







 文章讲述了在电脑没有内置立体声混音功能的情况下,如何使用Python的pyaudio库录制系统声音,作者发现了一个能处理此类情况的模块,解决了编程中遇到的问题。
文章讲述了在电脑没有内置立体声混音功能的情况下,如何使用Python的pyaudio库录制系统声音,作者发现了一个能处理此类情况的模块,解决了编程中遇到的问题。
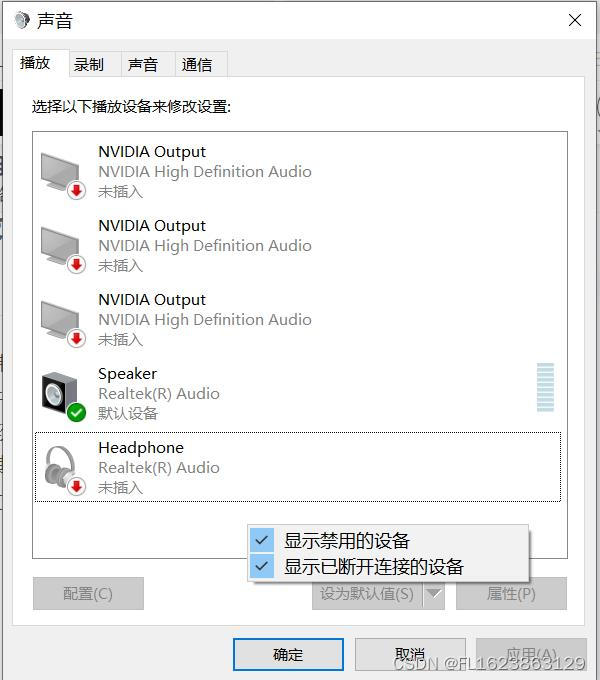
当电脑没有立体声混音导致Python写代码无法使用pyaudio进行录制系统声音怎么办?查阅资料和安装驱动等方法都不行,难道没办法了吗?那为什么电脑其他软件可以做到呢?因此研究了一下pyaudio在没有立体声混音情况下确实无法录制声音,而且其他比较流行的录制声音模块都试过不行,比如scikit声音模块,因此找到一个模块能录制系统声音,尤其speaker声音很重要,否则python编程没法录制系统声音岂不是表明自己编程太烂了?最终发现一个模块十分好用而且可以录制系统声音不需要设置什么立体声混音操作。我的电脑是暗影精灵6plus结果根本没有立体声混音如下:
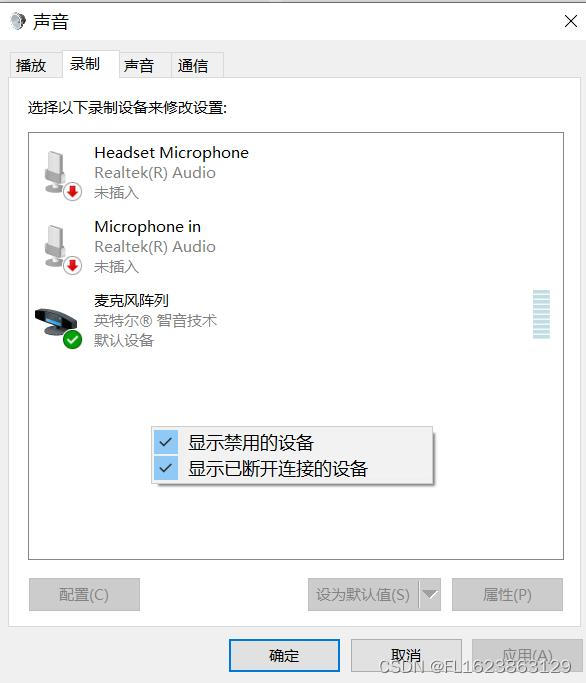
正常情况下人家是这样的
但是我尝试了很多方法甚至重装声卡驱动都没用,据说是主板不支持。难道python就没法用系统录音了吗,如果有立体声混音一般用下面代码即可录制
import numpy as np
from PIL import ImageGrab
import cv2
import pyaudio
import threading
import wave
import time
import ffmpeg
import getpass
import subprocess
import os
# 录音类
class Recorder():
def __init__(self, chunk=1024, channels=2, rate=44100):
self.CHUNK = chunk
self.FORMAT = pyaudio.paInt16
self.CHANNELS = channels
self.RATE = rate
self._running = True
self._frames = []
# 获取内录设备序号,在windows操作系统上测试通过,hostAPI = 0 表明是MME设备
def findInternalRecordingDevice(self, p):
# 要找查的设备名称中的关键字
target = '立体声混音'
# 逐一查找声音设备
for i in range(p.get_device_count()):
devInfo = p.get_device_info_by_index(i)
if devInfo['name'].find(target) >= 0 and devInfo['hostApi'] == 0:
# print('已找到内录设备,序号是 ',i)
return i
print('无法找到内录设备!')
return -1
# 开始录音,开启一个新线程进行录音操作
def start(self):
threading._start_new_thread(self.__record, ())
# 执行录音的线程函数
def __record(self):
self._running = True
self._frames = []
p = pyaudio.PyAudio()
# 查找内录设备
dev_idx = self.findInternalRecordingDevice(p)
if dev_idx < 0:
return
# 在打开输入流时指定输入设备
stream = p.open(input_device_index=dev_idx,
format=self.FORMAT,
channels=self.CHANNELS,
rate=self.RATE,
input=True,
frames_per_buffer=self.CHUNK)
# 循环读取输入流
while (self._running):
data = stream.read(self.CHUNK)
self._frames.append(data)
# 停止读取输入流
stream.stop_stream()
# 关闭输入流
stream.close()
# 结束pyaudio
p.terminate()
return
# 停止录音
def stop(self):
self._running = False
# 保存到文件
def save(self, fileName):
# 创建pyAudio对象
p = pyaudio.PyAudio()
# 打开用于保存数据的文件
wf = wave.open(fileName, 'wb')
# 设置音频参数
wf.setnchannels(self.CHANNELS)
wf.setsampwidth(p.get_sample_size(self.FORMAT))
wf.setframerate(self.RATE)
# 写入数据
wf.writeframes(b''.join(self._frames))
# 关闭文件
wf.close()
# 结束pyaudio
p.terminate()
# ffmpeg将音视频合并
def comband_av(AUDIO, VIDEO): # 音频视频合并
os.getcwd()
user_name = getpass.getuser()
str_txt = 'C:/Users/' + user_name + '/Desktop/'
os.chdir(str_txt)
cmd = f"ffmpeg -i {AUDIO} -i {VIDEO} comband_va.mp4 -y"
subprocess.call(cmd, shell=True)
if __name__ == "__main__":
os.getcwd()
user_name = getpass.getuser()
str_txt = 'C:/Users/' + user_name + '/Desktop/'
os.chdir(str_txt)
# 设置录制参数
SCREEN_SIZE = (2560, 1600)
FILENAME = 'recorded_video.avi'
FPS = 30.0
# 开始录制画面
fourcc = cv2.VideoWriter_fourcc(*"XVID")
out = cv2.VideoWriter(FILENAME, fourcc, FPS, SCREEN_SIZE)
# 开始录制音频
rec = Recorder()
begin = time.time()
rec.start()
cnt = 0
print('recording..')
while True:
# 获取屏幕截图
# img = pyautogui.screenshot()
img = ImageGrab.grab(bbox=(0, 0, 2560, 1600))
# 转换为OpenCV格式
frame = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
# 写入视频文件
out.write(frame)
# cv2.imshow('Frame', frame)
# cv2.resizeWindow('Frame', 1920, 1080)
# # 检测按键
# if cv2.waitKey(1) == ord('q'):
# break
cnt = cnt + 1
if cnt == 300:
rec.stop()
t = time.time() - begin
print('录制时间为%ds' % t)
rec.save("recorded_audio.wav")
break
# 停止录制
out.release()
cv2.destroyAllWindows()
comband_av("recorded_audio.wav", "recorded_video.avi") # 音频文件名,视频文件名自定义
但是立体声混音,在声音设备根本没有,因此找到一个模块可以很好解决录制系统声音问题,视频演示如下:
 https://www.bilibili.com/video/BV1qc411k7En/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
https://www.bilibili.com/video/BV1qc411k7En/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee源码下载地址:https://download.csdn.net/download/FL1623863129/88684677


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











