






反思(Reflection)是一种广泛应用于LLM应用中的提示与工作流模式,特别在Agent应用中,反思可以极大的提高输出质量与任务成功率。本文将探讨Anthropic的《Build effective agents》文中关于Workflows的最后一种基础反思模式:Evaluator-Optimizer(评估器-优化器)模式。
除了基础反思模式外,还有一些扩展的反思模式。比如可以借助外部知识的强化反思模式、结合了自我评估与树搜索的任务优化模式(LATS,Language Agent Tree Search),我们将用专门的文章来介绍这些增强的反思模式。
01
基础反思模式(Evaluator-Optimizer)
反思是这样一种工作模式:一个“增强LLM”调用负责生成响应,另一个则负责评估与反馈,两者之间经过多次迭代,最后输出更高质量的响应结果。
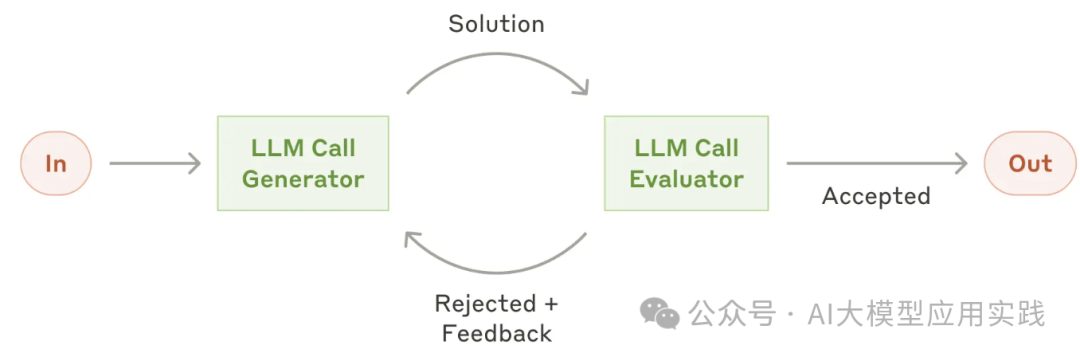
显然,这种模式也可以拓展到多Agent系统(Multi-Agent System)中。当我们的输入任务有比较明确的期望、要求与评估标准,都可以借助这种方式来不断的评估与完善任务结果。典型的场景比如:
-
长文翻译:从语言风格、专业名词、前后一致性等方面自我审查
-
代码编写:从正确性、复杂度、效率、编码风格等方面审查代码
-
文案/报告创作:从格式、完备性、目录、风格等方面审查结果
这种模式在实际应用中仍然有改进空间,否则你可能会发现,多次的简单反思并不会带来更多的改进。一些可能的改进方式比如:
-
评估时以不同的角色,从不同的角度对响应进行评价
-
借助于外部数据或知识来对已有响应做评估与增强
02
PydanticAI实现基础反思模式
实现基础反思模式的过程如下(基于PydanticAI):
- 定义生成器与评估器的输出类型
...
# 生成器响应模型
class GeneratorResponse(BaseModel):
thoughts: str = Field(..., description='你对任务的理解和反馈,或者你计划如何改进。')
response: str = Field(..., description='生成的解决方案。')
# 评估器响应模型
class EvaluatorResponse(BaseModel):
thoughts: str = Field(..., description='你对提交内容的仔细和详细的审查和评估。')
evaluation: str = Field(..., description='通过, 需要改进, 或失败')
feedback: str = Field(..., description='需要改进的地方和原因。')
2. 定义生成器与评估器的提示与模型
仍然采用配置的方式来完成,这里注意根据任务的不同,你可能需要调整提示词,以实现更加针对性的反思。
...
# 定义生成器和评估器的步骤
steps = {
"generator": {
"prompt": """你的目标是根据用户输入完成任务。如果你之前生成的内容收到了反馈,请根据这些反馈改进你的解决方案。""",
"model": model,
"result_type": GeneratorResponse
},
"evaluator": {
"prompt": """
请对以下代码实现进行评估,重点关注以下方面:
1. **代码正确性**:是否完全按照规范无误地实现了要求的功能?
2. **时间复杂度**:实现是否满足规定的时间复杂度要求?
3. **效率**:实现是否是针对需求最有效、最优化的方案?
4. **风格与最佳实践**:代码是否遵循标准的 Python 风格和最佳实践?
5. **可读性**:代码是否易于阅读和理解?
6. **文档化**:代码是否有清晰的文档说明,包括为所有函数和类撰写的 docstrings,以及必要的内嵌注释
注意:你应该仅评估代码,而不是尝试解决任务。
请仔细且严格地评估代码,确保不会错过任何改进的机会。
如果所有评估标准都完全满足且没有进一步改进建议,请输出“PASS”。否则,请输出“NEEDS_IMPROVEMENT”或“FAIL”,以便编码者能够学习和改进。
""",
"model": model,
"result_type": EvaluatorResponse
}
}
3. 实现生成器与评估器的LLM调用
这个过程本身没有复杂性,这里借助PydanticAI的Agent组件实现,实际上也可以借助LLM API直接实现。
# 生成解决方案的函数 async def generate(task: str, context: str = "") -> tuple[str, str]: """根据反馈生成和改进解决方案。""" config = steps["generator"] system_prompt = config["prompt"] if context: system_prompt += f"\n\n{context}" generator_agent = Agent(config["model"],system_prompt=system_prompt, result_type=config["result_type"])` `response = await generator_agent.run(f'任务:\n{task}') thoughts = response.data.thoughts result = response.data.response return thoughts, result
评估器:
async def evaluate(content: str, task: str) -> tuple[str, str]:
"""评估解决方案是否符合要求。"""
config = steps["evaluator"] evaluator_agent = Agent(config["model"], system_prompt=f'{config["prompt"]}\n\n任务:\n{task} ',result_type=config["result_type"])
response = await evaluator_agent.run(content)
evaluation = response.data.evaluation
feedback = response.data.feedback
return evaluation, feedback
4. 主循环
借助生成器与评估器之间的配合与迭代,最终获得输出结果。在实际应用中,最好要设置最大迭代次数(max_iterations)作为终止条件,而不能完全的依赖于LLM评估器对结果的判断,否则有可能陷入死循环。
...
thoughts, result = await generate(task)
while iteration < max_iterations:
evaluation, feedback = await evaluate(result, task)
memory.append({"thoughts": thoughts, "result": result, "evaluation":evaluation,"feedback": feedback})
print(f"\nIteration {iteration + 1}:\nThoughts: {thoughts}\nResult: {result}\nEvaluation: {evaluation}\nFeedback: {feedback}")
if evaluation == "PASS":
return result,memory
context = "\n".join([
"之前的尝试:",
*[f"- 结果: {m['result']}\n 反馈: {m['feedback']}" for m in memory]
])
thoughts, result = await generate(task, context)
iteration += 1
以上就是基础反思模式的核心实现。如果使用输入任务进行测试,就可以看到类似如下的输出,体现了其中的评估与优化改进过程:

03
小结
在Anthropic的这篇《Build effective agents》文章中,比较清晰的帮我们区分了Agent系统的两种类型:Workflows与Agents,并介绍了Workflows中常见的5种基础模式:顺序、并行、路由、编排-工作、反思-优化模式。
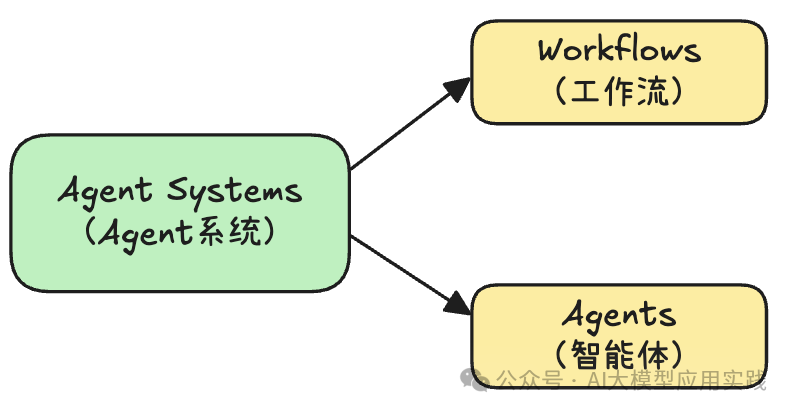
在我们的系列文章中,对这些基础模式借助更轻量级的PydanticAI做了通用实现。在理解了这些模式的基础上,借助于类似于LangGraph/LlamaIndex Workflows这样的框架,就可以方便的组合与拓展出复杂性更高的AI工作流。相对于更“黑盒”的Agents,Workflows牺牲了一定的灵活性,但是大大提高了可控性,这对于目前在LLM的长任务推理能力尚不足的情况下,实现企业级的Agent系统是至关重要的。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









