







微信公众号:信安文摘
通过一个微信小程序接口搜集目标单位域名,学习。
原文链接:奇安信攻防社区-微信小程序域名收集工具开发
https://forum.butian.net/share/890
代码请复制原文。
在一个风和日丽的中午,突然收到了上级领导发下的一个漏洞清单,估计是被外面的师傅搞了,通过几次的探测发现,该域名是集团下的某个平台小程序的域名,而漏洞也是很简单,就是个springboot的接口泄露,关键是这个小程序平时也不显眼,也没有给我们做过渗透,这下突然来了还把我们搞得措手不急,所以就想到,平时挖洞的话还是从小程序搞起,明细比web端好搞得多,所以为了之后能够快速的拿下小程序,域名收集就变得至关重要了,于是便有了下文中收集工具的开发探索。
一、白嫖大法
最开始呢,还是想直接在git或者其他地方直接找寻收集该域名的工具,找了一会发现了雷神众测的一位师傅有写到该域名的收集方法以及脚本,大家可以去网上搜索微信小程序寻魔篇可以看到师傅讲的还是非常不错,我寻思这么快就解决我想要的东西,真好

于是我就在网上将师傅的脚本嫖了下来进行分析,发现怎么也跑不通,下面就分析下为啥跑不通。
二、刨根问底
出现问题的接口是这个接口: https://mp.weixin.qq.com/mp/waverifyinfo
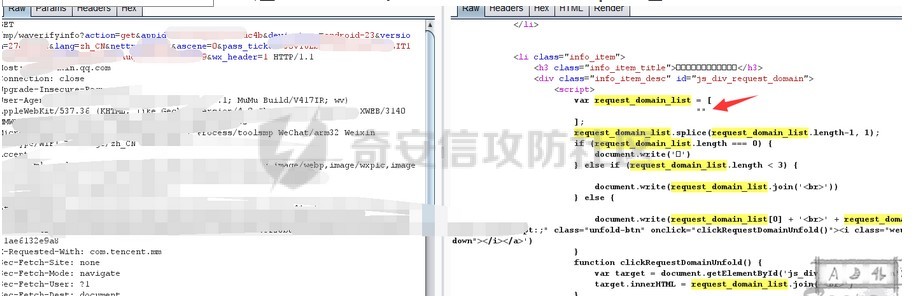
根据雷神众测师傅的分析,这个接口下的request_domain_list应该不为空才对,但我实际抓包看返回值确实空的,我想要的域名不在这里面,这就让我很难受。
三、请神大法
这个问题我弄了很久还是没研究明白,于是使出我的终极大法,找大神,在各个论坛也是问了个遍,终于在某个论坛找到我了我想要的答案,就是因为调用接口发生了改变,现在想要获取域名要调用这个接口:https://mp.weixin.qq.com/wxawap/waverifyinfo

雷神众测的师傅写了2个代码,更加细致的让大家明白查询APP_ID以及通过APP_ID进行查询小程序域名的思路,作为使用者,我还是希望能进行一下自己的优化,于是我就开始对代码进行改造,将2个代码合二为一,然后添加了几个功能,大概如下:黑名单功能,查询功能,批量导出功能,如下将一一介绍。
一、黑名单功能
1. `话不多说先贴代码,其实还是很简单,这里我做了个黑名单列表,研究发现以下2个域名后缀在跑除了某讯和政府(这个大家还是一直屏蔽了好)的网站还是能跑出来,然后将之前跑出的域名放进来过滤一下,大家可以自行判断屏蔽哪些域名,向black_domain_list中添加就行。`
1. `def black_domain_filter(res_domain_list):`
2. `black_domain_list = ['qq.com','gov.cn']`
3. `real_domian_list = []`
4. `for res in res_domain_list:`
5. `flag = 0`
6. `for bl in black_domain_list:`
7. `if bl in res:`
8. `flag = 1`
10. `if flag == 0:`
11. `real_domian_list.append(res)`
13. `return real_domian_list`
二、导出以及查询功能
1. `相信大家还是希望能手动直接导出文件然后开始跑起来吧。。。这里我导出了2个文件,一个为批量测试用的,一个为查询使用的。`
1. `def write_domain_list(query,all_domain_list,all_domain_list2):`
2. `t = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())`
3. `with open(query + '批量用'+ t + '.txt', 'w+', encoding='utf-8') as f:`
4. `for l in set(all_domain_list):`
5. `f.writelines(l+'\n')`
7. `with open(query + '查询用'+ t + '.txt', 'w+', encoding='utf-8') as f:`
8. `f.writelines('如果想查询某个域名属于哪个小程序,请访问地址:https://mp.weixin.qq.com/wxawap/waverifyinfo?action=get&appid=加上域名列表前的APPID即可')`
9. `for l in all_domain_list2:`
10. `str1 = ''`
11. `for i in l:`
12. `str1 =str1+i+','`
13. `f.writelines(str1+'\n')`
三、完整代码如下:
1. `#!/usr/bin/env python`
2. `# -*- encoding: utf-8 -*-`
3. `# time:2021/11/11`
4. `# author:Soufaker`
6. `import requests`
7. `import json`
8. `import sys`
9. `import time`
11. `# 获取APP_ID列表`
12. `def Get_App_Id_List(query,number,cookie):`
13. `headers={"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63030073)"}`
14. `url = "https://mp.weixin.qq.com/wxa-cgi/innersearch/subsearch"`
15. `params = "query=" + query + "&cookie=" + cookie + '&subsys_type=1&offset_buf= {"page_param":[{"subsys_type":1,"server_offset":0,"server_limit":' + str(number) + ',"index_step":' + str(number) + ',"index_offset":0}],"client_offset":0,"client_limit":' + str(number) + '}'`
16. `response = requests.post(url=url, params=params, headers=headers, timeout=10).text`
17. `Apps_Json = json.loads(response)`
18. `print(Apps_Json)`
19. `try:`
20. `App_Items = Apps_Json['respBody']['items']`
21. `for App_Item in App_Items:`
22. `App_Item_Json = json.loads(json.dumps(App_Item)) # 重新加载嵌套内容中的json数据`
23. `App_Id = App_Item_Json['appid']`
24. `App_Name = App_Item_Json['nickName']`
26. `if query in App_Name:`
27. `App_Id_List.append(App_Id)`
28. `print(App_Name)`
29. `except:`
30. `print('连接异常')`
32. `# 获取小程序域名`
33. `def Get_Domain(X_APP_ID):`
34. `headers={ "User-Agent": "Mozilla/5.0 (Linux; Android 6.0.1; MuMu Build/V417IR; wv)" } #微信两个校验值`
35. `url = "https://mp.weixin.qq.com/wxawap/waverifyinfo?"`
36. `params = "action=get&wx_header=1&appid=" + X_APP_ID`
37. `response = requests.get(url=url, params=params, headers=headers).text`
38. `resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "")`
39. `try:`
40. `if "request_domain:{item:[" in resp:`
41. `Response_domain_list = Get_MiddleStr(resp,"request_domain:{item:[",",]}};</sc")`
42. `real_list = black_domain_filter(Response_domain_list)`
44. `# 将要批量跑的域名写入列表1`
45. `for r in real_list:`
46. `All_domain_list.append(r)`
48. `real_list.insert(0,X_APP_ID)`
49. `real_list.insert(0,'------')`
51. `print(real_list)`
53. `# 将要查询的域名写入列表2`
54. `All_domain_list2.append(real_list)`
56. `except:`
57. `print('连接出现异常,请稍后重试或更换IP重试!')`
59. `time.sleep(0.1)`
61. `# 将一些不属于小程序的域名加入黑名单处理过滤`
62. `def black_domain_filter(res_domain_list):`
63. `black_domain_list = ['qq.com','gov.cn']`
64. `real_domian_list = []`
65. `for res in res_domain_list:`
66. `flag = 0`
67. `for bl in black_domain_list:`
68. `if bl in res:`
69. `flag = 1`
71. `if flag == 0:`
72. `real_domian_list.append(res)`
74. `return real_domian_list`
76. `# 选取想要的域名元素`
77. `def Get_MiddleStr(content,startStr,endStr): #获取中间字符串的⼀个通⽤函数`
78. `startIndex = content.index(startStr)`
79. `if startIndex>=0:`
80. `startIndex += len(startStr)`
81. `endIndex = content.index(endStr)`
82. `return content[startIndex:endIndex].split(',')`
84. `# 将跑出的域名写入文本`
85. `def write_domain_list(query,all_domain_list,all_domain_list2):`
86. `t = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())`
87. `with open(query + '批量用'+ t + '.txt', 'w+', encoding='utf-8') as f:`
88. `for l in set(all_domain_list):`
89. `f.writelines(l+'\n')`
91. `with open(query + '查询用'+ t + '.txt', 'w+', encoding='utf-8') as f:`
92. `f.writelines('如果想查询某个域名属于哪个小程序,请访问地址:https://mp.weixin.qq.com/wxawap/waverifyinfo?action=get&appid=加上域名列表前的APPID即可')`
93. `for l in all_domain_list2:`
94. `str1 = ''`
95. `for i in l:`
96. `str1 =str1+i+','`
97. `f.writelines(str1+'\n')`
99. `if __name__ == '__main__':`
100. `sys.getdefaultencoding() # 解决编码问题`
101. `query = input("请输⼊要搜的微信⼩程序名称: ")`
102. `number = input("请指定要返回的⼩程序的数量: ")`
103. `cookie = input("请输⼊你获取到的Cookie信息: ")`
105. `App_Id_List = []`
106. `All_domain_list = [] # 存放一个用来批量测试的域名列表`
107. `All_domain_list2 = [] # 提供一个查询列表`
108. `Get_App_Id_List(query,number,cookie)`
110. `# 当APP_ID_LIST为空时结束循环`
111. `while App_Id_List:`
112. `app_id = App_Id_List.pop(0)`
113. `Get_Domain(app_id)`
115. `# 写入文本`
116. `write_domain_list(query, All_domain_list,All_domain_list2)`
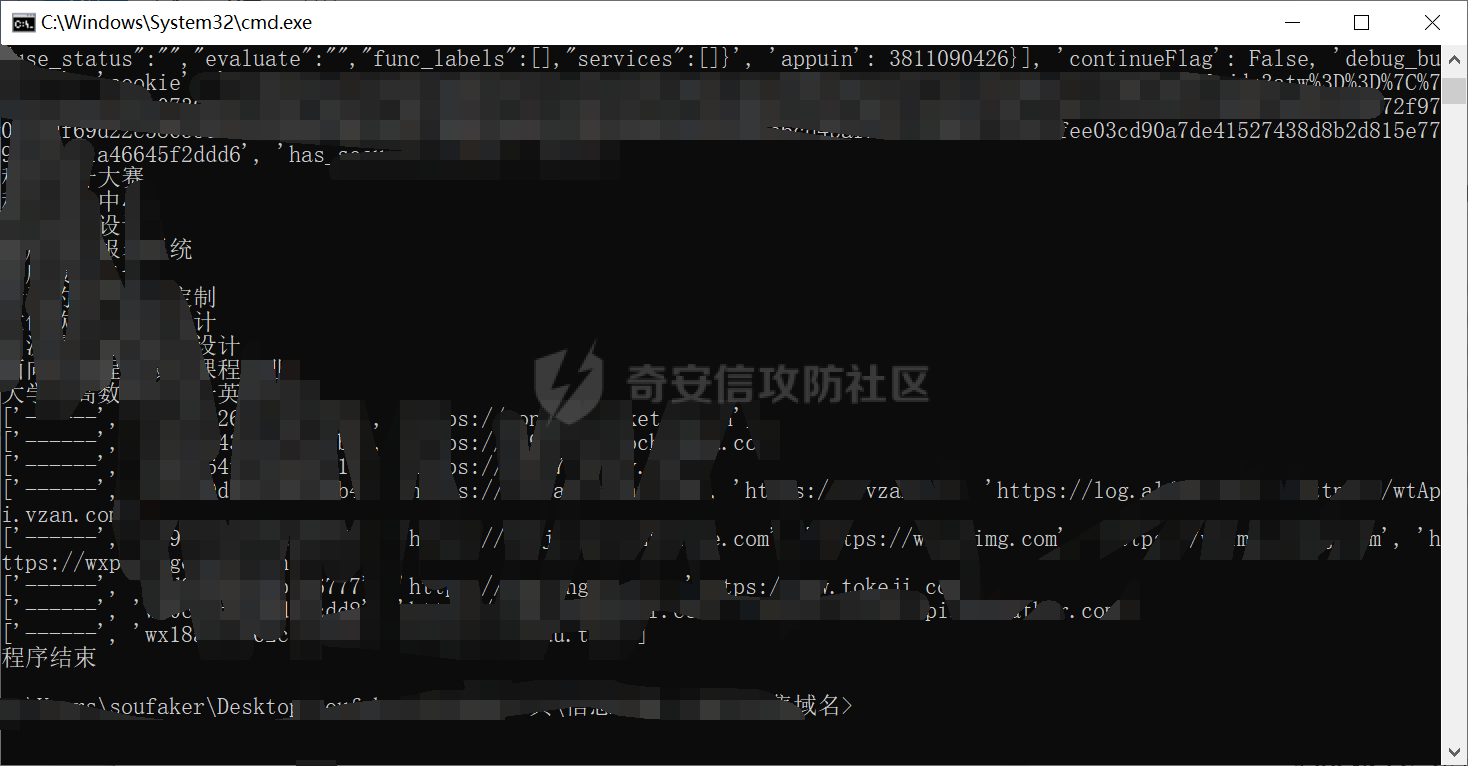
118. `print('程序结束')`
四、脚本使用步骤
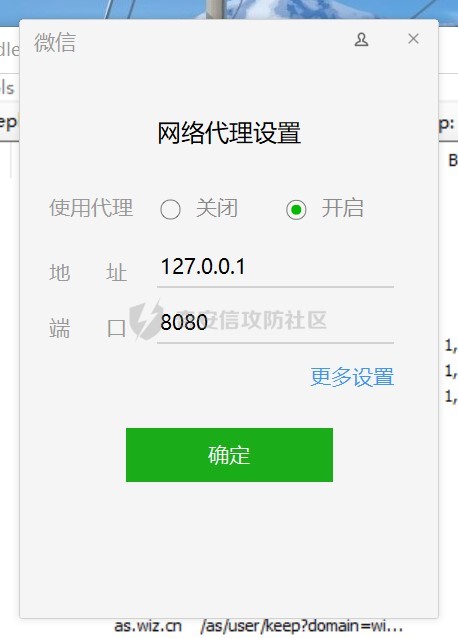
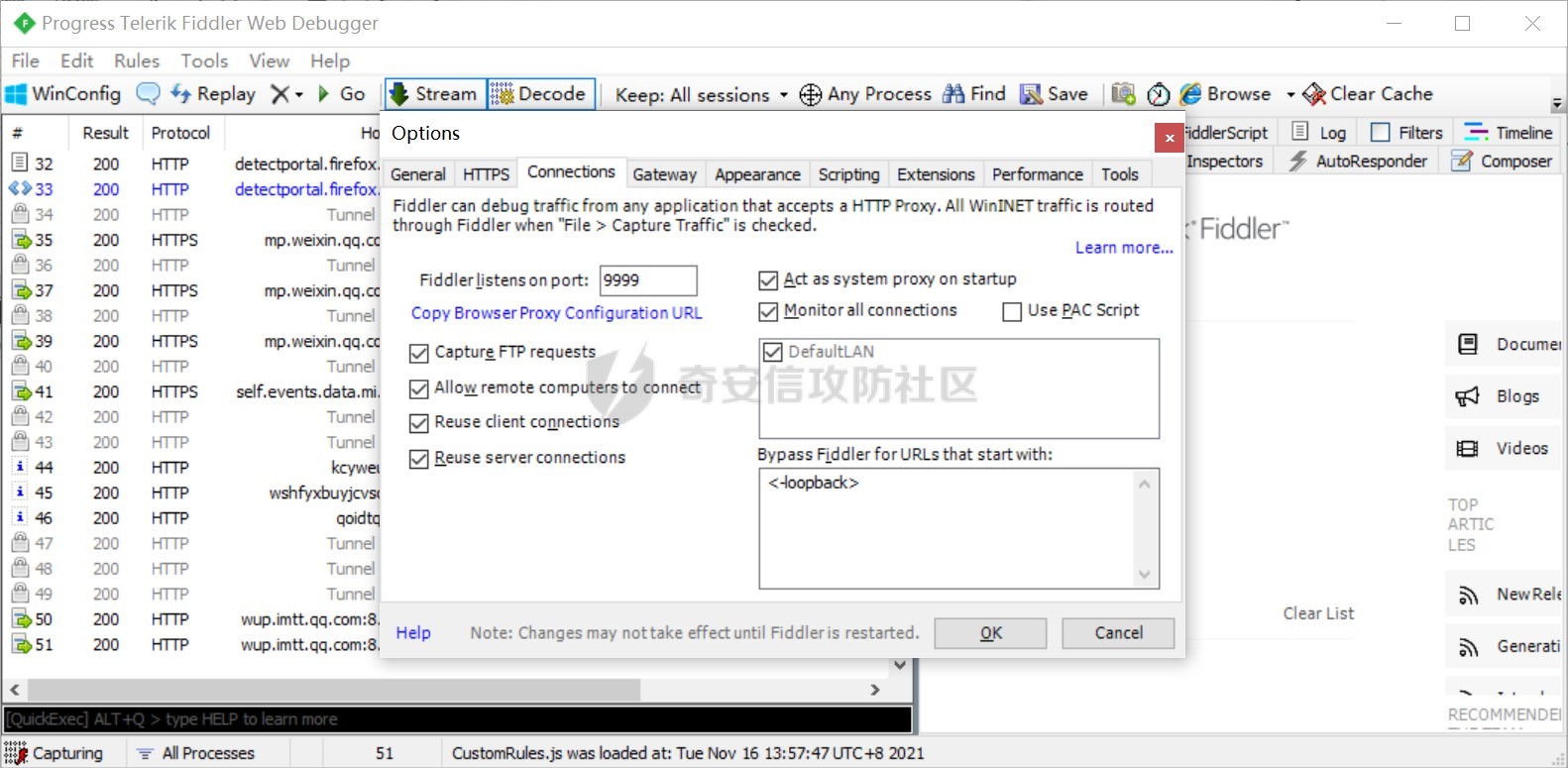
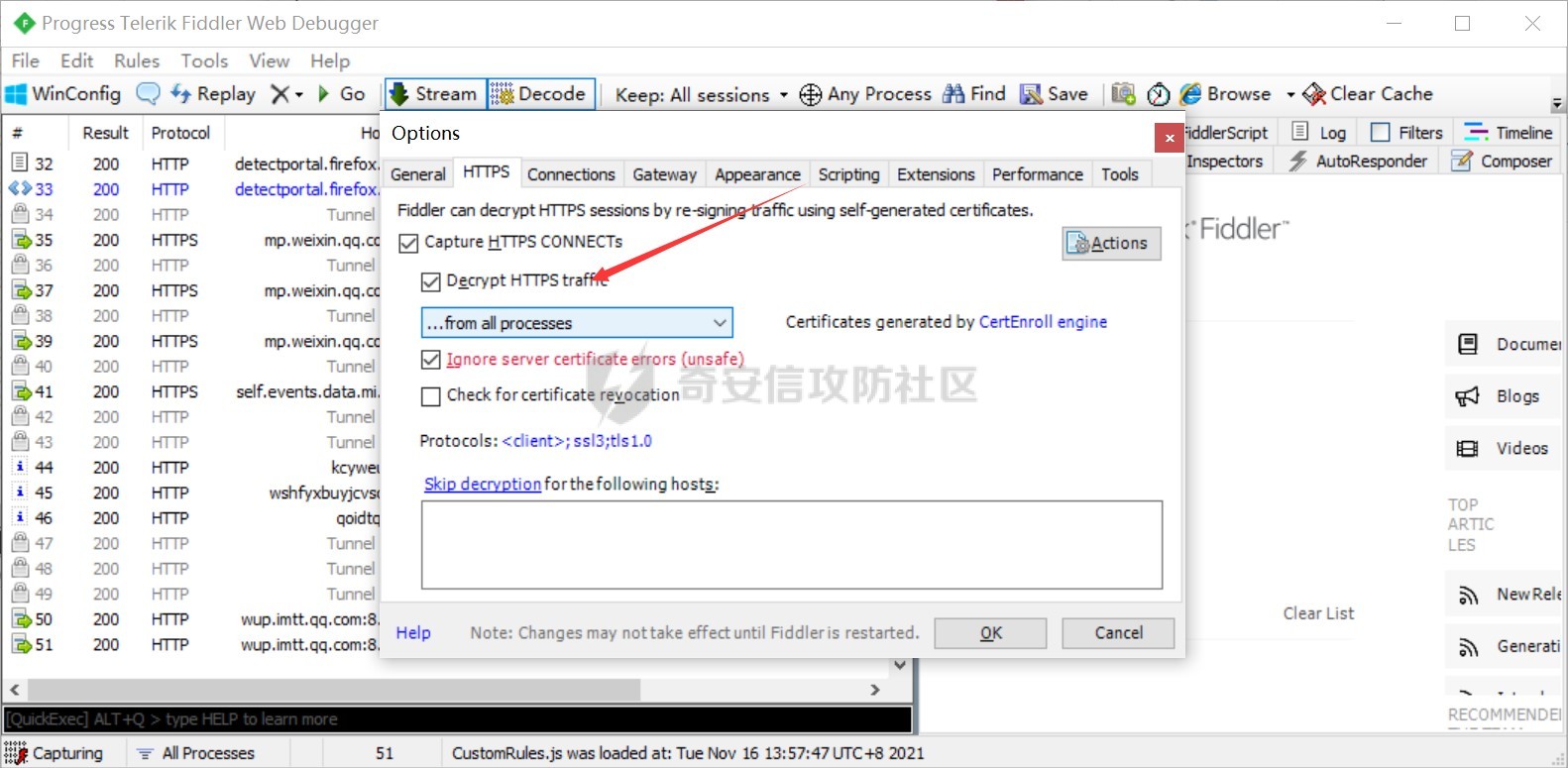
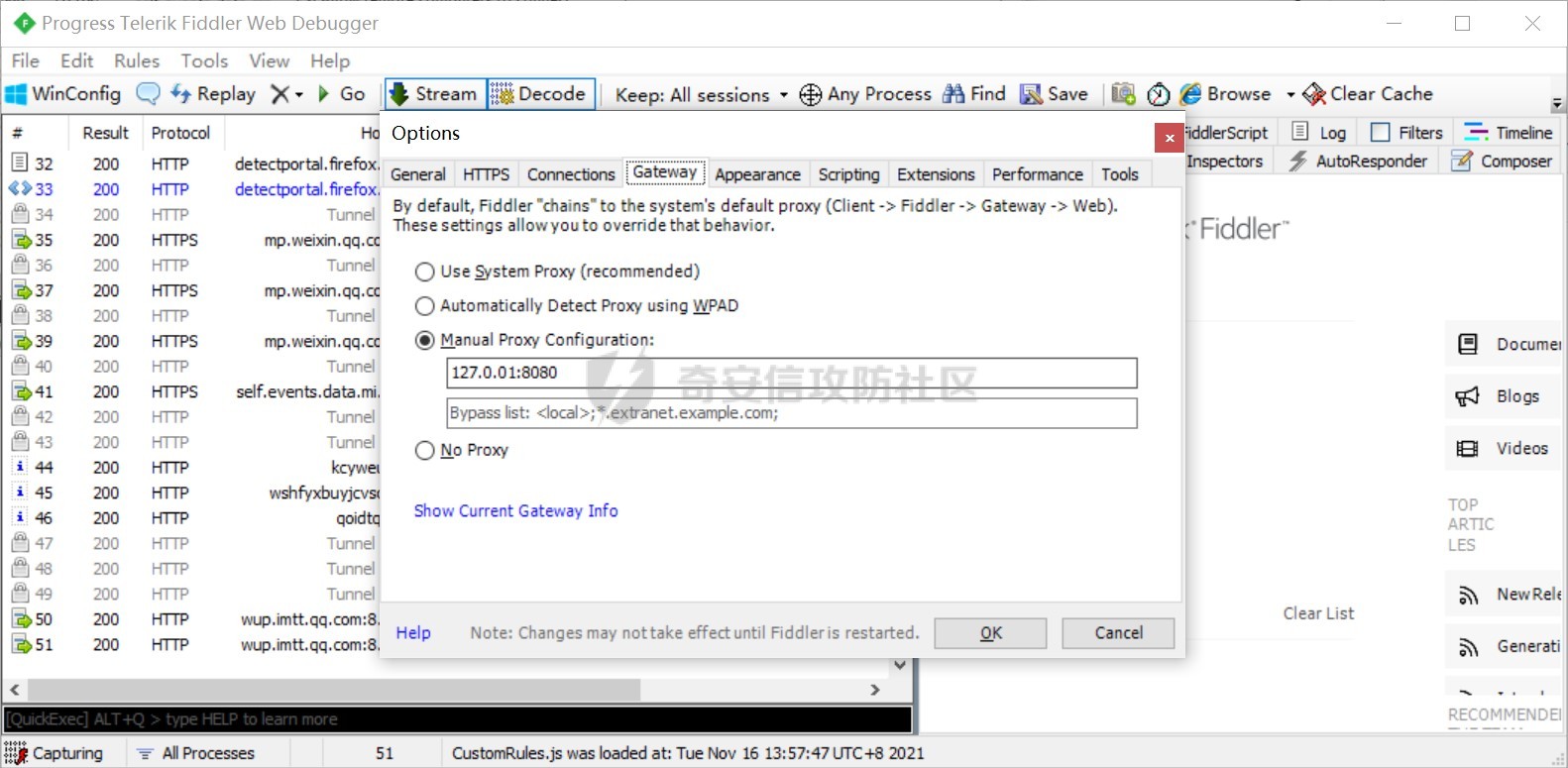
首先我们得抓取微信上搜索小程序使用的cookie,熟悉小程序抓包的师傅们就不用看了,这里我讲一个简单的方法,当然网上也有很多啦,我们登录电脑的微信,设置一个代理127.0.0.1:8080,bp也是这个代理,然后使用fildder4转发流量,设置步骤如下图就行了

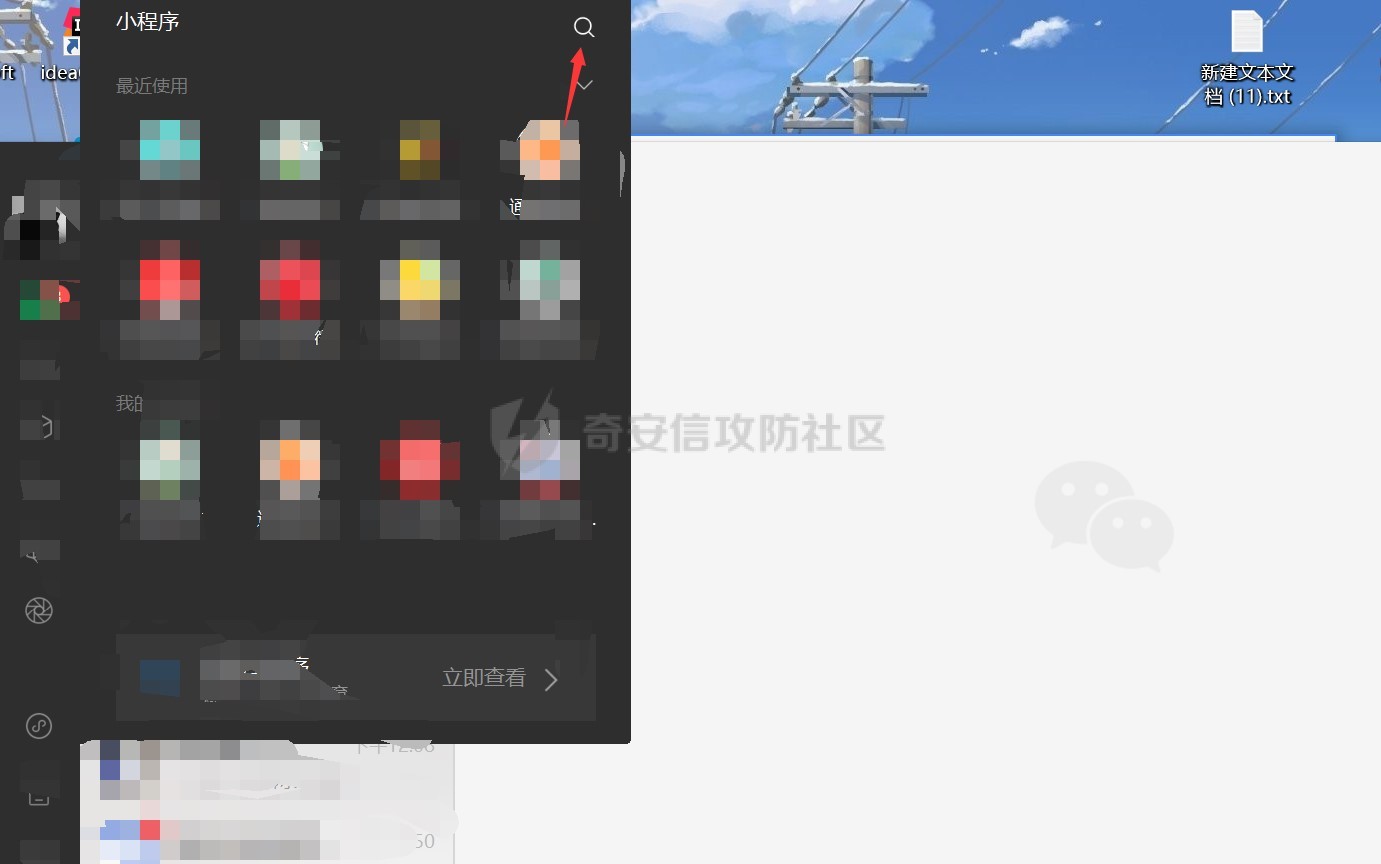
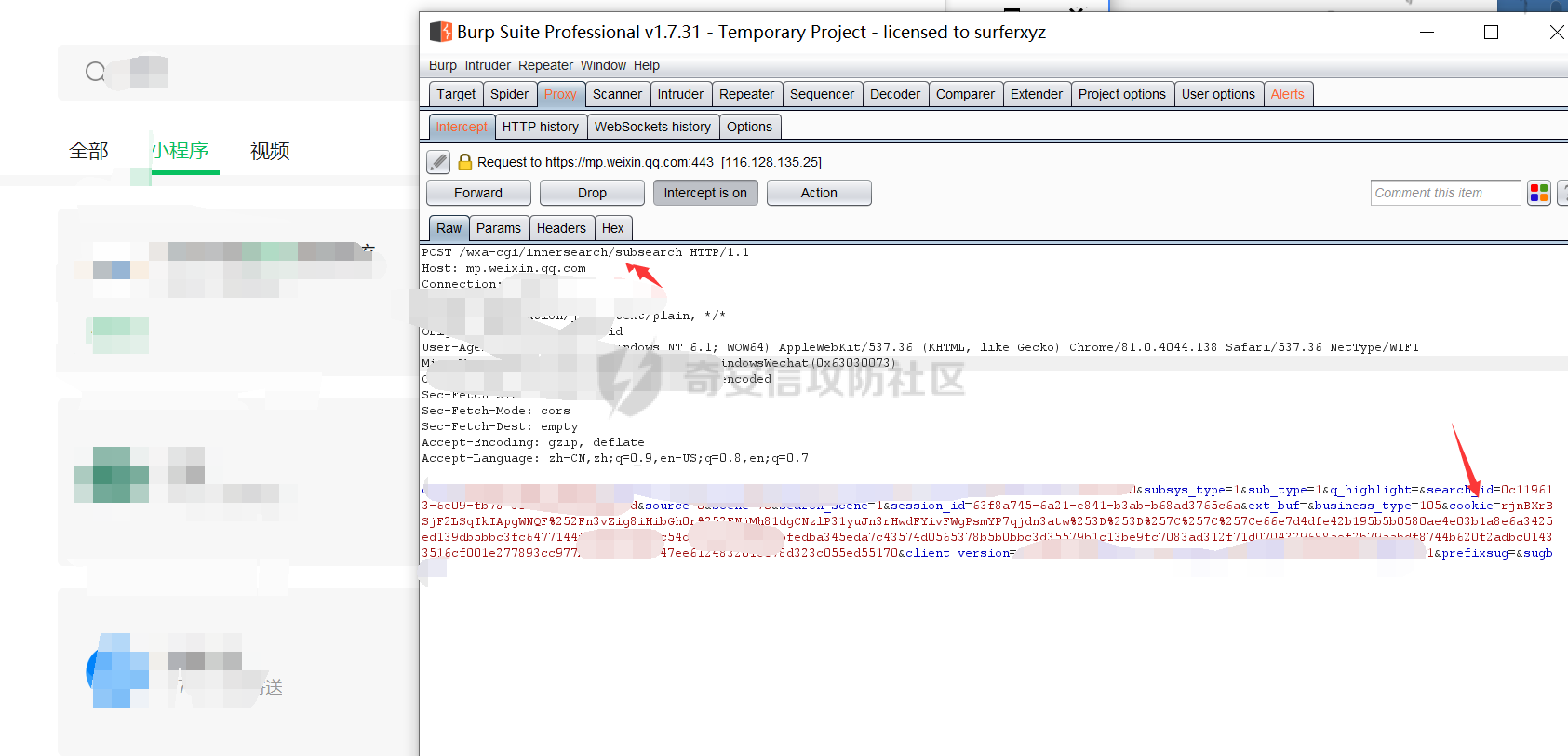
2.然后就可以登录微信搜索小程序,抓包获取到cookie值,如下图所示:
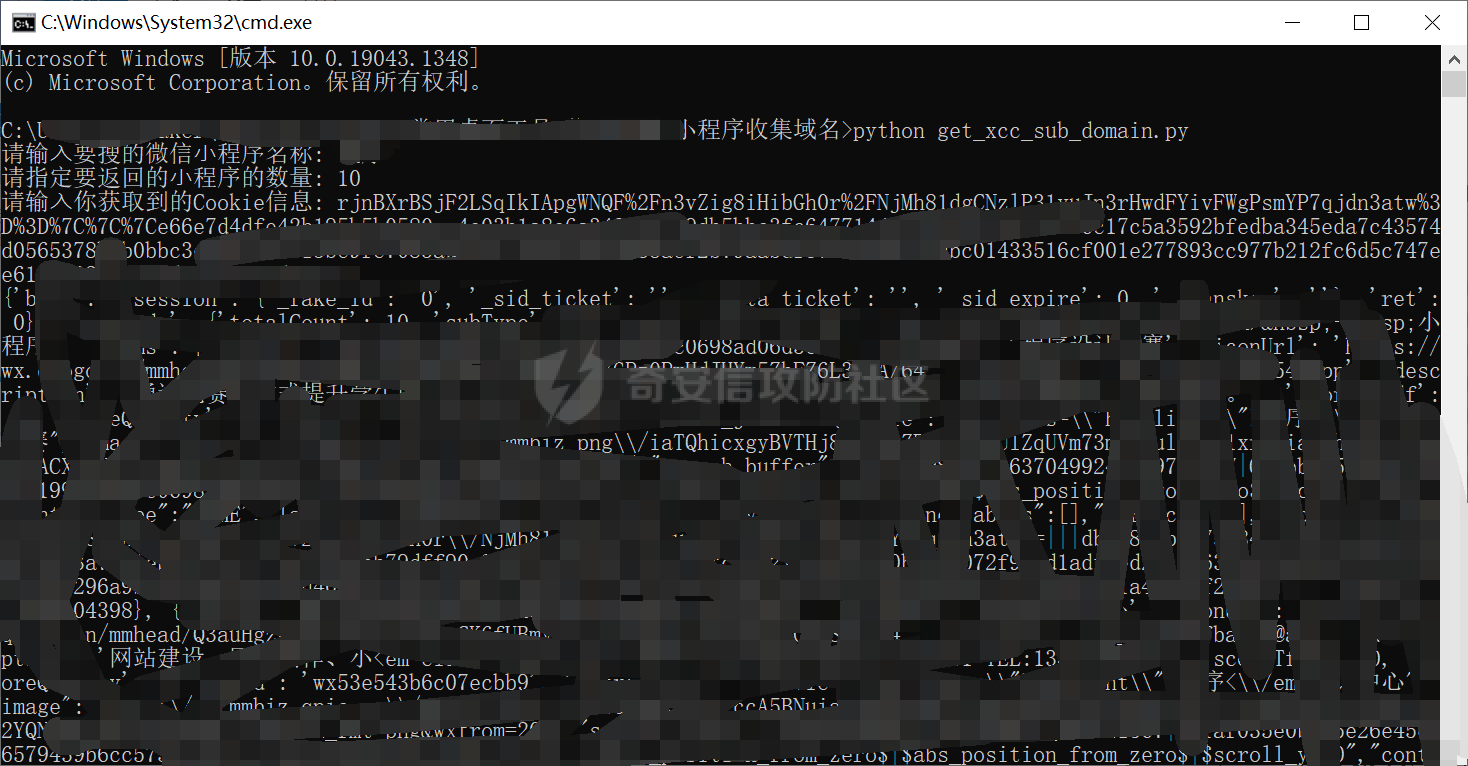
3.直接运行脚本,环境我python3,然后如下图,输入要跑的小程序以及数量就行了哈。

微信公众号:信安文摘

















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









