







原理简介
-
车牌字符识别使用的算法是opencv的SVM
-
opencv的SVM使用代码来自于opencv附带的sample,StatModel类和SVM类都是sample中的代码
-
训练数据文件
svm.dat和svmchinese.dat -
使用
图像边缘和车牌颜色定位车牌,再识别字符
# 主函数中初始化车牌识别需要的算法函数,并加载训练数据文件
self.predictor = predict.CardPredictor()
self.predictor.train_svm()
# lib下算法函数加载训练数据文件
class CardPredictor:
def __init__(self):
pass
# 加载训练数据文件
def train_svm(self):
# 识别英文字母和数字
self.model = SVM(C=1, gamma=0.5)
# 识别中文
self.modelchinese = SVM(C=1, gamma=0.5)
if os.path.exists("lib/svm.dat"):
self.model.load("lib/svm.dat")
if os.path.exists("lib/svmchinese.dat"):
self.modelchinese.load("lib/svmchinese.dat")
一. 车牌图像预处理
- 1.将彩色图像转化为灰度图

- 2.采用20*20模版对图像进行高斯模糊来缓解由照相机或其他环境噪声(如果不这么做,我们会得到很多垂直边缘,导致错误检测。)

- 3.使用Otsu自适应阈值算法获得图像二值化的阈值,并由此得到一副二值化图片

- 4.采用闭操作,去除每个垂直边缘线之间的空白空格,并连接所有包含 大量边缘的区域(这步过后,我们将有许多包含车牌的候选区域)
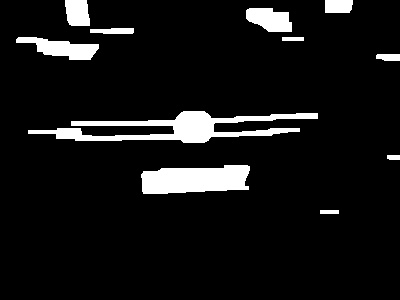
- 5.由于大多数区域并不包含车牌,我们使用轮廓外接矩形的纵横比和区域面积,对这些区域进行区分。
- a.首先使用findContours找到外部轮廓
- b.使用minAreaRect获得这些轮廓的最小外接矩形,存储在vector向量中
- c.使用面积和长宽比阈值,作基本的验证




二. 车牌图像定位
车牌定位的主要工作是从摄入的汽车图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来,供字符分割使用。 因此,牌照区域的确定是影响系统性能的重要因素之一,牌照的定位与否直接影响到字符分割和字符识别的准确率。 目前车牌定位的方法很多,但总的来说可以分为以下4类:
- (1)基于颜色的分割方法,这种方法主要利用颜色空间的信息,实现车牌分割,包括彩色边缘算法、颜色距离和相似度算法等;
- (2)基于纹理的分割方法,这种方法主要利用车牌区域水平方向的纹理特征进行分割,包括小波纹理、水平梯度差分纹理等;
- (3)基于边缘检测的分割方法;
- (4)基于数学形态法的分割方法。
为了代码实现上的方便,我采用的是基于边缘检测的分割方法和基于颜色的分割方法。
- 车牌中有大量的垂直边缘,这个特征可以定位车牌。
- 根据阈值找到对应颜色来定位车牌。
三. 车牌图像矩形矫正
因为摄像头和车辆车牌之间的角度有不同的变化, 一般所拍摄的车牌图像都不是理想状态下的矩形, 如果这样将会给后面的字符分割带来不利的影响, 增加了字符分割的难度, 更增加了后续的字符识别的困难, 造成识别率下降。因此, 在字符分割之前, 我们需要进行对倾斜的矩形车牌进行校正。
四. 车牌图像字符分割
要识别车牌字符,前提是先进行车牌字符的正确分割与提取。字符分割的任务是把多列或多行字符图像中的每个字符从整个图像中切割出来成为单个字符。车牌字符的正确分割对字符的识别是很关键的。传统的字符分割算法可以归纳为以下三类:直接分割法、基于识别基础上的分割法、自适应分割线类聚法。直接分割法简单,但它的局限是分割点的确定需要较高的准确性;基于识别基础上的分割法是把识别和分割结合起来,但是需要识别的高准确性,它根据分类和识别的耦合程度又有不同的划分;自适应分割线聚类法是要建立一个分类器,用它来判断图像的每一列是否是分割线,它是根据训练样本来进行自适应学习的神经网络分类器,但对于粘连字符训练困难。也有直接把字符组成的单词当作一个整体来识别的,诸如运用马尔科夫数学模型等方法进行处理,这些算法主要应用于印刷体文本识别。
- 已经定位好的车牌图像

- 车牌图像灰度化

- 车牌图像二值化

- 车牌二值化图像去除上下边框

- 去掉车牌上下边缘1个像素,避免白边影响阈值判断
- 分离车牌字符




五. 车牌图像字符识别
- 去除固定车牌的铆钉
- 对字符分割的图块使用训练好的svm模型进行识别
- 判断最后一个数是否是车牌边缘,假设车牌边缘被认为是1,1太细,认为是边缘
毕业设计基于Opencv的车牌识别系统
- 车牌搜索识别找出某个车牌号
- 对比识别车牌系统
- 车牌数据库认证系统
- 车牌图文搜索系统
- 车牌数据库搜索系统
- 文件图片识别车牌
- 网络图片地址识别车牌
- 实时截图识别车牌
- 图片自适应窗口大小
- 摄像头拍照识别车牌
- 使用 hyperlpr 提高识别率
开发环境配置
你可以选择使用 docker 搭建,或者 本地搭建环境,Linux 搭建,我相信不用介绍配置环境
这里仅介绍 docker 开发环境搭建 和 windows 快速搭建环境, 你也可以自己手动安装依赖
docker 开发环境搭建
macos 开发环境搭建
brew install tcl-tk pyenv # macos 12 最低只能安装此版本 pyenv install 3.7.13 brew install mysql@5.7 mysql.server start --skip-grant-tables mysql -uroot CREATE USER 'python'@'%' IDENTIFIED BY 'Python12345@'; CREATE database chepai; GRANT ALL PRIVILEGES ON *.* TO 'python'@'%';
windows 快速搭建环境
安装 python3.6
安装 python3.6 Python Release Python 3.6.6 | Python.org
下载 mysql 便携版
解压后,cmd 执行 start.bat
安装依赖
# 创建虚拟环境 python3 -m venv ./venv # 安装依赖 ./venv/bin/python3 -m pip install -r requirements.txt
运行演示
如果要自定义配置请新建 .env 文件,复制 .env.sample 的内容到 .env
使用前面的 docker 开发可跳过此步骤,请看 docker 文件夹下的文档
修改 .env 文件中的配置信息为自己百度api信息
修改 .env 文件中数据库相关改为自己的(地址,用户名。密码,数据库名字)
# 运行登录界面 python3 login.py # 运行主界面 python3 main.py # 运行车牌对比识别主界面 python3 match.py # 运行车牌搜索识别主界面 python3 search.py # 运行车牌认证主界面 python3 identification.py # 运行车牌数据库搜索主界面 python3 search_sql.py # 运行 停车场系统 python3 park.py
图片展示
车牌搜索识别找出某个车牌号

车牌对比识别前后是否一致
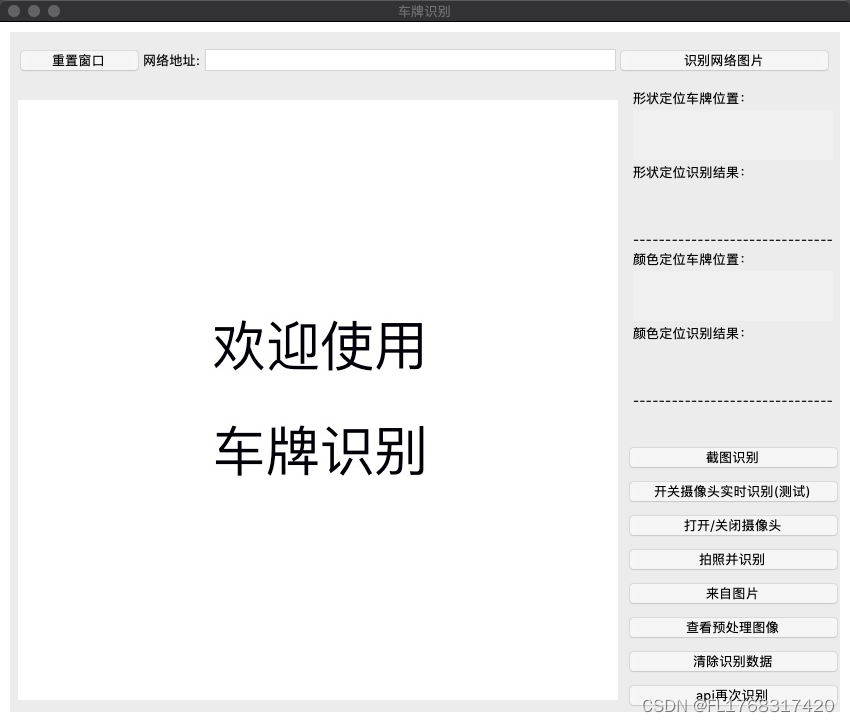
主界面

车牌认证

车牌数据库搜索

两种方法都无法识别时百度api(有手动按钮)

登录注册页面

运行数据写入数据库

本次运行数据写入excel (data.xls)

欢迎界面
完整源码下载:https://download.csdn.net/download/FL1768317420/89325386
















 3206
3206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











