






这两天技术群都在传阿里通义 Qwen3 五一前后发布,然后昨晚各种消息满天飞:
一觉醒来,千问果然没有让人失望,赶在五一前发布并开源Qwen3,效率杠杠的。作为国内首个实现"混合推理"能力的开源模型,Qwen3不仅达到了36万亿token的训练数据量,还支持119种语言和方言。通过混合专家(MoE)架构与混合推理机制的深度整合,在参数效率与任务适应性层面实现双重突破。旗舰模型Qwen3-235B-A22B在数学证明、代码生成等核心基准测试中,展现出与DeepSeek-R1、Grok-3等顶尖模型的竞争优势。
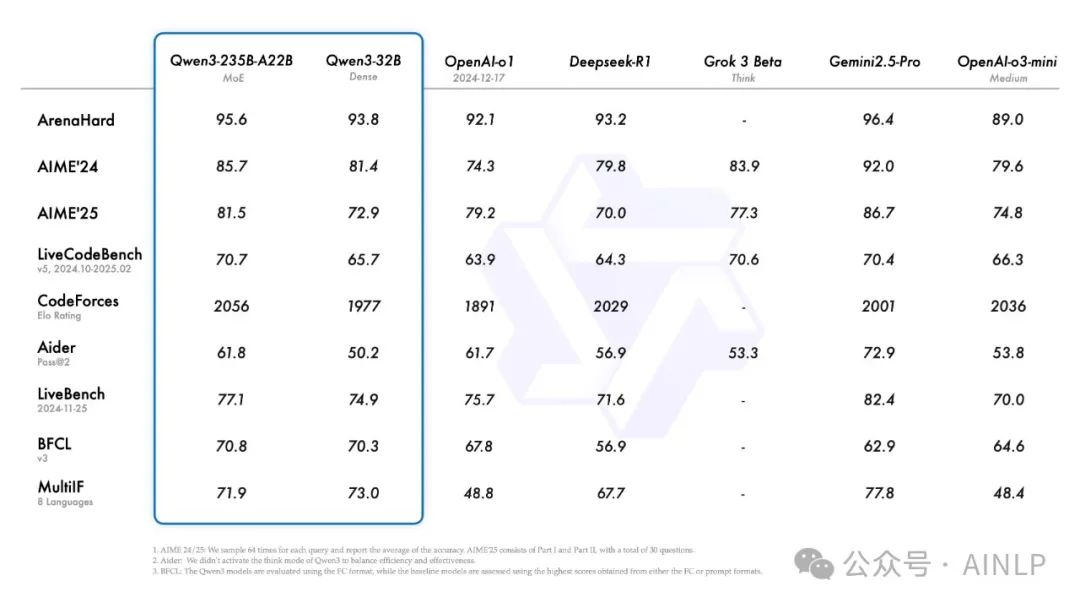
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数量仅为 QwQ-32B 的 10%,但性能却更胜一筹。甚至像 Qwen3-4B 这样的小型模型,也能与 Qwen2.5-72B-Instruct 的性能相媲美。
Qwen3 此次开源了六款Dense模型和两款Moe模型,Dense模型包括0.6B、1.7B、4B、8B、14B、32B 6个尺寸,Moe模型包括30B和235B,均采用Apache2.0协议开源,诚意满满。其中旗舰版 Qwen3-235B-A22B,总参数量 235B,激活参数仅 22B,可以低成本实现本地部署。而 Qwen3-30B-A3B,总参数量 30B,激活参数仅 3B,消费级别显卡即可部署,整体性能堪比Qwen2.5-32B。另外阿里还开源了小尺寸的 Qwen3-0.6B,可以在手机等端侧部署。
特别值得注意的是Qwen3是国内首个“混合推理模型”,在同一模型中集成了两种推理模式:
- 即时响应模式:针对简单查询(如信息检索),通过轻量化推理路径实现快速响应;
- 深度思考模式:应对复杂任务(如数学证明),激活MoE架构中的专家模块进行多步推理;
- 动态切换机制:支持API参数控制(enable_thinking=True)或自然语言指令(/think)触发模式转换;
另外Qwen3的多语言能力进一步大幅跃升,从之前支持的29种提升至支持119种语言和方言:
- 国际通用语言:完整涵盖联合国六大官方语言(汉语、英语、法语、西班牙语、俄语、阿拉伯语);
- 国家官方语言:包括德语、意大利语、日语、韩语、泰语、越南语等国家官方语言;
- 特色方言及小语种:特别纳入中国粤语、非洲斯瓦希里语、中东意第绪语、西亚亚美尼亚语、东南亚爪哇语、美洲海地克里奥尔语等具有文化代表性的地方语言;
通过开源技术赋能,千问3为全球技术储备不足的国家和地区提供了可用的AI大模型,让语言不再成为数字时代的鸿沟。
同时Qwen3通过原生支持MCP多模态协作协议,构建了面向智能体(Agent)生态的核心能力,其深度集成的工具调用架构支持跨平台设备控制与工业协交互,结合开箱即用的Qwen-Agent框架,开发者可快速构建复杂工作流,如生产线调度、跨端自动化等,标志着大模型从"生成答案"向"完成任务"的范式跃迁。
目前可以在欢迎在 Qwen Chat 网页版和通义 APP 中直接体验 Qwen3,相关地址如下:
-
Qwen Chat:
https://chat.qwen.ai/
-
GitHub:
https://github.com/QwenLM/Qwen3
-
HuggingFace:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
-
ModelScope:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Qwen3 快速体验
说了这么多,我还是想动手体验一下 Qwen3,直接在Qwen Chat网页版上体验:
可下拉选择相关模型:
开始测试那个经典问题:9.8和9.11谁大,直接给了推理过程和答案,相当快:
再来一个经典大模型测试题:strawberry有几个r,还是直接给出推理过程和答案:
看起来一般问题难不倒大模型了,那就做一道中考级别的数学题吧:
中考题难不住,继续上高考数学题,这是一道2024年年高考全国甲卷数学(文)试题:
这次思考的过程稍久,不过依然得到了正确答案:-7/2,看起来一般的高考题也难不住Qwen3了,这让我很期待今年高考数学题国内外这些顶尖大模型的PK了。
测试 Qwen3 模型
当然除了体验网页版,我还想上手体验一下开源的Qwen3模型,直接选择最小的0.6B模型,复用Qwen官方博客上提供的代码,只是简单修改了一下模型:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6b"
# load the tokenizer and the modeltokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto")
# prepare the model inputprompt = "Give me a short introduction to large language model."messages = [ {"role": "user", "content": prompt}]text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completiongenerated_ids = model.generate( **model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking contenttry: # rindex finding 151668 (</think>) index = len(output_ids) - output_ids[::-1].index(151668)except ValueError: index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)print("content:", content)
第一次运行模型下载速度挺快的,但是遇到了报错:
刚好看到一篇文章说运行Qwen3 transformers版本不能小于4.51.0,直接升级transformer到4.51.0,再次运行,没有问题了,测试成功:
要禁用思考模式,只需对参数 enable_thinking 进行如下修改:
text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False # True is the default value for enable_thinking.)
Qwen3模型还有很多高级玩法,包括在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式,以及Agent和MCP等,限于时间关系,这里就不一一测试了,后续我会测一下更大尺寸的模型,到时候深入研究一下。刚好五一放假,大家可以好好安排五一了!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









