






课程打卡凭证

GAN模型
GAN(Generative Adversarial Networks),即生成对抗网络,是一种生成式机器学习模型,通常用于生成与真实数据分布相似的新数据。它由一个生成器(Generator)和一个判别器(Discriminator)组成:生成器接受一个随机噪声向量作为输入,并输出一个与真实数据分布相似的数据样本。判别器接受数据样本(既包括生成器生成的样本,也包括真实数据样本),并输出一个概率值,表示输入样本来自真实数据的概率。
GAN 的训练是一个交替优化的过程,其中生成器通过欺骗判别器,即生成尽可能逼真的数据样本,使判别器认为这些样本是真实的;而判别器则通过正确区分真实数据和生成的数据,最大化对抗生成器的能力。具体过程如下图所示,其中,蓝色虚线表示判别器,黑色虚线表示真实数据分布,绿色实线表示生成器生成的虚假数据分布,随着模型的迭代,判别器波动趋于0,生成器生成的虚假数据分布无限接近于真实数据分布。
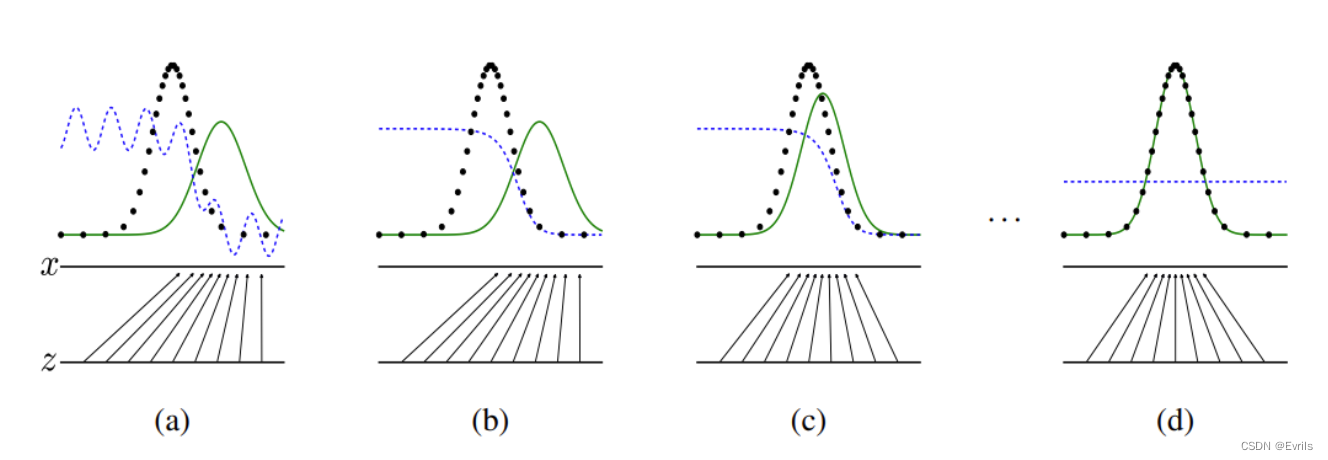
训练过程
数据加载与处理
本实验采用MNIST手写数字数据集,目的是训练一个GAN模型,来模拟生产手写数字的图片。
加载MNIST数据集,并定义数据增强和批处理操作。
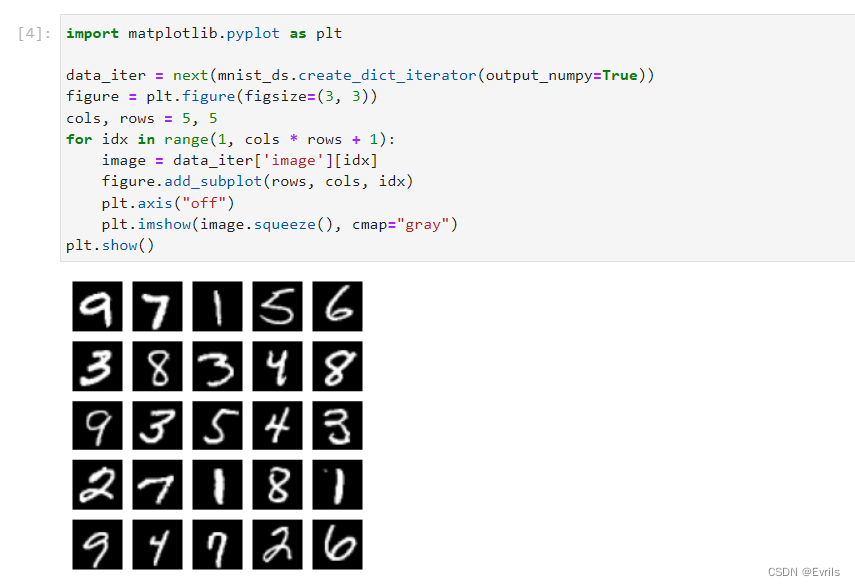
可视化数据集,这里用到了matplotlib库中的pyplot模块。
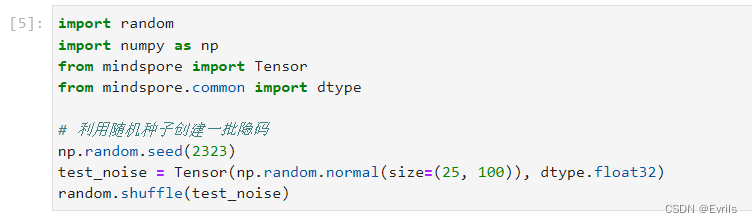
生成一批用于测试的噪声向量(隐码),每个向量的长度为100,并将其打乱,它可以评估生成器的好坏。
模型构建
构建生成器

导入必要的库和模块,设置训练图像的size。
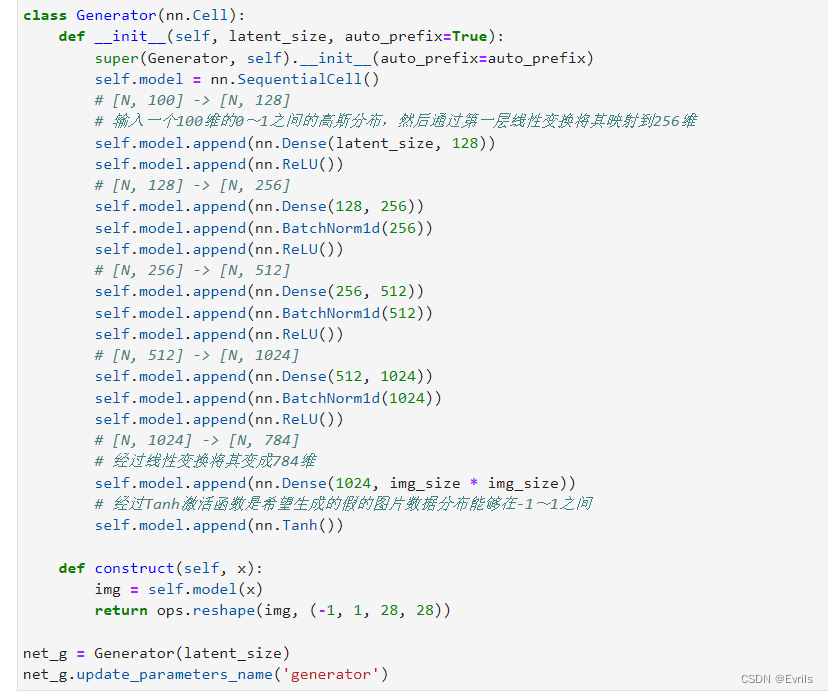
定义生成器模型,并实例化生成器网络net_g。
构建判别器

定义判别器模型,并实例化判别器网络net_d。
定义损失函数和优化器

这里使用了Adam优化器来优化生成器和判别器的参数,构建两个优化器,分别对应两个生成器。损失函数则用常见的交叉熵损失函数。
模型训练
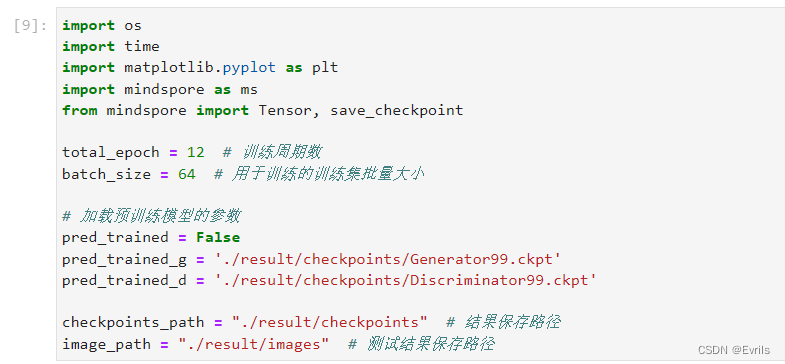
导入必要的库和模块,加载预训练模型参数,创建保存路径。
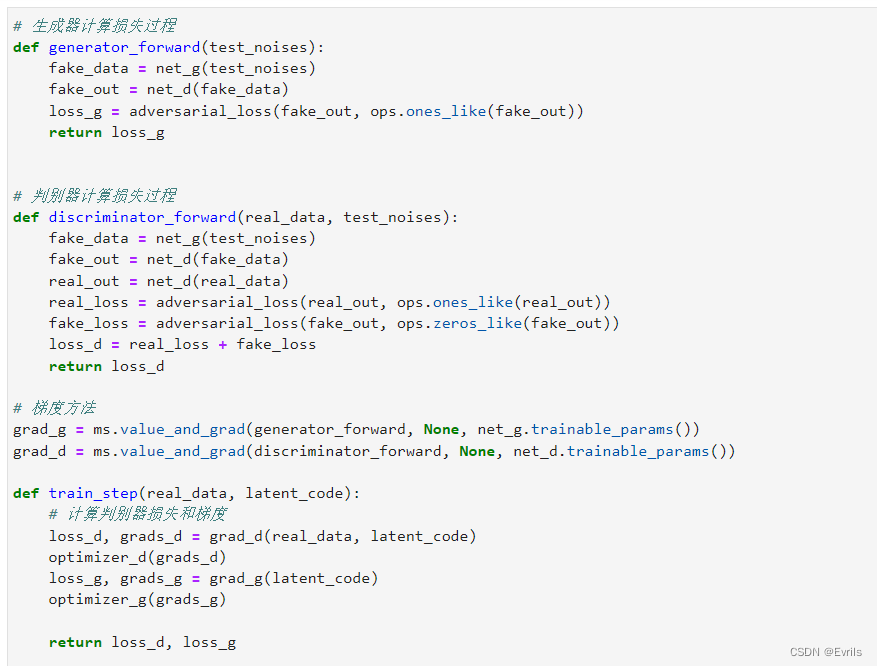

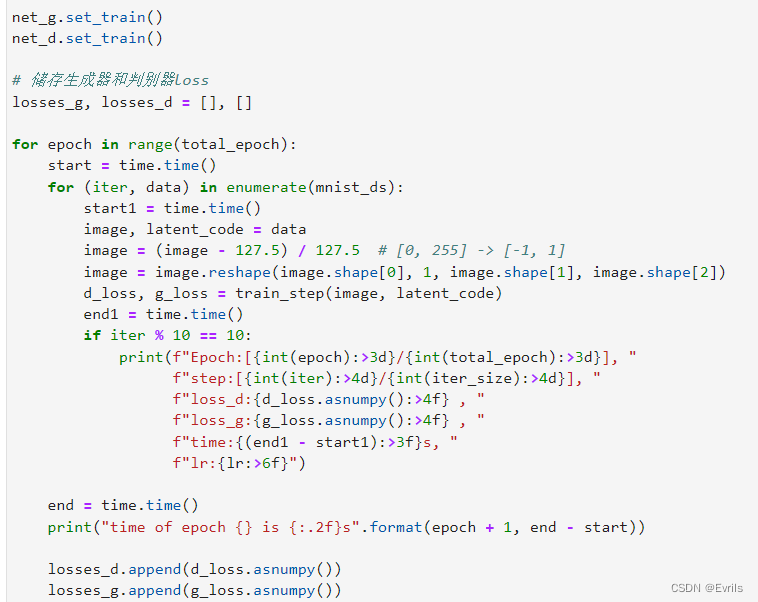

训练过程代码如图所示。

训练结果如图上所示。
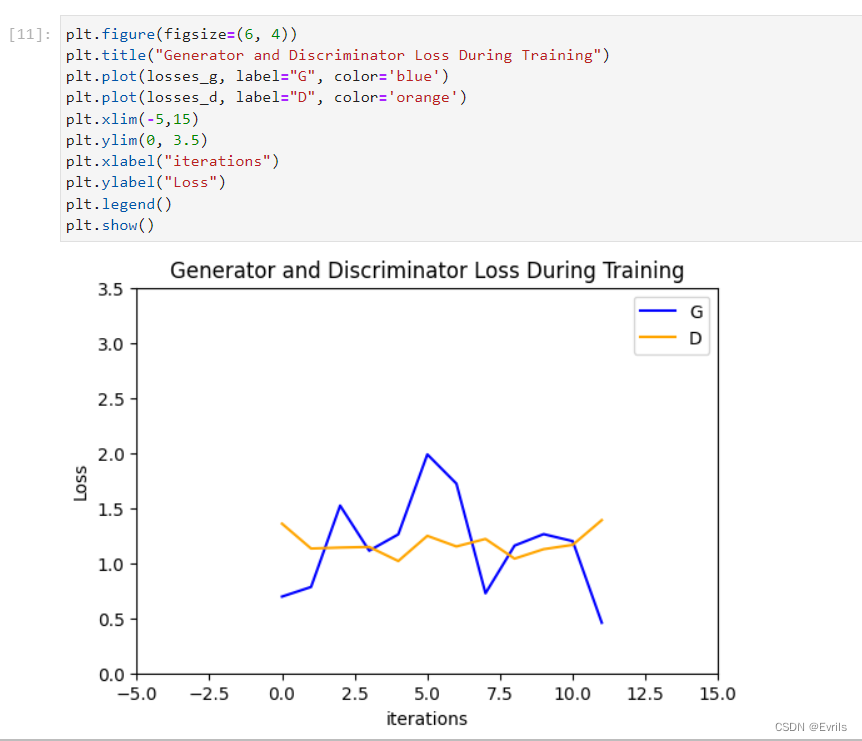
生成器和判别器损失与迭代训练的关系如图所示。
将整个训练过程中生成的图像转成动图,结果如下图所示。

模型推理
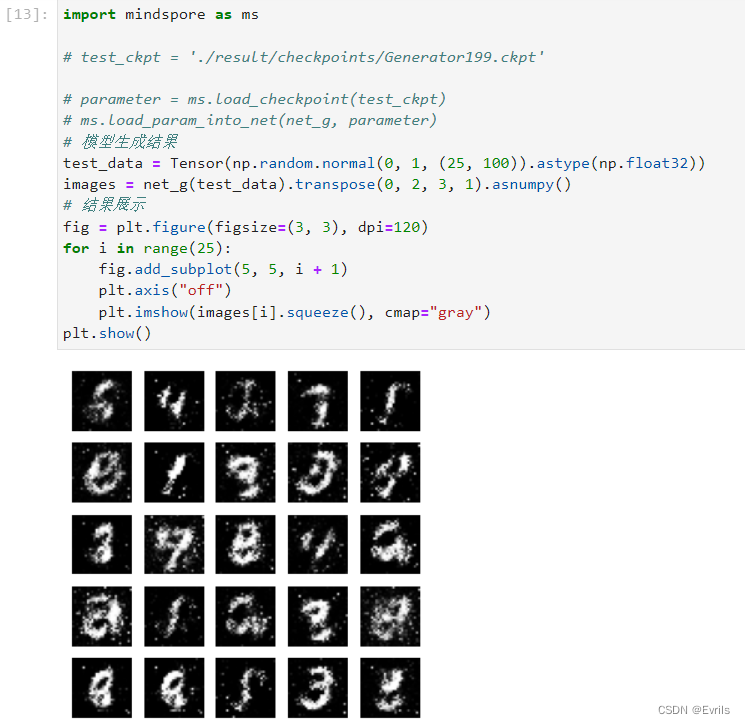















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









