






一、包含的内容
1. 技术层面
1.1 智能数字内容孪生:图像超分、语音转字幕、文字转语音等。
1.2 智能数字内容编辑:视频场景剪辑、虚拟试衣、人声分离等。
1.3 智能数字内容生成:图像生成(AI绘画)、文本生成(AI写作、ChatBot)、视频生成、多模态生成等。
2. 生成内容层面
2.1 文本生成:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon等。
2.2 图像生成:EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。
2.3 音频生成:DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。
2.4 视频生成:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen video等。
2.5 多模态生成:DALL-E、MidJourney、Stable Diffusion等。
二、基础模型
1. VAE
2. GAN
3. Diffusion Model
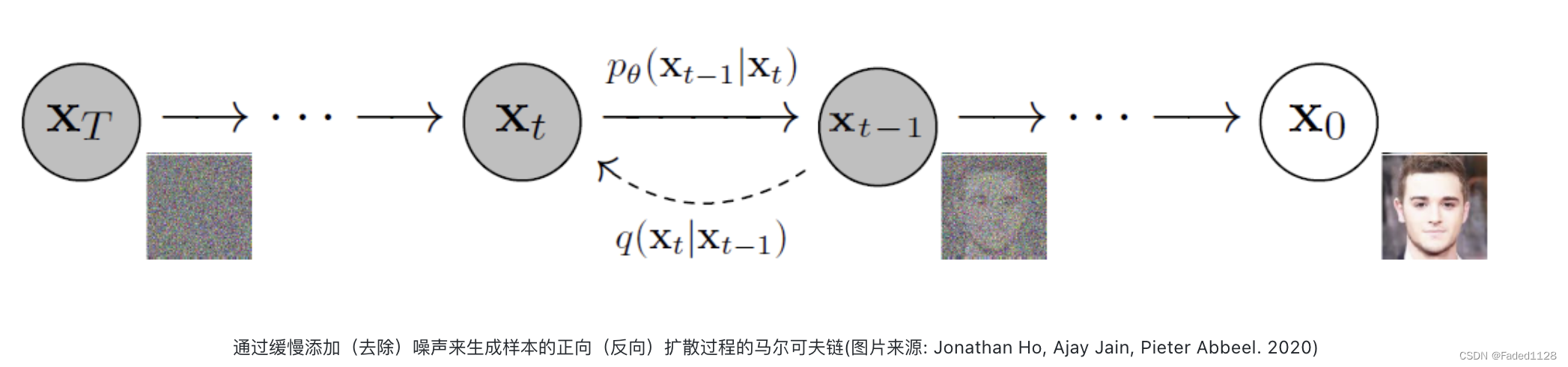
包含两个过程:
3.1 正向扩散:
通过逐渐引入噪声来破坏图像,直到图像变成完全随机的噪声。
3.2 反向扩散:
使用一系列马尔可夫链逐步去除预测噪声,从高斯噪声中恢复数据。
去除噪声:从时间帧t向时间帧t-1的变换
1)输入t时刻的图像(有噪声)
2)用U-Net 预测总噪声量
3)t 的图像减去该噪声
4. DALL-E 2
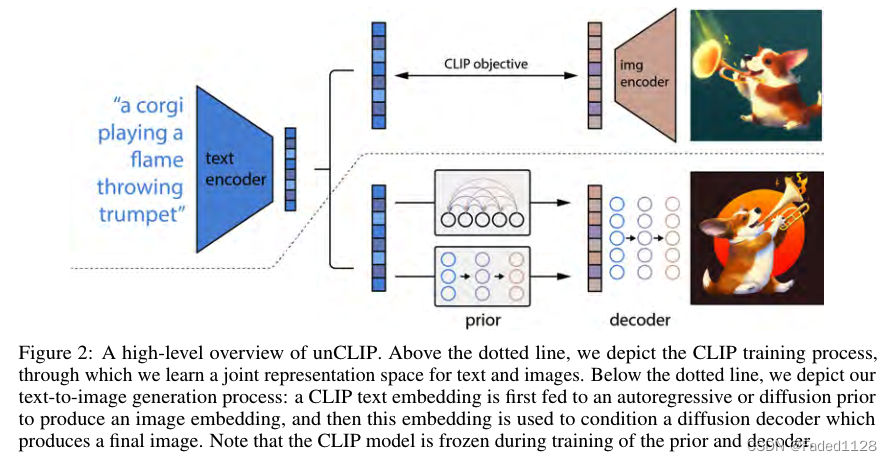
包含三个板块:CLIP、Prior、Img-decoder
4.1 Img-decoder
基于img embedding以及caption(text) embedding生成图像
1) diffusion model生成img:
2)为了生成高分辨率图像,训练了两个diffusion unsample model :一个是64*64 --> 256*256
(用高斯模糊),一个是进一步 --> 1024*1024(BSR退化)。在训练过程中稍微损坏图像来提高鲁棒性。
4.2 Prior
将text embedding转化为img embedding。有两种 Prior
4.2.1 AR prior
4.2.2 Diffusion prior
训练一个decoder-only的Transformer。通过casual attention mask按序操作:
- 标记化的文本/标题。
- 这些标记的 CLIP 文本编码。
- 扩散时间步长的编码。
- 带噪声的图像通过 CLIP 图像编码器。
- 最终编码,其来自 Transformer 的输出用于预测无噪声 CLIP 图像编码。
train的一些细节:
- Classifier-Free Guidance
- 为了提高样本质量,在 10% 的情况下使用无分类器指导随机进行采样,并删除文本调节信息。
Classifier-Guidance(事后修改):复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以控制生成。
Classifier-Free(事前训练):
- 双样本生成
- 为了提高采样期间的质量,使用先验生成两个图像嵌入,并选择与文本嵌入具有较高点积的图像嵌入。目前还不清楚为什么作者在这里使用点积而不是余弦相似度。
- 为什么我们需要先验?
- 作者指出,对于字幕到图像模型来说,训练这样的先验并不是绝对必要的。一种选择是仅以标题本身为条件。这将简单地产生模型 GLIDE,作者在论文中对两者进行了彻底的分析比较。另一种选择是将 CLIP 文本嵌入输入解码器,而不是使用之前的内容生成 CLIP 图像嵌入,然后使用它。作者通过实验发现,前者产生了合理的结果,尽管结果不如后者。最终,使用先验提高了图像多样性。
4.3 流程
- 首先,CLIP 文本编码器将图像描述映射到表示空间中。
- 然后扩散先验从CLIP文本编码映射到相应的CLIP图像编码。
- 最后,修改后的 GLIDE 生成模型通过反向扩散从表示空间映射到图像空间,生成在输入标题中传达语义信息的许多可能图像之一。
5. Imagen
6. Stable Diffusion
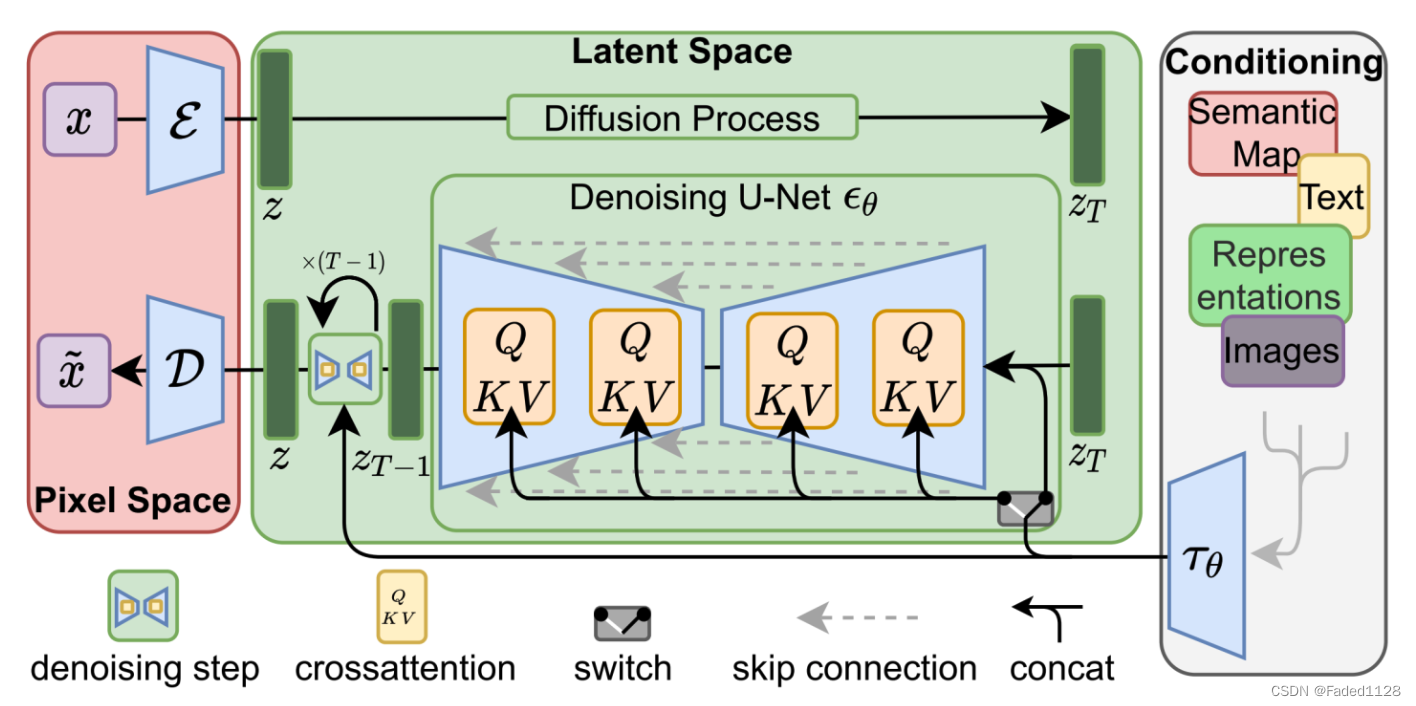
基于Latent Diffusion Model,数据在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转:
- 图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
- 对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
- 通过 CLIP 文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
- 基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
- 图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
7. ViT















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









