







Cronjob是比job控制器更加高级的一种控制器类型。Cronjob基于job,并且增加了时间调度
(1)在未来的某个指定时间运行一次Job,比如执行某个临时的任务
(2)周期性的运行job,比如定期备份、清理系统文件
CronJob的模板
[root@master ~]# vi cronjobv1.yaml
apiVersion: batch/v1beta1 #此控制器目前只存在于beta1
kind: CronJob
metadata:
name: String
namespace: String
labels: #元数据的标签列表
key: #标签的键值对
annotations: #自定义注解列表
key: value #定义多个注解的键值对
spec:
schedule: #指定的任务运行周期,格式和Cron类似
jobTemplate: {JobTemplate} #job的模板
startingDeadSeconds: int #启动job的期限(秒为单位),若执行时间超出期限,Job则认定为失败,没有指定则>没有期限
concurrencyPolicy: Allow/Forbid/Replace #如果上一个周期的Job未执行完毕,而下一个周期已经开始,在这种
并发的场景下采用的策略。默认为Allow,允许并发运行Job;Forbid禁止并发运行,如果上一个周期的Job未执行完毕>,下一个Job直接忽略掉;Replace表示取消正在运行的Job,用一个新的来替换
suspend: boolean #如果设置未True,上一个Job的周期为执行完成,下一周期已经开始,则后续所有的执行都会被挂起
successfulJobsHistoryLimit: int #保留多少条执行成功的Job记录,默认为3
failedJobsHistoryLimit: int ##保留多少条执行失败的Job记录,默认为1
[root@master ~]# vi testcronjobv1.yaml
apiVersion: batch/v1beta1 #此控制器目前只存在于beta1
kind: CronJob
metadata:
name: testcronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: testcronjob
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "Start Job!";sleep 20; echo "Job Done!"']
[root@master ~]# kubectl apply -f testcronjobv1.yaml
Warning: batch/v1beta1 CronJob is deprecated in v1.21+, unavailable in v1.25+; use batch/v1 CronJob
cronjob.batch/testcronjob created
[root@master ~]# kubectl get CronJob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
testcronjob */1 * * * * False 1 3s 58s
[root@master ~]# kubectl get job
NAME COMPLETIONS DURATION AGE
testcronjob-28078629 1/1 23s 106s
testcronjob-28078630 1/1 21s 46s
其他控制器的使用(ReplicationController ReplicaSet)
两者之间并无差异,只是名字不同,Controller是最早的控制版本,后来被Set取代,到了Deployment控制器出现,两者很少单独使用。
[root@master ~]# cat testdeployment.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: testdeployment
spec:
replicas: 3
selector:
matchLabels:
example: deploymentnginx
template:
metadata:
labels:
example: deploymentnginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在Kubernetes中,Service是充当了基础内部负载均衡器的一种组件。Service会将相同功能的Pod在逻辑上进行组合到一起,一般会采用标签选择器(label selector)来进行组合。
Service可以发布服务,可以跟踪并路由到所有指定类型的后端容器。针对于内部使用者而言,只需要直到对应的端点即可访问服务。
[root@master ~]# vi servicetemplate.yaml
apiVersion: v1
kind: Service
metadata: #元数据
name: #Service的名称
namespace: #创建Service指定的命名空间
labels: #service的标签
- name:
annotations: #Service的注解
- name:
spec:
selector: [] #标签选择器,选择具有指定标签的Pod作为管理范围
type: #Service的类型
clusterIP: #虚拟服务的地址
sessionAffinity: #指定是否支持session,[ClinentIP|None]表示将同一个客户端的访问请求发送到同一个后端
ports: #Service需要暴露的端口
- name: #端口的名称
protocol: #采用的协议类型
port: #Service监听的端口
targetPort: #发送到后端应用的端口
nodePort: #当service的tpye为NodePort时,指定映射到物理机的端口
status: #当service的tpye为LoadBalancer时,需要设置外部负载均衡器的地址
loadbalancer:
ingress:
ip: #外部负载均衡器的地址
hostname: 外部负载均衡器的主机名
Service的类型目前分为五大类。通过type可以进行定义ClusterIP\NodePort\LoadBalancer\ExternalName,ClusterIP又分为普通Service和无头Service
Service向外发布的方式:
(1)ClusterIP(普通):为默认的方式,在使用时可以无需指定。自动分配一个仅 cluster 内部可以访问的虚拟 IP,集群中的任何机器和Pod都可以访问这个IP
(2)NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 <NodeIP>:NodePort 来访问该服务。
(3)LoadBalancer:基于ClusterIP和NodePort两种方式,除此之外,还会申请使用外部负载均衡器,由负载均衡器映射到各个“NodePort:端口”上,这样K8S集群外部的机器可以通过负载均衡器的方式访问Service。
Service向内发布的方式:
ExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)
ClusterIP(无头Service):通过DNS提供的网络ID进行访问,DNS会将无头Service的后端直接解析为Pod的IP地址列表,这种类型的Pod只能在集群内的Pod中访问,集群中的机器没法直接访问。主要给statefulSet提供服务。
[root@master ~]# vi testdeployment.yaml
apiVersion: apps/v1
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploymenthttp
spec:
replicas: 3
selector:
matchLabels:
example: deploymenthttp
template:
metadata:
labels:
example: deploymenthttp
spec:
containers:
- name: pythonservice
image: python:3.7
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "<p> The host is $(hostname) </p>" > index.html; python -m http.server 80']
ports:
[root@master ~]# kubectl get pod -o wide |grep deploymenthttp //查询pod状态
deploymenthttp-7fbc9958f5-jrf2n 1/1 Running 0 109s 10.244.1.177 worker2 <none> <none>
deploymenthttp-7fbc9958f5-s5fwq 1/1 Running 0 109s 10.244.1.175 worker2 <none> <none>
deploymenthttp-7fbc9958f5-w9b8g 1/1 Running 0 109s 10.244.1.176 worker2 <none> <none>
从以上内容可以看出我们创建了三个pod,分别对应了三个IP,因为在pod中已经构建了web服务(端口是80),所以可以通过这个端口去进行访问。
[root@master ~]# curl 10.244.1.175
<p> The host is deploymenthttp-7fbc9958f5-s5fwq </p>
因为Pod的IP地址是不固定的,而且直接访问Pod IP地址也是没有办法满足负载均衡的功能,所以我们需要以Service作为入口,来提供稳定的IP和负载均衡功能给集群内外使用。
通过ClusterIP的方式向外发布服务
1.普通Service的发布
在K8S集群内部发布服务,并且会为Service分配一个在集群内访问的固定虚拟IP。可以在集群内部的节点中通过ClusterIP进行访问服务,也可以在Pod中通过ClusterIP地址访问服务,单集群外部的地址无法访问。
[root@master ~]# vi testhttpservice.yaml
apiVersion: v1
kind: Service
metadata:
name: deploymenthttp
spec:
selector:
example: deploymenthttp
ports:
- port: 8080 #Service端口
targetPort: 80 #后端(pod)端口
protocol: TCP #协议
type: ClusterIP
[root@master ~]# kubectl apply -f testhttpservice.yaml
service/deploymenthttp created
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
deploymenthttp ClusterIP 10.1.245.237 <none> 8080/TCP 60s
[root@master ~]# curl 10.1.245.237:8080 //通过集群地址访问服务
<p> The host is deploymenthttp-7fbc9958f5-w9b8g </p>
[root@master ~]# curl 10.1.245.237:8080
<p> The host is deploymenthttp-7fbc9958f5-s5fwq </p>
[root@master ~]# curl 10.1.245.237:8080
<p> The host is deploymenthttp-7fbc9958f5-jrf2n </p>
//经过多次访问后,我们可以看出service已经实现了负载均衡的功能,在访问时可以按照比例随机分配到3个pod中,并且在访问的过程中无需关注pod具体IP。
[root@master ~]# kubectl describe svc deploymenthttp
Name: deploymenthttp
Namespace: default
Labels: <none>
Annotations: <none>
Selector: example=deploymenthttp
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.1.245.237
IPs: 10.1.245.237
Port: <unset> 8080/TCP
TargetPort: 80/TCP
Endpoints: 10.244.0.73:80,10.244.1.175:80,10.244.1.176:80 + 3 more...
Session Affinity: None
Events: <none>
//在详细信息中需要注意endpoint的信息,它列出了所有的Pod地址与公布的端口,在调用Service时,会按照比例随机转发给其中的一个地址。
向外发布-NodePort
通过NodePort的方式向外发布,基于ClusterIP的方式,首先要生成一个虚拟IP,然后将虚拟IP和端口映射到集群中的节点上,这样的话我们就可以通过节点本身加端口的方式来进行访问Service。
因为ClusterIP本身就已经提供了负载均衡的功能,所以在NodePort模式下,不管访问的时集群中的哪个节点地址,实现的负载均衡效果都是一样的,这个过程会先由某台机器通过映射关系转发到ClusterIP,然后由ClusterIP通过比例随机算法转发到对应的Pod。
[root@master ~]# vi testnodeportservice.yaml
apiVersion: v1
kind: Service
metadata:
name: deploymenthttp
spec:
selector:
example: deploymenthttp
ports:
- port: 8080
targetPort: 80
protocol: TCP
nodePort: 30002 #将ClusterIP及Port属性,来映射到集群中的各个机器的30001端口,这样的话,就可以通过集群节点ip加映射端口访问,nodePort取值范围时30000至32767
type: NodePort
[root@master ~]# kubectl apply -f testnodeportservice.yaml
service/deploymenthttp configured
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
deploymenthttp NodePort 10.1.245.237 <none> 8080:30002/TCP 65m
[root@master ~]# curl 10.1.245.237:8080 //因为是基于ClusterIP的方式进行访问,所以通过集群地址的方式依然可以访问到服务
<p> The host is deploymenthttp-7fbc9958f5-jrf2n </p>
访问成功,我们便可以在物理节点加上端口的方式进行访问,集群中的每一个节点都可以进行访问
[root@master ~]# curl 192.168.200.11:30002
<p> The host is deploymenthttp-7fbc9958f5-w9b8g </p>
[root@master ~]# curl 192.168.200.12:30002
<p> The host is deploymenthttp-7fbc9958f5-s5fwq </p>
[root@master ~]# curl 192.168.200.13:30002
<p> The host is deploymenthttp-7fbc9958f5-w9b8g </p>
向外发布-通过loadbalancer的方式
它是基于ClusterIP和NodePort两种方式来发布服务,,除此之外还会使用外部负载均衡器,由负载均衡器映射到各个“NodeIP:端口”上,那么K8S外部的机器就可以通过负载均衡器来进行访问。
K8S没有为私有集群提供网络负载均衡器的实现,如果K8S集群没有在公有云上运行,那么Loadbalancer则无限期的处于一个pending的状态,只有公有云厂商的k8s支持Loadbalancer。
MetalLB,这个服务可以为不在公有云平台上运行的私有K8S集群,提供网络负载均衡器的实现,从而有效的解决在任何集群中使用Loadbalancer。
首先会在K8S内运行,监控服务对象的变化。一旦察觉有新的Loadbalancer Service在运行,并没有可申请的负载均衡器之后,就分别完成两个内容:
(1)地址分配:MetalLB会把用户配置的地址池中选区的地址分配给Service
(2)地址广播:根据不同的配置,MetalLB会以二层(ARP/NDP)或者BGP的方式进行地址广播。
安装MetalLB
[root@master~]#kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
[root@master~]#kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
//首先下载yaml文件,
[root@master ~]# kubectl get pods -n metallb-system
NAME READY STATUS RESTARTS AGE
controller-66445f859d-hwc5b 1/1 Running 0 3h7m
speaker-lb6gs 1/1 Running 0 3h7m
speaker-pdgx8 1/1 Running 0 3h7m
speaker-xlszp 1/1 Running 0 3h7m
[root@master ~]# vi Configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.1.30-192.168.1.49
[root@master ~]# kubectl apply -f Configmap.yaml
configmap/config created
创建Service
[root@master ~]# vi testloadbalancer.yaml
apiVersion: v1
kind: Service
metadata:
name: loadbalancer
spec:
selector:
example: deploymenthttp
ports:
- protocol: TCP
port: 8080
targetPort: 80
type: LoadBalancer
[root@master ~]# kubectl apply -f testloadbalancer.yaml
service/loadbalancer created
验证
对于Service,可以通过ClusterIP的方式进行访问,也可以通过NodePort的方式进行访问,通过NodePort的方式访问如下:
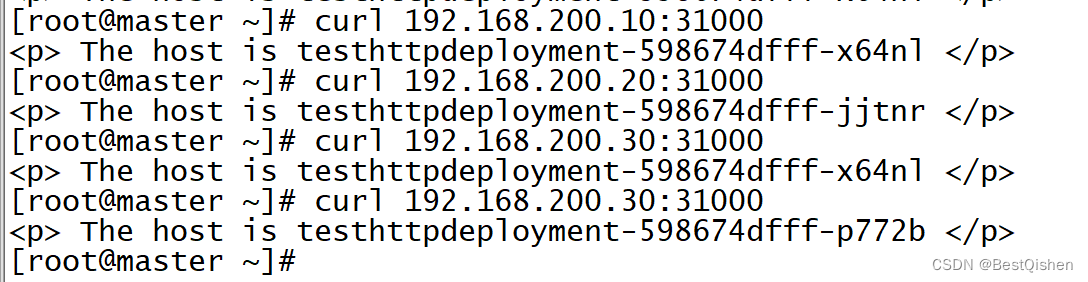
通过Loadbalancer的方式访问

在这个案例中,Loadbalancer对外的IP是192.168.1.30,端口为8080,所以外部机器直接可以通过这个地址进行访问。
向内发布-无头Service
无头Service(headless service),是一种比较特殊的Service的类型。通过这种无头的Service发布,不会分配任何的ClusterIP地址,也不会通过kube-proxy进行反向代理和负载均衡。
无头Service是通过DNS来提供稳定的网络ID进行访问,DNS会将无头Service的后端直接解析为Pod的IP地址列表,并且通过标签选择器将后端的Pod列表进行返回调用的客户端。
这种类型的Service只能再集群内的Pod中访问,集群内的节点没有办法直接访问,集群外部的机器也是没有办法直接访问。无头Service只要给statefulSet进行使用。
[root@master ~]# vi testheadless.yaml
apiVersion: v1
kind: Service
metadata:
name: testheadless
spec:
selector:
example: deploymenthttp
clusterIP: None
ports:
- protocol: TCP
port: 8080
targetPort: 80
type: ClusterIP
//这个实例,与前面的ClusterIP不同的是,我们再这个属性中设置了一个clusterIP的属性为None,不分配任何的虚拟IP地址。
[root@master ~]# kubectl apply -f testheadless.yaml
service/testheadless created
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
chinaskill-mall NodePort 10.1.35.95 <none> 80:30080/TCP 10d
kubernetes ClusterIP 10.1.0.1 <none> 443/TCP 12d
test-nginx NodePort 10.1.39.206 <none> 80:32217/TCP 6d23h
testheadless ClusterIP None <none> 8080/TCP 14s
由于这个Service没有办法通过集群内外的机器直接访问,所以只能由Pod进行访问,而且需要通过DNS,访问的形式为{ServiceName}.{Namespace}.svc.{ClusterDoamin},其中ClusterDomain代表集群域,,默认集群域为cluster.local。
[root@master ~]# vi testheadless1.yaml
apiVersion: v1
kind: Pod
metadata:
name: testheadless1
spec:
containers:
- name: testheadles1
image: docker.io/appropriate/curl
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "This is test pod for headless service!"; sleep 3600']
以上可知此pod并无特殊之处,镜像采用的是curl,此pod是一种是一个网络工具箱,里面包含了curl等一些常用的命令,执行3600的意义在于使容器处于一个长期运行的状态。
[root@master ~]# kubectl apply -f testheadless1.yaml
pod/testheadless1 created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
testheadless1 1/1 Running 0 4s
[root@master ~]# kubectl exec -it testheadless1 -- /bin/sh
/ # nslookup testheadless.default.svc.cluster.local
nslookup: can't resolve '(null)': Name does not resolve
Name: testheadless.default.svc.cluster.local
Address 1: 10.244.1.49 10-244-1-49.testheadless.default.svc.cluster.local
Address 2: 10.244.1.50 10-244-1-50.testheadless.default.svc.cluster.local
Address 3: 10.244.1.52 10-244-1-52.testheadless.default.svc.cluster.local
/ # curl 10-244-1-49.testheadless.default.svc.cluster.local //通过curl来测试访问的域名,可以看出结果
<p> The host is deploymenthttp-7fbc9958f5-w9b8g </p>
//由以上内容可知,总共返回了三个IP地址,这些IP是之前创建的每个Pod的IP地址,并且每个地址对应了不同的域名10-244-1-49.testheadless.default.svc.cluster.local,只不过是Pod中的地址不是固定的,所以域名并无任何作用。
向内发布-ExternalName
这种发布的方式是将外部的服务引进来,通过一定的格式映射到K8S集群,从而为集群内部提供服务。这种方式的服务没有选择器,也不需要定义任何的端口和端点,相反对于运行在集群外部的服务,通过返回外部服务别名的方式来提供服务。
[root@master ~]# vi testexternalname.yaml
apiVersion: v1
kind: Service
metadata:
name: testexternalname
spec:
type: ExternalName
externalName: www.baidu.com
//这种类型的Service定义的属性非常简单,只需要声明type类型即可,并通过设置externalName引入外部服务的地址即可。
[root@master ~]# kubectl apply -f testexternalname.yaml
service/testexternalname created
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
testexternalname ExternalName <none> www.baidu.com <none> 22s
在前面我们已经创建了一个测试Service的Pod,现在需要基于这个pod来验证。
[root@master ~]# kubectl exec -it testheadless1 -- /bin/sh
/ # nslookup testexternalname.default.svc.cluster.local
nslookup: can't resolve '(null)': Name does not resolve
Name: testexternalname.default.svc.cluster.local
Address 1: 110.242.68.4
Address 2: 110.242.68.3
/ # nslookup www.baidu.com
nslookup: can't resolve '(null)': Name does not resolve
Name: www.baidu.com
Address 1: 110.242.68.4
Address 2: 110.242.68.3
//从以上结果可知,我们已经解析出来了两个地址,这两个地址就是百度的网址,所以使用这两个地址也可以直接访问百度。
Ingress
在使用Ingress时,服务无需对外暴露端口直接向外发布服务,而是统一由Ingress接受外部请求,然后通过域名配置转发给各个后端服务。
在使用Ingress时一般要涉及三个组件:
(1)反向代理的负载均衡器:类似于Nginx的应用。它可以通过Deployment或者DaemonSet控制器来自由部署。
(2)Ingress控制器:实质上起到监控作用。与API server不断进行交互,实时的感知后端的Service与Pod的变化,接收到这些信息之后,Ingress控制器在和Ingress生成配置,然后更新反向代理负载均衡器并刷新配置,达到服务发现的目的。
(3)Ingress:定义访问规则。
Ingress的安装
首先部署一个RBAC(基于角色的访问控制),Role Based Acess Control,作用是与K8s的资源和API 进行交互控制(细粒度)。
[root@master ~]# cat traefik-rabc.yaml
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: traefik-ingress-controller
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- secrets
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses/status
verbs:
- update
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: traefik-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: traefik-ingress-controller
subjects:
- kind: ServiceAccount
name: traefik-ingress-controller
namespace: kube-system
[root@master ~]# kubectl apply -f traefik-rabc.yaml
clusterrole.rbac.authorization.k8s.io/traefik-ingress-controller created
clusterrolebinding.rbac.authorization.k8s.io/traefik-ingress-controller created
[root@master ~]# kubectl apply -f traefik-ds.yaml
serviceaccount/traefik-ingress-controller created
daemonset.apps/traefik-ingress-controller created
service/traefik-ingress-service created
[root@master ~]# kubectl get rc,svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-dns ClusterIP 10.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 14d
service/traefik-ingress-service ClusterIP 10.1.69.70 <none> 80/TCP,8080/TCP 28s
[root@master ~]# kubectl get pods --all-namespaces -o wide --selector=k8s-app=traefik-ingress-lb
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system traefik-ingress-controller-b2vqt 1/1 Running 0 49s 10.244.1.64 worker2 <none> <none>
kube-system traefik-ingress-controller-nx6d8 1/1 Running 0 49s 10.244.0.132 master <none> <none>
kube-system traefik-ingress-controller-s8plk 1/1 Running 0 49s 10.244.2.205 worker1 <none> <none>
[root@master ~]# kubectl describe pod traefik-ingress-controller-6b7f594d46-4ltw6 -n kube-system |grep IP
IP: 10.244.0.128
IPs:
IP: 10.244.0.128
//通过命令查询Pod的地址,然后使用命令去访问
[root@master ~]# curl 10.244.0.128
404 page not found
//由访问结果可知,我们的服务已经成功部署,但是访问失败,是因为我们没有配置资源,所以显示404 page not found,接下分别使用宿主机加端口的方式进行访问(浏览器)。
[root@master ~]# curl 192.168.200.11:30265
404 page not found
[root@master ~]# curl 192.168.200.12:30265
404 page not found
[root@master ~]# curl 192.168.200.13:30265
404 page not found
//因为traefik会在每个node上暴露80端口提供服务,所以我们可以采用宿主机去进行访问
[root@master ~]# curl 192.168.200.11
404 page not found
[root@master ~]# curl 192.168.200.12
404 page not found
Ingress基本操作
首先创建两个实例,分别为nginx和httpd,这两个服务分别是由Deployment和Service组成。
(1)创建Deployment-nginx和Deployment-http
[root@master ~]# cat deployment-ingress-web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
example: deployment-ingress-nginx
template:
metadata:
labels:
example: deployment-ingress-nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-ingress-http
spec:
replicas: 1
selector:
matchLabels:
example: deployment-ingress-http
template:
metadata:
labels:
example: deployment-ingress-http
spec:
containers:
- name: http
image: httpd:2.2
ports:
- containerPort: 80
[root@master ~]# kubectl apply -f deployment-ingress-web.yaml
deployment.apps/deployment-ingress-nginx created
deployment.apps/deployment-ingress-http created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
deployment-ingress-http-57cc6785c4-n69jx 1/1 Running 0 11s
deployment-ingress-nginx-9d9bd84d9-qpt4g 1/1 Running 0 11s
(2)创建对应的Service
[root@master ~]# cat service-ingress-web.yaml
apiVersion: v1
kind: Service
metadata:
name: servicenginx
spec:
selector:
example: deployment-ingress-nginx
ports:
- protocol: TCP
port: 8081
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: servicehttp
spec:
selector:
example: deployment-ingress-http
ports:
- protocol: TCP
port: 8081
targetPort: 80
[root@master ~]# kubectl apply -f service-ingress-web.yaml
service/servicenginx created
service/servicehttp created
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
servicehttp ClusterIP 10.1.76.137 <none> 8081/TCP 108s
servicenginx ClusterIP 10.1.8.103 <none> 8081/TCP 109s
(3)分别采用集群地址访问这两个服务
[root@master ~]# curl 10.1.76.137:8081
<html><body><h1>It works!</h1></body></html>
[root@master ~]# curl 10.1.8.103:8081
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
定义存储卷与配置
在K8S中定义的存储卷主要包含了四种类型。
(1)本地存储卷:主要适用于Pod中容器之间的数据共享,或者实现Pod与Node数据存储和共享
(2)网络存储卷:主要是用于多个Pod之间或者多个Node之间的数据存储和共享。
(3)持久存储卷:基于网络存储卷,用户无需关心存储卷所使用的存储系统,只需要定义所需要消费的资源,可以将Pod与具体的存储系统解耦。
(4)配置存储卷:用于向各个Pod注入配置信息。
1.本地存储卷
本地存储卷包含了emptyDir和HostPath两种类型,都会使用本地文件系统,用于Pod中容器之间的数据共享,或者Pod与Node中的数据存储和共享。
(1)emptyDir(干净的空目录)
把这个目录来映射到主机的一个临时目录下,Pod中的所有的容器都可以读写这个目录,对其生命周期管理和Pod完全一致。其作用主要是用于存放和共享Pod的不同容器之间在运行过程中产生的文件。
[root@master ~]# vi testemptyDir.yaml
apiVersion: v1
kind: Pod
metadata:
name: testemptydir
spec:
apiVersion: v1
kind: Pod
metadata:
name: testemptydir
spec:
containers:
- name: containerwrite
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "This is a test data!" >/write_dir/data; sleep 3600']
volumeMounts:
- name: filedata
mountPath: /write_dir
- name: containerread
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['cat /read_dir/data; sleep 3600']
volumeMounts:
- name: filedata
mountPath: /read_dir
volumes:
- name: filedata
emptyDir: {}
[root@master ~]# kubectl apply -f testemptyDir.yaml
pod/testemptydir created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
testemptydir 1/1 Running 0 20s
[root@master ~]# kubectl logs testemptydir containerread
This is a test data!
(2)HostPtah
把主机上指定的目录映射到Pod中的容器上,如果Pod需要在主机上存储或共享文件,或者使用主机上的文件,就可以采用这种方式。存放在主机上的文件不会被销毁,会永久保存。Pod被销毁后,如果在这条台机器上重建,可以再次读取原来的内容,但是如果这台机器出现故障或者Pod被调度在了其他节点上,就无法再次读取原来内容。
这种方式比较适合DaemonSet控制器,运行于DaemonSet控制器下的Pod可以直接操作或者使用主机上的文件。
[root@master ~]# vi testhostpath.yaml
apiVersion: v1
kind: Pod
metadata:
name: testhostpath
spec:
containers:
- name: containerhostpath
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "This is a test data!" >/write_dir/data; sleep 3600']
volumeMounts:
- name: filedata
mountPath: /write_dir
volumes:
- name: filedata
hostPath:
path: /home/k8sadmin/testhostpath
//在这个yaml文件中,我们创建了一个名字为containerhostpath的容器,然后需要向这个容器中写入数据,数据为“This is a test data!”,容器内数据卷的地址为/write_dir,引用的存储卷为filedata。在这个例子中存储卷的名字为filedata,这个存储卷会被容器设置的数据卷所引用。存储卷的类型为hostPath,代表主机上指定的目录,路径为/home/k8sadmin/testhostpath,容器中的 /write_dir会映射到主机的 /home/k8sadmin/testhostpath目录下。
[root@master ~]# kubectl apply -f testhostpath.yaml
pod/testhostpath created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
testhostpath 1/1 Running 0 15s
[root@master ~]# kubectl describe pod testhostpath |grep Node
Node: worker2/192.168.200.13
//可以从pod详细信息中查看到pod调度的位置在worker2节点,所以需要去worker2节点上,查找宿主机的映射目录
[root@worker2 ~]# cat /home/k8sadmin/testhostpath/data
This is a test data!
//我们可以看到容器中的数据已经被同步映射到宿主机目录下,然后可以对数据进行修改
[root@worker2 ~]# echo "This is test data! change1" > /home/k8sadmin/testhostpath/data
//再次查看,容器中的数据
[root@master ~]# kubectl exec -it testhostpath -- /bin/sh
/ # cat /write_dir/data
This is test data! change1
网络存储卷(以NFS为例)
网络存储卷能够满足数据持久化的需求,能够永久保存数据。
一、安装NFS服务
1.安装NFS服务器(master节点)
[root@master ~]# yum -y install nfs-utils rpcbind
2.创建共享目录
[root@master ~]# mkdir -p /data/k8snfs
3.配置共享参数
[root@master ~]# vi /etc/exports
/data/k8snfs 192.168.200.0/24(rw,sync,insecure,no_subtree_check,no_root_squash)
// /data/k8snfs:共享目录 192.168.200.0/24:共享网段,也可以改为*,表示不限制网段 rw:表示读写权限 sync:表示所有数据在请求时写入共享目录 insecure:表示NFS通过1024以上的端口进行发送 no_subtree_check:不检查父目录的权限 no_root_squash:表示root用户对根目录具有完全管理访问的权限
4.重启nfs服务
[root@master ~]# systemctl restart rpcbind
[root@master ~]# systemctl restart nfs
5.检查是否加载nfs服务端的配置
[root@master ~]# exportfs -r
[root@master ~]# showmount -e 192.168.200.11
Export list for 192.168.200.11:
/data/k8snfs 192.168.200.0/24
6.K8S集群客户端的两台机器安装nfs(以worker1为例)
[root@worker1 ~]# yum -y install nfs-utils rpcbind
[root@worker1 ~]# systemctl restart nfs
[root@worker1 ~]# showmount -e 192.168.200.11
Export list for 192.168.200.11:
/data/k8snfs 192.168.200.0/24
二、使用NFS服务
1.书写yaml文件
接下来使用NFS作为存储卷,NFS中的数据能够被永久的存储,而且能够被多个Pod同时读写。
[root@master ~]# vi testk8snfs.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: testk8snfs
spec:
replicas: 2
selector:
matchLabels:
example: testk8snfs
template:
metadata:
labels:
example: testk8snfs
spec:
containers:
- name: containersnfs
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh','-c']
args: ['echo "The host is $(hostname)" >> /dir/data; sleep 3600']
volumeMounts:
- name: nfsdata
mountPath: /dir
volumes:
- name: nfsdata
nfs:
path: /data/k8snfs/
server: 192.168.200.11
2.创建服务
[root@master ~]# kubectl apply -f testk8snfs.yaml
deployment.apps/testk8snfs created
3.查看控制器以及pod
[root@master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
testk8snfs 2/2 2 2 32s
[root@master ~]# kubectl get pod |grep testk8s
testk8snfs-7b89b86bd5-d9p44 1/1 Running 0 67s
testk8snfs-7b89b86bd5-kxnhm 1/1 Running 0 67s
4.验证两个pod是否都读写了同一存储卷上的同一个文件
【第一个pod】
[root@master ~]# kubectl exec -it testk8snfs-7b89b86bd5-d9p44 -- /bin/sh
/ # cat /dir/data
The host is testk8snfs-7b89b86bd5-d9p44
The host is testk8snfs-7b89b86bd5-kxnhm
//通过Deployment控制器创建的两个Pod都已经成功的将信息,写入进了同一个文件,接下来我们验证一下另外一个pod的同步,首先在第一个Pod上修改data文件内容,如下:
/ # vi /dir/data
The host is testk8snfs-7b89b86bd5-d9p44
The host is testk8snfs-7b89b86bd5-kxnhm
Hello gongfanggaoshou!
/ # exit
command terminated with exit code 130
【第二个pod】
[root@master ~]# kubectl exec -it testk8snfs-7b89b86bd5-kxnhm -- /bin/sh
/ # cat /dir/data
The host is testk8snfs-7b89b86bd5-d9p44
The host is testk8snfs-7b89b86bd5-kxnhm
Hello gongfanggaoshou!
/ # exit
//从以上结果可知,两个pod之间已经实现了文件同步,另外利用NFS还实现了pod与宿主机之间的共享。接下来回到宿主机查看。
【宿主机】
[root@master ~]# cat /data/k8snfs/data
The host is testk8snfs-7b89b86bd5-d9p44
The host is testk8snfs-7b89b86bd5-kxnhm
Hello gongfanggaoshou!















 5779
5779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









