







话接上文的召回多样性优化,多路索引的召回方案可以提供更多的潜在候选内容。但候选越多,如何对这些内容进行筛选和排序就变得更加重要。这一章我们唠唠召回的信息密度和质量。同样参考经典搜索和推荐框架,这一章对应排序+重排环节,考虑排序中粗排和精排的区分主要是针对低延时的工程优化,这里不再进一步区分,统一算作排序模块。让我们先对比下重排和排序模块在经典框架和RAG中的异同
- 排序模块
- 经典框架:pointwise建模,局部单一item价值最大化,这里的价值可以是搜索推荐中的内容点击率,或者广告中的ecpm,价值由后面使用的用户来决定
- RAG:基本和经典框架相同,不过价值是大模型使用上文多大程度可以回答问题,价值的定义先由背后的大模型给出,再进一步才能触达用户。更具体的定义是,排序模块承担着最大化信息密度的功能,也就是在更少的TopK内筛选出尽可能多的高质量内容,并过滤噪声信息。
- 重排模块
- 经典框架:Listwise建模,通过对item进行排列组合,使得全局价值最大化,进而使得用户多次行为带来的整体体验感更好。这里的整体可以是一个搜索列表页,一屏推荐信息流,也可以是更长的一整个session内用户体验的整体指标,以及背后的商业价值。常见的做法是打散,提高连续内容的多样性,以及前后内容的逻辑连贯性,不过打散只是手段,全局价值才是终极目标
- RAG:概念相似,通过重排优化模型对整体上文的使用效率。优化模型对上文的使用,提升信息连贯性和多样性,最小化信息不一致性和冲突。不过当前大模型对话式的交互方式更难拿到用户体验的反馈信号,想要优化用户体验难度更高。
下面我们分别说两这两个模块有哪些实现方案
1. 排序模块
上一章提到使用query改写,多路索引,包括bm25离散索引,多种embedding连续索引进行多路内容召回。这种方案会提供更丰富的内容候选,但也显著增加了上文长度。而很多论文都评估过,过长的上文,以及过长上文中更大比例的噪声信息,都会影响模型推理的效果,如下图
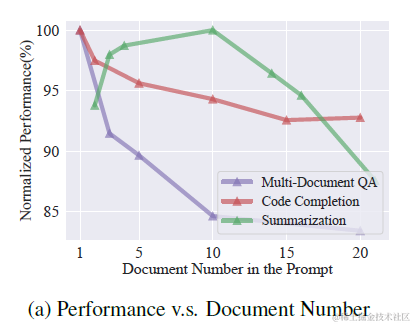
因此如何从这些召回内容中排序筛选出更出质量更高的内容,过滤噪声信息就是排序模块需要做的。考虑不同索引之间对于相似度的计算打分相互不可比,更不可加,因此需要统一的打分维度来对候选内容进行排序,这里提供两个无监督的混合排序打分方案
1.1 RRF混排
- https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking
- https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble
多路召回混合排序较常见的就是Reciprocal Rank Fusion(RRF),把所有打分维度都转化成排名,每个文档的最终得分是多路打分的排名之和的倒数。通过排名来解决不同打分之间scale的差异性。公式如下,其中r(d)是单一打分维度中的文档排名,K是常数起到平滑的作用,微软实验后给的取值是60。
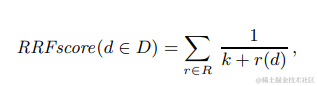
以下是微软搜索中使用RRF类合并文本检索和向量检索的一个示意图,使用RRF分别对文本检索和向量检索的多路召回内容进行混合排序
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









