是抽卡出来的,但这效果简直无敌了。
还有呀,谷歌特意放出 3 个失败的例子,那可都是相当惊艳的呢,我都怀疑谷歌是故意的,就看着大家,一边偷笑一边放这些例子,还说“尽管 Veo 2 取得了令人难以置信的进步,但创建逼真、动态或复杂的视频,在复杂场景或复杂运动的场景中保持完全一致性仍然是一项挑战”,估计 Sora 的脸都疼啦。
另外,还有些提示词呢,像用广角静态镜头展现整个滑板公园,落日余晖在公园投下长长的、戏剧性的阴影,让滑板运动员对最后一个最具挑战性的技巧充满期待;还有跟踪镜头跟随着身着飘逸白色服装的滑冰运动员在仿佛漂浮在云层中的溜冰场滑行,每一步都荡漾起波纹,背景是旋转的画布和飘动的云朵,营造出超凡脱俗的奇妙感。
而谷歌选了目前最好的 4 个视频生成模型来和 Veo 2 进行人工盲测,在人类偏好度和提示词遵循度上都取得了最好的成绩呢。
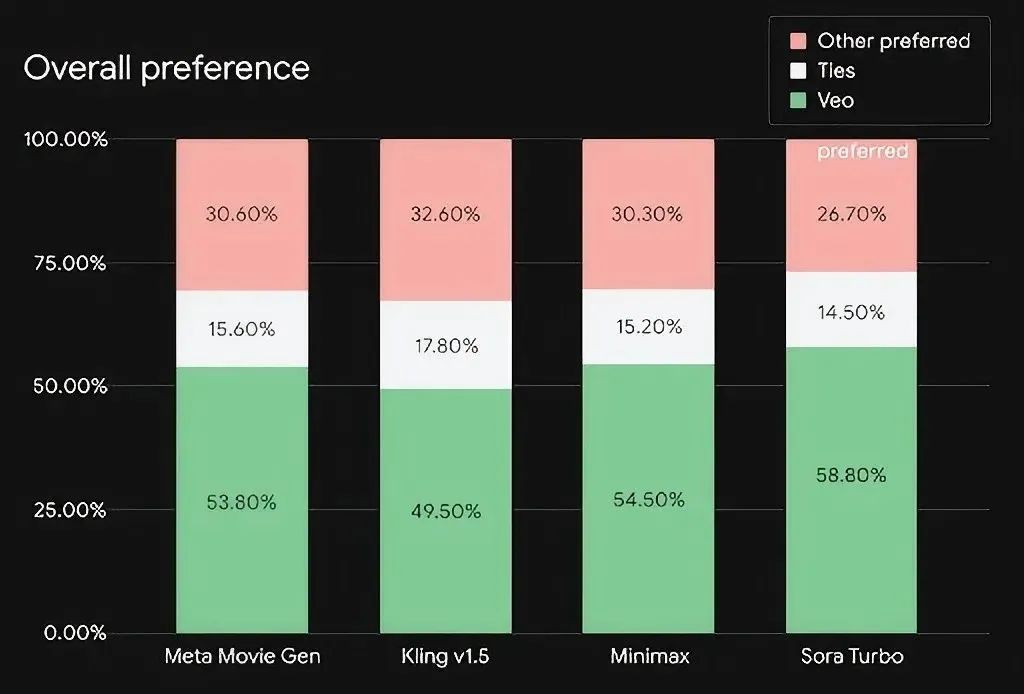
这四个模型分别是 Meta 的 MovieGen、国产的海螺以及可灵,还有 OpenAI 的 Sora Turbo 呢。谷歌在 Meta 发布的基准数据集 MovieGenBench 上,运用了 1003 个提示词,然后生成了相应的视频哦。并且呀,所有的比较都是在 720p 分辨率下进行的呢。其中,Veo 的采样时长为 8 秒,VideoGen 的采样时长是 10 秒,其他的型号采样时长则为 5 秒。
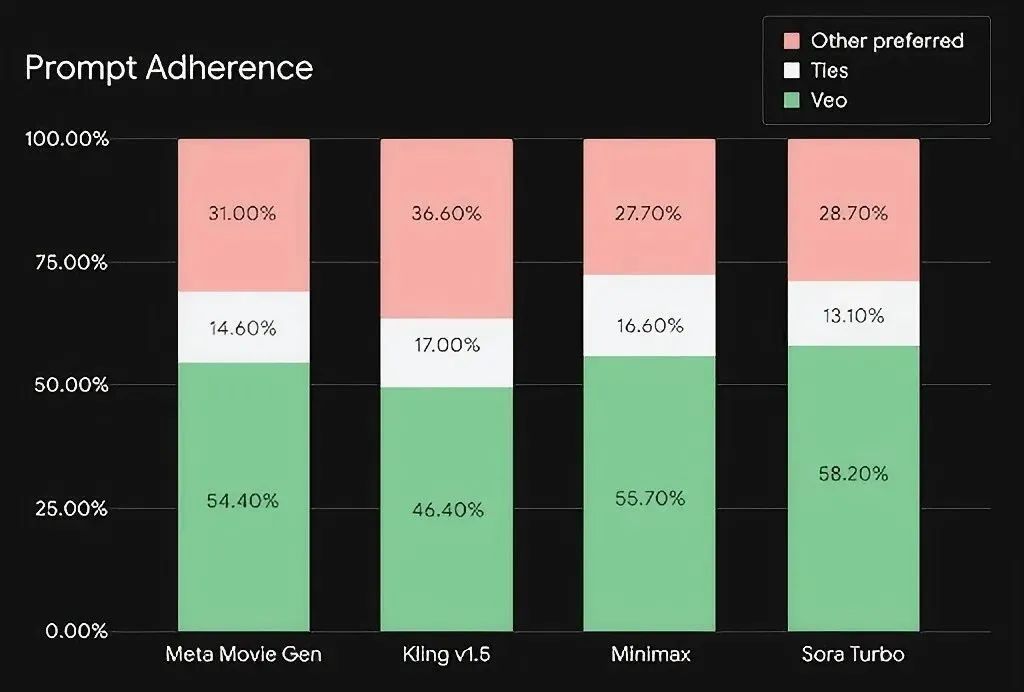
在人工盲测的情境中,绿色意味着 Veo2 表现更优,白色表示两者难分伯仲,红色则代表对比模型比 Veo2 更出色。很值得一提的是,在这 5 个模型里,可灵 v1.5 的表现竟然仅仅次于 Veo2 呢,而 Sora Turbo 呀,除了在提示词遵循方面比 MiniMax 的海螺稍微好那么一点之外,其他方面都处于垫底的位置啦。
再说 Imagen 3 ,它在年中就已经发布啦,这次的发布改进主要体现在亮度和活力上,还有多样的艺术风格以及高保真的细节呢,尤其是在整体色彩平衡方面有了更好的表现。

提示词描绘了一位亚洲女性的肖像,其背景是霓虹绿灯,景深较浅,营造出一种独特的氛围。同时,它还强调了要更精确地呈现各种艺术风格,涵盖了从照片现实主义到印象派,从抽象到动漫等多种风格,仿佛要将各种艺术韵味都融入其中,展现出丰富的艺术表现力。

这一提示词勾勒出了一幅极具特色的画面。采用高预算动画电影风格,有着鲜明的绘画质感,展现出广阔的天体景观,那鲜艳的紫色、蓝色和金色发光星云,仿佛能将人带入神秘的宇宙之中。主角是身着飘逸斗篷、装饰着星星图案的娇小女性,站在水晶悬崖边缘,下方熔化的星尘河流过银河系,金色光芒闪烁着动感。高耸的星座形似神话中的野兽,用发光虚线勾勒,流星划过浩瀚天空,为场景增添了动感与光彩。而“更丰富的纹理和增强的细节”则进一步强调了在画面表现上会更加细腻和精致,让整个场景更加栩栩如生。

这组提示词为我们呈现了黎明时分雾蒙蒙的 20 世纪 40 年代欧洲火车站景象。精巧的锻铁拱门和雾蒙蒙的玻璃窗环绕四周,蒸汽与浓雾交融。一对恋人在火车旁深情相拥,背后是昏暗灯笼温暖的琥珀色光芒,即将离去的火车部分可见,红色尾灯渐消于雾气中。女人身着褪色红外套,手抓小皮日记本,男人穿着饱经风霜的士兵制服,灰尘在空中漂浮被柔和金色背光照亮,气氛忧郁而永恒。
我自己生成了几幅这样的画面,效果超棒,提示词遵循得很好呢。Imagen 3 的特点就是写入提示词后会自动增强,特别让我印象深刻的是,即便远景中的人物,细节也毫无失真,色彩饱和度和细节丰富度都极佳。最关键的是,它还是免费的,甚至没有积分限制,这真的很棒呀。

这组提示词描绘了一幅极具艺术感的画面。轮廓艺术的展现令人惊叹,那是一位带有飘渺女性风元素的形象,飘长长发且齐刘海,头发由烟雾制成,呈现出半透明、飘渺的质感,还凝聚着烟雾的细纹。这是一幅特写肖像,背景为暗色调,营造出一种神秘而深邃的氛围,仿佛将人带入了一个梦幻般的世界。

这组提示词构建出了一个温馨而独特的场景。毛茸茸的北极熊普鲁西,那柔软的毛发仿佛能触碰到人心,此刻它正安然睡在极简主义的现代公寓床上。这个场景中,极简主义的床与毛茸茸的北极熊形成了鲜明的对比,一方面展现出现代公寓的简洁与素雅,另一方面又凸显出北极熊的可爱与憨态,仿佛在这宁静的空间里,它们共同演绎着一段静谧而美好的故事。

这组提示词生动地描绘了一幅美丽的画面。太阳缓缓升起,在那风景如画的海滩上洒下日出的光芒,一位身着漂亮简单夏装的女人安静地坐在一颗巨大的心形图案中间,而这颗心正是画在沙滩之上。周围是巨石从水中升起的壮丽景象,整个画面犹如一幅丰富而复杂的油画,那色彩是由数字精准捕捉的,构图也十分优秀。尤其是周围绿松石般的海洋,闪烁着强烈而柔和的高光,整个画面呈现出迷人的蓝色调,仿佛将人带入了一个梦幻般的世界。
而关于 Imagen 3 与其他图像生成模型的对比盲测,想必会在这样独特的场景设定下展现出各自的特点与优势,让人充满期待。
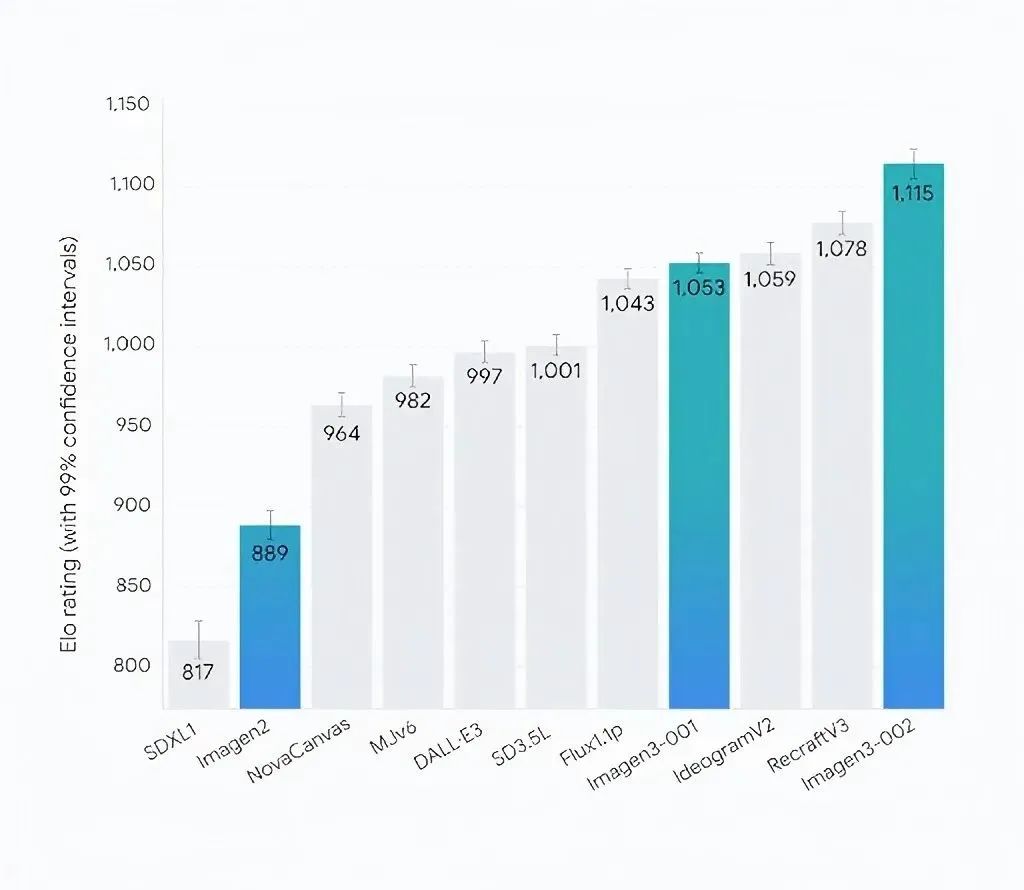
Imagen 3 在与其他图像生成模型的对比中,在整体偏好基准上的 Elo 得分最为突出。它展现出了独特的优势,在图像生成领域具有较高的影响力。
而 Whisk 这个工具,主要功能是用于混和图像生成。它像是一个图像处理的小助手,能够将不同的图像元素进行巧妙的融合,为图像创作带来更多的可能性。
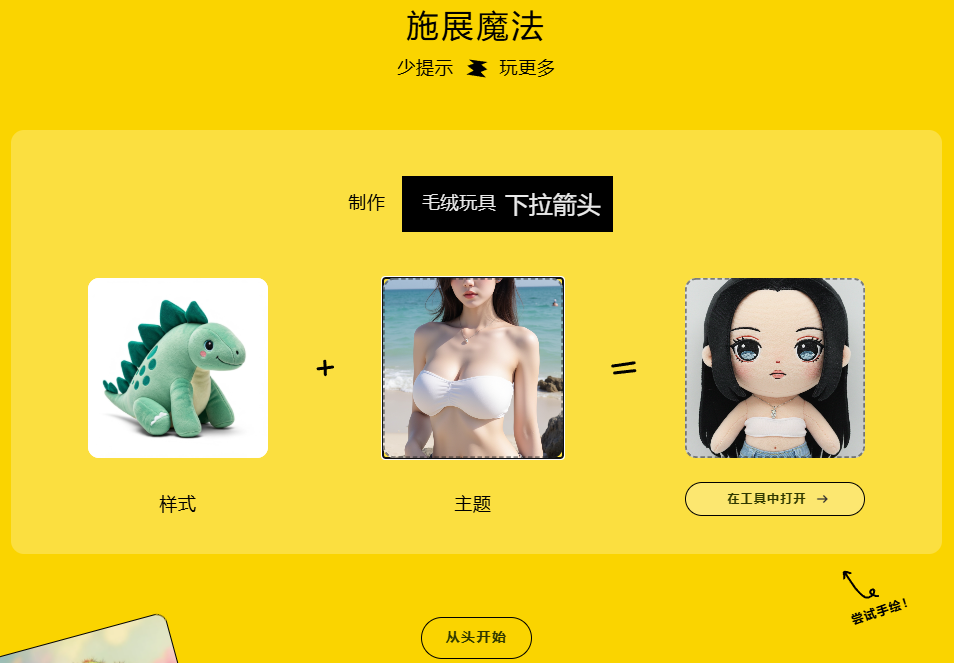
可以这样理解,它具备将三张不同类型的图片进行混合生成新图像的能力。一张人物或物品的主题图片,能为混合后的图像提供主体元素;一张风格类型的图片,赋予整个图像特定的风格特质;还有一张场景图,决定了图像所呈现的背景环境。
就像我所做的那样,用一张人物图,它赋予了混合的基础;加上一张毛线玩偶风格的图片,让整个图像带上了独特的风格韵味;再加上一张餐厅场景图,如此一来,就混合生成了一个以毛线玩偶风格的人物在餐厅场景中的新图像,仿佛创造出了一个全新的视觉世界。

仿佛有一股神奇的力量在驱使,一张全新风格的人物图在餐厅中缓缓呈现。这个人物身着独特的服饰,线条流畅而富有韵律,仿佛是从另一个时空穿越而来。他的发型奇特而别致,每一根发丝都仿佛在诉说着故事。在餐厅的灯光下,他的身影被拉得长长的,与餐厅的环境融为一体。餐厅的布置充满了艺术气息,墙壁上挂着抽象的画作,餐桌摆放得错落有致,餐具闪烁着微光。这个新风格的人物就像是餐厅中的一道独特的风景,吸引着人们的目光,让人仿佛置身于一个梦幻般的世界之中。

不仅可以通过图片的组合来生成新图,还能借助文字进行细化呢。就如同之前的那张图,若觉得它不像毛线玩偶的风格,只需写下提示词“一个毛线玩偶的芭比娃娃”,就能让其风格更加明确。而且还可以更换场景,比如将餐厅场景换成花园场景,让那毛线玩偶的芭比娃娃置身于繁花似锦的花园之中,阳光透过树叶的缝隙洒在她身上,仿佛她也成为了这花园中的一部分,如此一来,整个画面的意境和氛围都将发生巨大的变化,变得更加生动和富有想象力。

当写下“一个毛线玩偶的芭比娃娃”这样的提示词并更换场景后,仿佛有一种神奇的魔力在起作用。之前不太符合毛线玩偶风格的图,此刻逐渐变得更加贴合,那芭比娃娃的形象仿佛真的被赋予了毛线的质感,每一处线条、每一个细节都透露出毛线的柔软与温暖。而更换后的场景,无论是花园还是其他新的环境,都与这毛线玩偶的芭比娃娃相得益彰,让整个生成的图变得更加和谐、生动,仿佛能让人们真切地感受到那毛线玩偶在特定场景中的独特魅力。

这种方式给人一种非常新奇的体验呢。只需要简单地动动手指,就能体验到图像生成的乐趣,无需绞尽脑汁去构思和上传图像。甚至可以通过掷色子这种随意的方式来自动获取图像,仿佛在不经意间就能发现惊喜。这种简单又好玩的方式,让更多的人能够轻松地参与到图像生成的过程中,感受数字艺术的魅力,仿佛打开了一扇通往奇幻世界的大门。
这个 Whisk 工具具有很大的吸引力,因为它是免费的,让人们能够毫无负担地去尝试和使用它的混合图像生成功能。而 Veo 2 呢,目前还处于一种待开发的状态,需要申请加入等候名单才能使用,这就使得它暂时无法让更多人去体验和感受其魅力。不过,这也让人们对 Veo 2 充满了期待,期待它正式开放后能带来更多的惊喜和创新。

如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









