







 超级会员免费看
超级会员免费看
链接:https://pan.baidu.com/s/1KkkM1rLfyiMPtYLycpnxmg?pwd=j2rd
提取码:j2rd
--来自百度网盘超级会员V2的分享
采用数据集: https://aistudio.baidu.com/datasetdetail/130647
采用代码:
https://github.com/jfzhang95/pytorch-deeplab-xception
本文会讲解两种方法:一种是使用开源数据集(不是deeplab支持的数据集)完成在deeplab上训练,另一种是通过标注自定义数据集来完成训练
第一种用开源数据集训练
将carvana image masking challenge数据集转化为Pascal VOC 格式
以下讲述你需要更改的一些地方以及怎么更改
首先要看你的模型支持什么样的数据集,一般通过train.py文件或者通过github文档查看
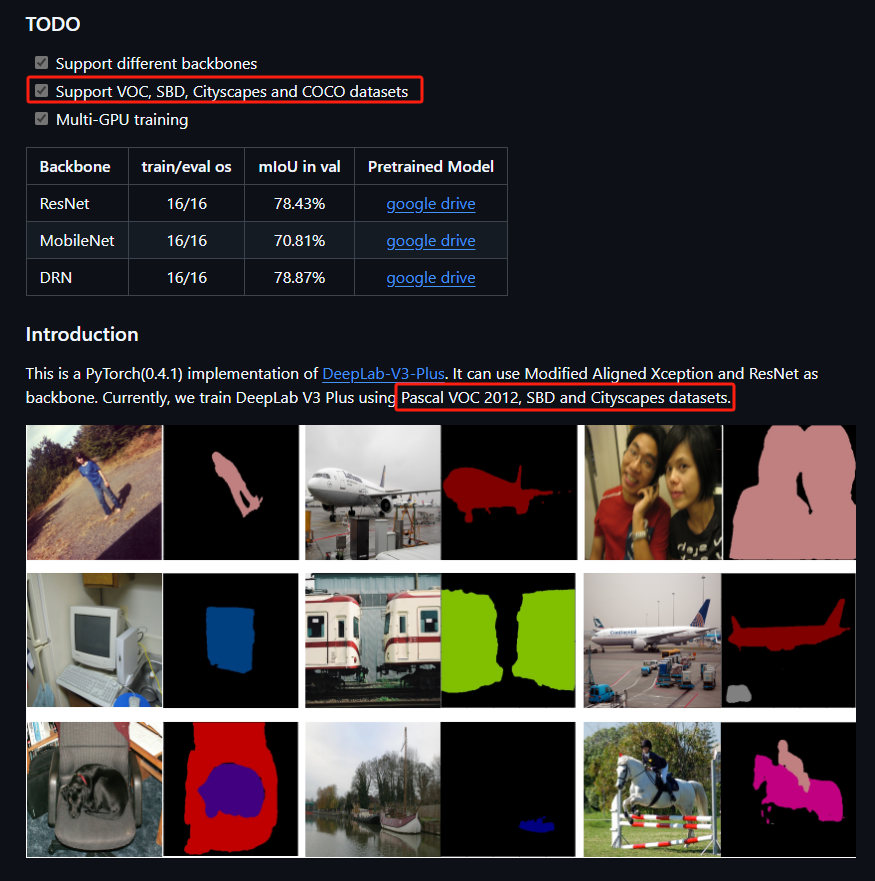
或者通过train.py

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









