







基于深度学习(LSTM)的情感分析(京东商城数据)
实验目的
通过LSTM算法,实现电商评论的情感分析。
实验流程
- 对京东网站进行分析,并且通过分布式爬虫进行数据采集
- 对采集到的数据进行清洗,包括删掉重复数据,删掉垃圾数据等
- 对清理好的数据进行分词,停词等操作,并对结果保存到新的文档
- 将分词之后的数据,通过word2vec,建立词向量和索引表
- 对清洗后的数据,进行数据处理,将分数为1、2的定为不满意,将分数为3,4,5的定为满意
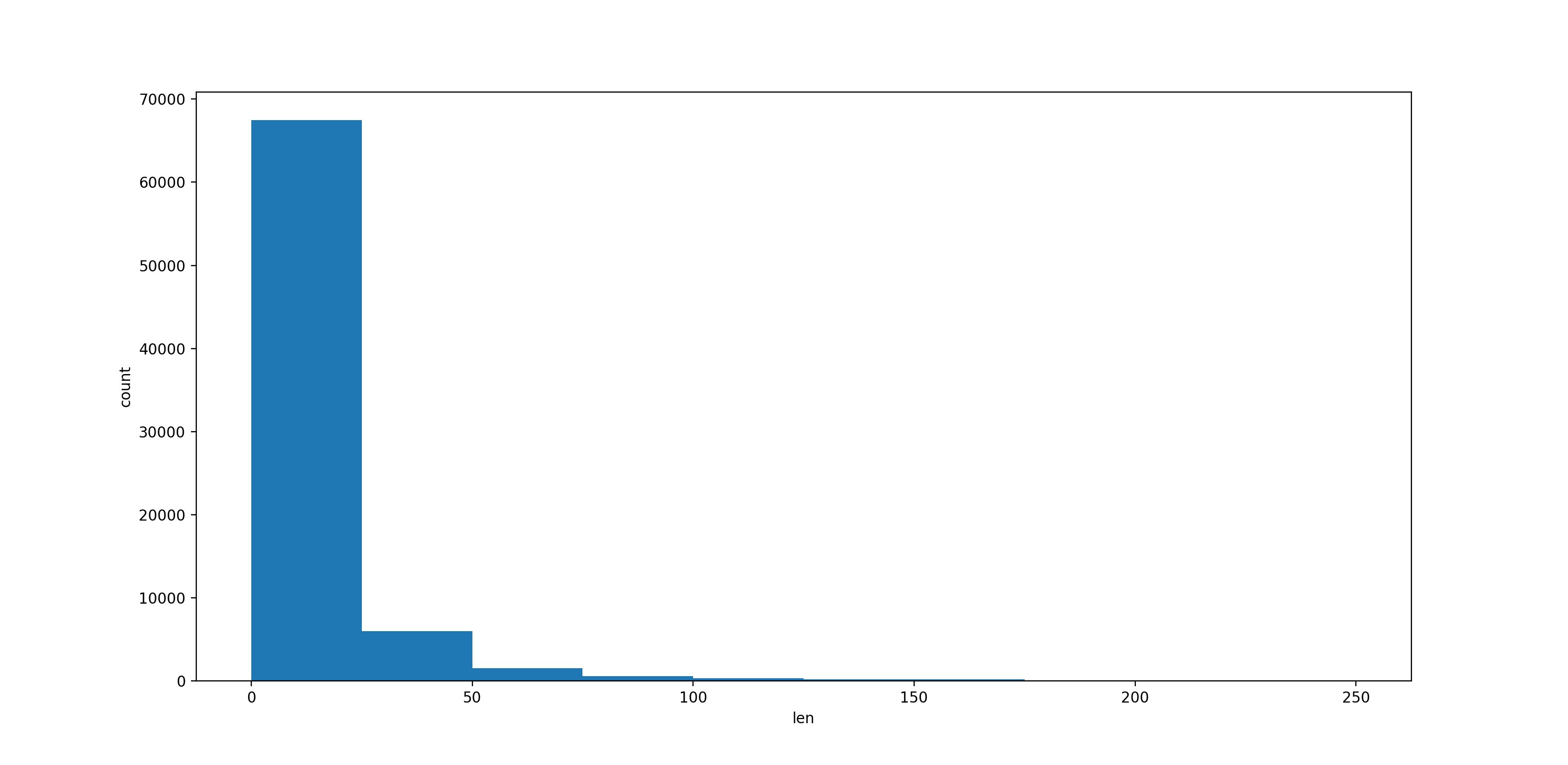
- 平衡正负样本数据,并且通过样本数据选出合适的文本长度值
- 词响亮与标签结合,生成可供训练的样本数据
- 建立分批(batch)函数
- 通过Tensorflow中的rnn模块进行lstm建模
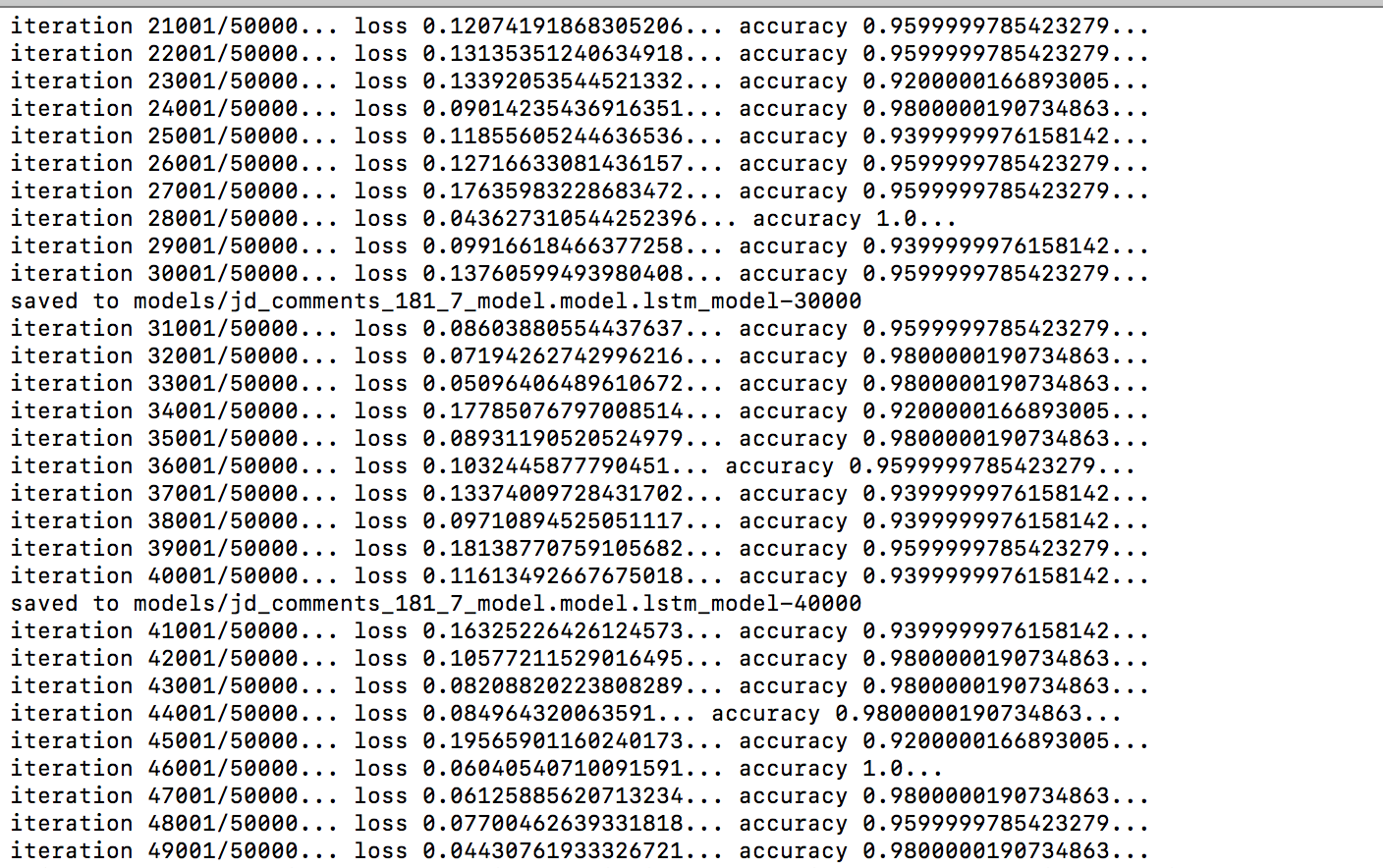
- 开始训练,每1000次输出一次结果,每10000次,保存一下模型
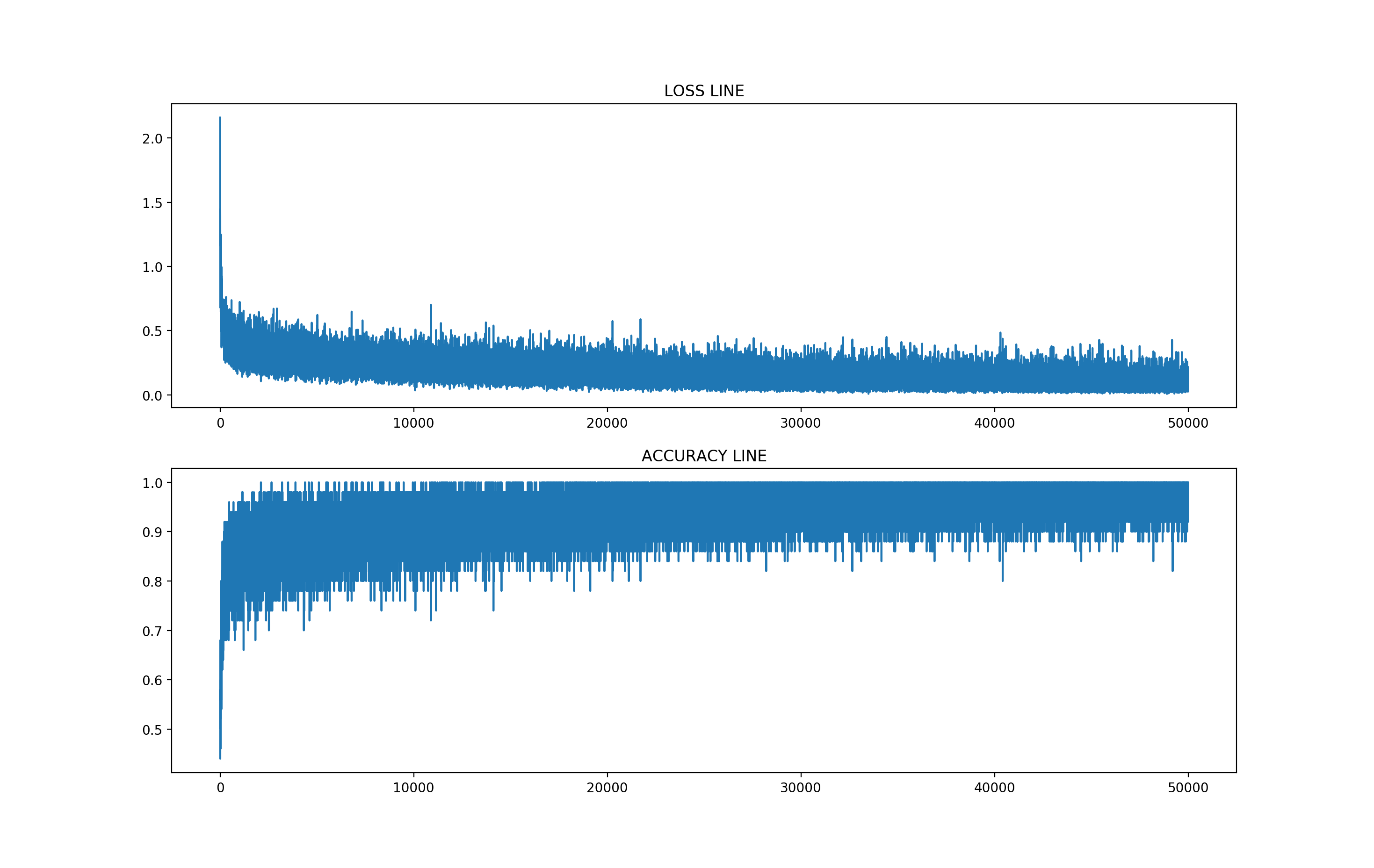
- 绘制loss和accurate图像
优化意见
- 采集数据转化为样本数据的过程可以更加合理,例如保留原始的1-5级评分作为情感程度(满意程度),将现有二分类问题变为多分类问题,同时通过其他用户对评论判定的“有用/无用”来对评价进行一个加权,例如有用>无用,情感程度加深,否则情感程度衰减,这样会使样本数据更加科学;
- 分词的时候和去除停用词的时候,将部分标点符号和一些语气词删掉了,但是实际上这些词很可能会严重影响表达情绪,所以在优化的时候可以考虑这部分词汇单独处理或者进行部分转化;
- 最佳句子长度选择的时候,超过该长度的样本进行切割,但是实际上这种方法可能会切割掉部分影响比较大的词汇,所以这里可以通过TF_IDF来进行一个权重计算,然后权重从高到低排序,再按照排序后的词汇进行切割,这样会尽可能地保留原句特征;
实验总结
情感分析是一项非常重要的工作,无论是对商品满意度,电影满意度,政府满意度或者是群众情绪导向等多个领域,情感分析都是饰演着重要的角色,本实验通过大规模分布式爬虫对数据进行采集,获得到了目标数据,然后进行了数据处理,通过word2vec模型建立出了词向量和索引,在通过LSTM算法,进行了模型训练,根据最终的结果可以看到,整个实验效果还不错的,整体趋势是在朝着准确率逐渐升高,损失逐渐降低的趋势发展,算是完成了本次试验的基本目标。但是本实验也有一些不足,通过优化意见部分,已经详细列出。
额外说明
- 本实验主要采用了Scrapy-redis构建了分布式爬虫系统,采用了Tensorflow构建了LSTM模型,采用了gensim构建了word2vec词向量等
- 本实验有任何问题可以与我取得联系:service@52exe.cn
运行图
- 爬虫爬区结果总览(由于时间有限,并没有爬过多数据)

- 爬虫爬取结果详情(部分)
- 清洗之后的语料库

- 分词之后的语料库
- 样本中的句子长度分布图
- loss与accurate图
- 运行结果截图(部分)







完整源码下载:https://download.csdn.net/download/FL1768317420/89330379
















 5707
5707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











