






RAG
一.RAG相关基础知识
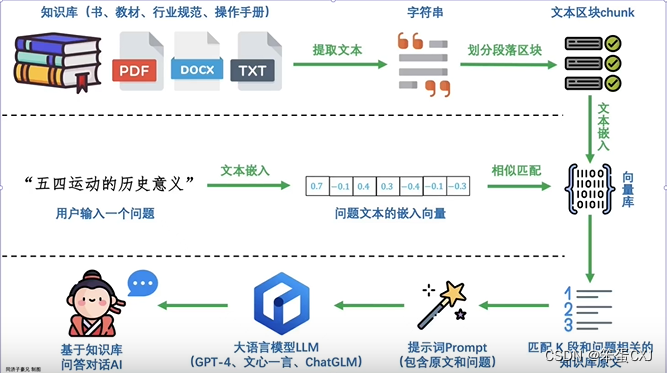
1.增强检索基本思路
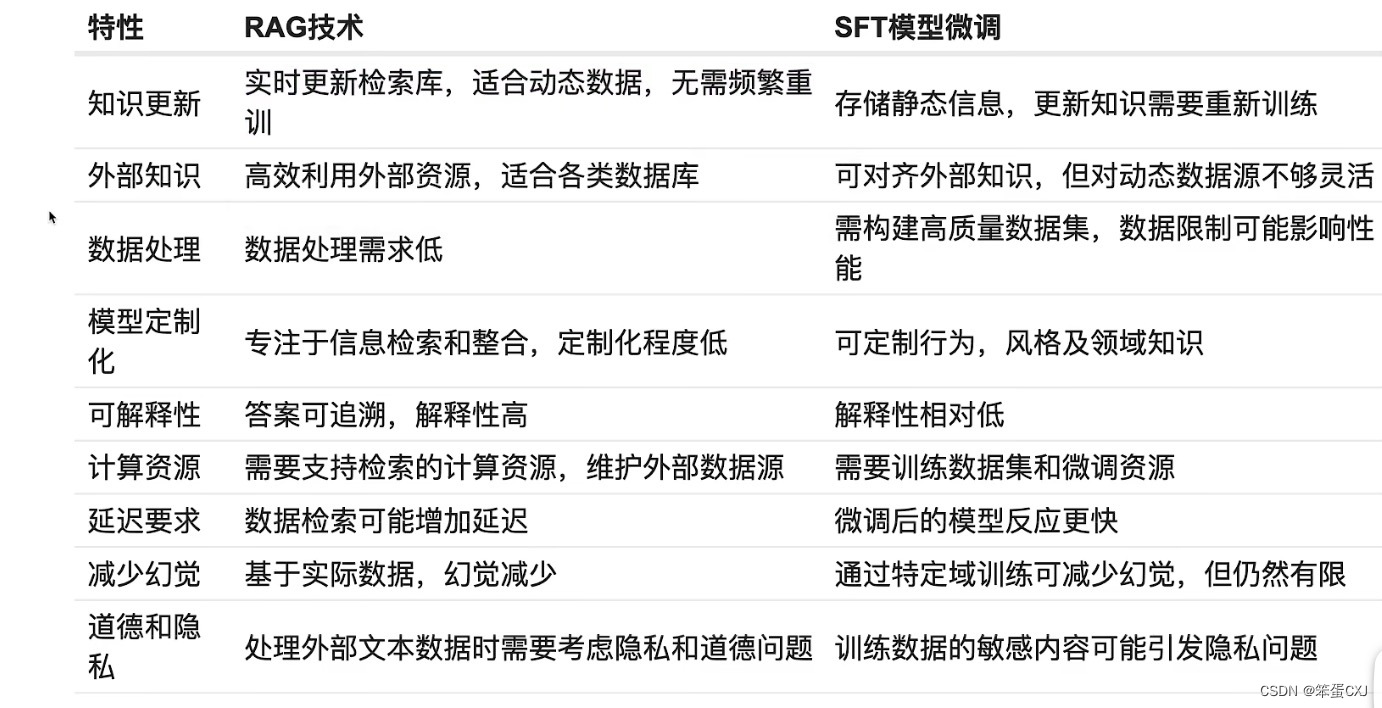
2.RAG(检索增强)和SFT(指令微调)区别
大模型目前存在问题:幻觉、时效性、数据安全
知识库问答KBQA:存储于图数据库中的知识库,以三元组的形式进行呈现《主题、关系、对象》
二.文本索引与答案检索
1.文本检索
文本检索是一个多步骤的过程,其核心是构建倒排索引以实现高效的文本检索∶
步骤1(文本预处理)︰在文本预处理阶段,对原始文本进行清理和规范化,包括去除停用词、标点符号等噪声,并将文本统一转为小写。接着,采用词干化或词形还原等技术,将单词转换为基本形式,以减少词汇的多样性,为后续建立索引做准备。
步骤2(文本索引)︰构建倒排索引是文本检索的关键步骤。通过对文档集合进行分词,得到每个文档的词项列表,并为每个词项构建倒排列表,记录包含该词项的文档及其位置信息。这种结构使得在查询时能够快速找到包含查询词的文档,为后续的文本检索奠定了基础。
步骤3(文本检索)︰接下来是查询处理阶段,用户查询经过预处理后,与建立的倒排索引进行匹配。计算查询中每个词项的权重,并利用检索算法〈如TFIDF或BM25)对文档进行排序,将相关性较高的文档排在前面。
什么是倒排索引和正排索引?

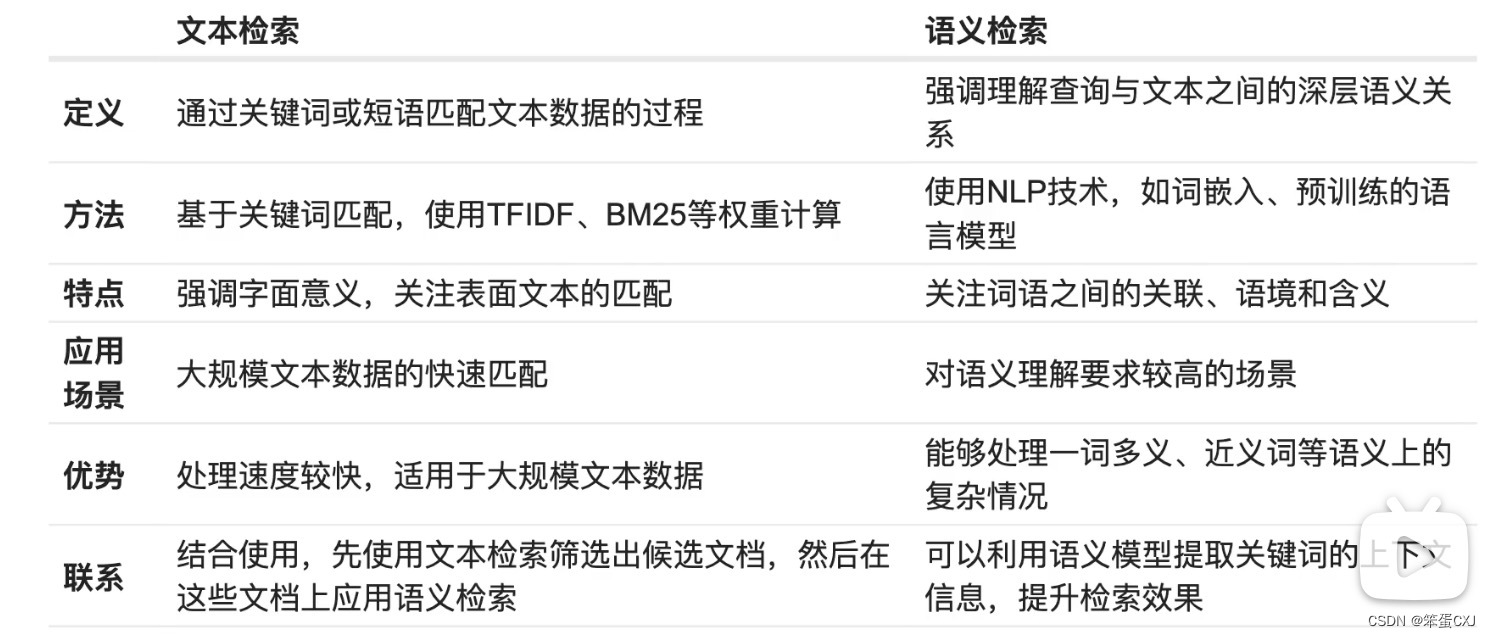
2.文本检索和语义检索区别:
3.文本检索算法:
文本检索算法TFIDF和BM25:(仅用作演示使用,非工业级应用,应使用专业的ElasticSearch进行文本检索)
(1) TFIDF


(2) BM25:


4.语义检索
需要进行深度学习和自然语言处理相关方面知识的学习

文本编码模型:
文本编码模型对于语义检索的精度至关重要,常见的如基于BERT (Bidirectional Encoder Representations from Transformers)的模型,或者GPT (Generative Pre-trained Transformer)等。
编码模型排行榜:https://huggingface.colspaces/mteb/leaderboard
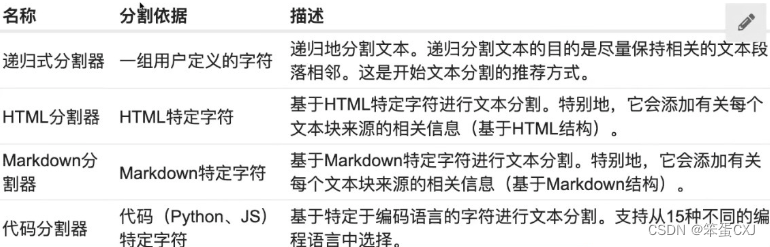
文本切分方法:文本切分的长度将影响最终编码的结果,
三.文本多路召回与重排序
基本思路:先进行多路召回,再基于第一次搜索的结果进行重排序
多路召回逻辑是在文本检索中常用的一种策略,其目的是通过多个召回路径(或方法)综合获取候选文档,以提高检索的全面性和准确性。单一的召回方法可能由于模型特性或数据特点而存在局限性,多路召回逻辑引入了多个召回路径,每个路径采用不同的召回方法。
·实现方法1:将BM25的检索结果和语义检索结果按照排名进行加权
·实现方法2∶按照段落、句子、页不同的角度进行语义编码进行检索,综合得到检索结果。

4.文本问答Promopt优化、关键词提取
1.基本步骤
·步骤1∶提取用户提问的嵌入向量
·步骤2︰提取文档所有的嵌入向量
·步骤3:判断提问向量与文档向量的最低相似度,结合相似度大小进行判断
2.关键词提取方法 IDF、KeyBert、大模型

2.KeyBert

3.大模型进行关键词提取

相关资料:https:/ltech.meituan.com/2022/02/17/exploration-and-practice-of-query-rewriting-in-meituan-search.html
五.相关资料地址
RAG官方文档地址:
LangChain官方文档地址:
chatGLM官方体验地址
QAnyThing官方体验地址
基于chatGLM进行微调源码地址
QAnyThing API调用示例源码地址
本文基于bilibili视频动手学RAG总结,原视频地址动手学RAG,感兴趣的小伙伴可以去看一下原视频















 4337
4337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









