






Shardingsphere, Shardingsphere-jdbc, Shardingsphere-proxy, 数据库主从, 读写分离, 垂直分片, 水平分片
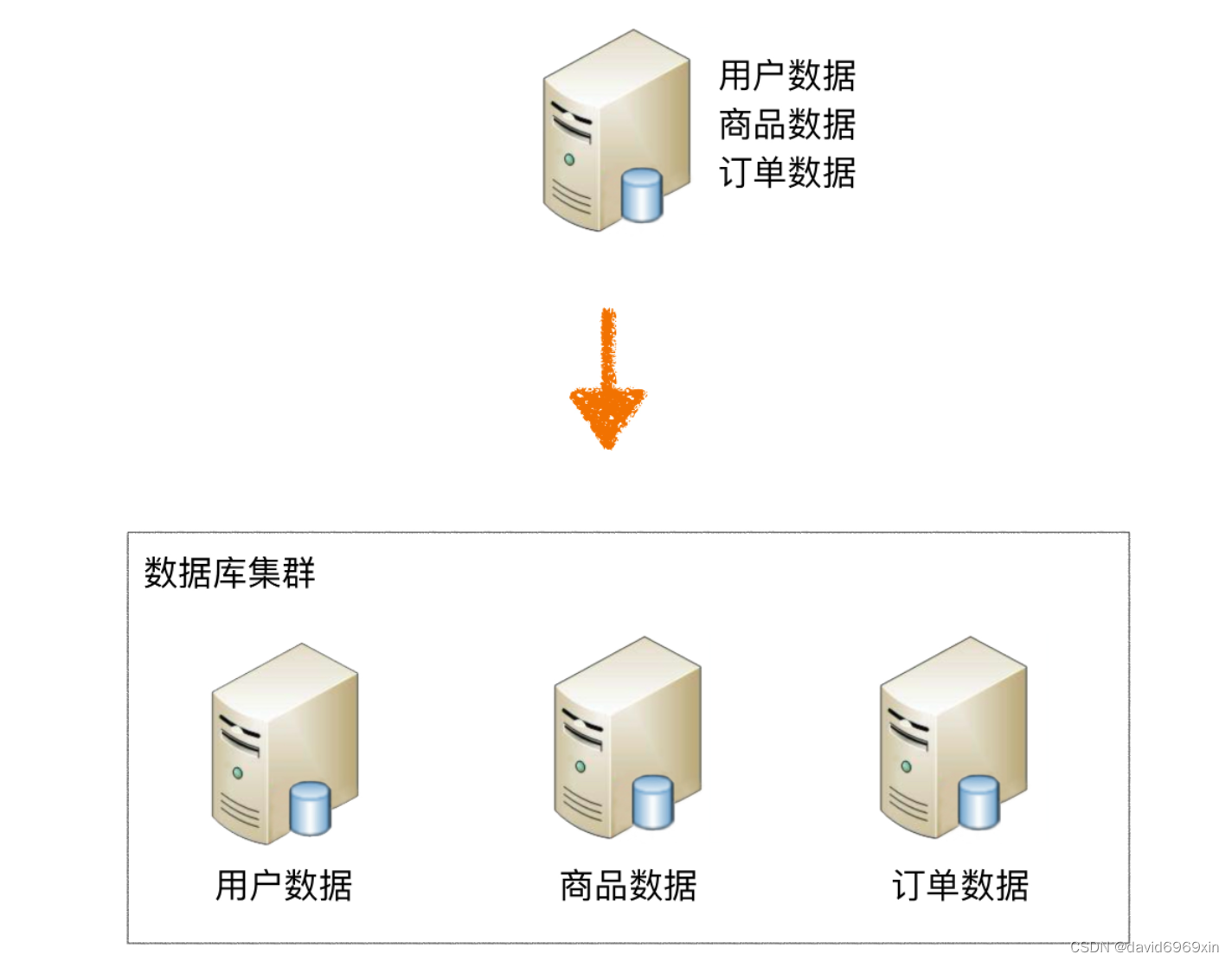
互联网业务兴起之后,海量用户加上海量数据的特点,单个数据库服务器已经难以满足业务需要,必须考虑数据库集群的方式来提升性能。高性能数据库集群的第一种方式是"读写分离",第二种方式是 “数据库分片”
示例代码地址: https://gitee.com/sunnyfe/shardingsphere.git
文章目录
第一章 高性能架构模式
1、读写分离架构
读写分离原理:读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是其基本架构图:

读写分离的基本实现:
主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。- 读写分离是
根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。 - 通过
一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 - 使用
多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
读写分离的问题:
读写分离分散了数据库读写操作的压力,但没有分散存储压力,为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
2、数据库分片架构
数据分片:将存放在单一数据库中的数据分散地存放至多个数据库或表中,以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行
分库和分表。数据分片的拆分方式又分为垂直分片和水平分片。
2.1 垂直分片
2.1.1 垂直分库
按照业务拆分的方式称为垂直分片,又称为纵向拆分`,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库,基本架构如图:
垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。`如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
2.1.2 垂直分表
垂直分表适合将表中某些不常用的列,或者是占了大量空间的列拆分出去。
假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升
2.2 水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示:

水平分表:单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,可以不拆分到多台数据库服务器,毕竟业务分库也会引入很多复杂性;水平分库:如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就需要将多个表分散在不同的数据库服务器中。

阿里巴巴Java开发手册:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
3、实现方式
读写分离和数据分片具体的实现方式一般有两种: 程序代码封装和中间件封装。
3.1 程序代码封装
程序代码封装指在代码中抽象一个数据访问层(或中间层封装),实现读写操作分离和数据库服务器连接的管理,其基本架构(读写分离为例)如图:

3.2 中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。对于业务服务器来说,访问中间件和访问数据库没有区别,在业务服务器看来,中间件就是一个数据库服务器。其基本架构(读写分离为例)如图:

3.3 常用解决方案
- Apache ShardingSphere(程序级别和中间件级别)
- MyCat(数据库中间件)
第二章 ShardingSphere
1、简介
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
2、ShardingSphere-JDBC
程序代码封装:定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。

3、ShardingSphere-Proxy
中间件封装:定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。

第三章 MySQL主从同步
1、MySQL主从同步原理
原理: slave会读取master的binlog进行数据同步
- master将数据改变记录到
二进制日志(binary log)中。 - 当slave上执行
start slave命令之后,slave会创建一个IO 线程用来连接master,请求master中的binlog。 - 当slave连接master时,master会创建一个
log dump 线程,用于发送 binlog 的内容。在读取 binlog 的内容的操作中,会对主节点上的 binlog 加锁,当读取完成并发送给从服务器后解锁。 - IO 线程接收主节点 binlog dump 进程发来的更新之后,保存到
中继日志(relay log)中。 - slave的
SQL线程,读取relay log日志,并解析成具体操作,从而实现主从操作一致,最终数据一致。

2、一主多从配置
服务器规划:使用docker方式创建,主从服务器IP一致,端口号不一致
- 主服务器:容器名
master1,端口3306 - 从服务器:容器名
master2,端口3307 - 从服务器:容器名
slave,端口3308

2.1 准备主从数据库
- 在docker中创建并启动MySQL服务器, 3台, 两台互为主从, 一台从库
主备 master1
docker run -d \
--restart=always\
--name master1 \
-v /data/docker/master/cnf:/etc/mysql \
-v /data/docker/master/data:/var/lib/mysql \
-v /data/docker/master/log:/var/log \
-v /data/docker/master/mysql-files:/var/lib/mysql-files \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=admin@123 \
mysql:8.0
主备 1master2
备1
docker run -d \
--restart=always\
--name master1 \
-v /data/docker/master2/cnf:/etc/mysql \
-v /data/docker/master2/data:/var/lib/mysql \
-v /data/docker/master2/log:/var/log \
-v /data/docker/master2/mysql-files:/var/lib/mysql-files \
-p 3307:3306 \
-e MYSQL_ROOT_PASSWORD=admin@123 \
mysql:8.0
备
docker run -d \
--restart=always\
--name master1 \
-v /data/docker/slave/cnf:/etc/mysql \
-v /data/docker/slave/data:/var/lib/mysql \
-v /data/docker/slave/log:/var/log \
-v /data/docker/slave/mysql-files:/var/lib/mysql-files \
-p 3308:3306 \
-e MYSQL_ROOT_PASSWORD=admin@123 \
mysql:8.0
- 创建MySQL主服务器配置文件
默认情况下MySQL的binlog日志是自动开启的,可以通过如下配置定义一些可选配置:
vim /data/docker/master1/cnf/my.cnf
vim /data/docker/master2/cnf/my.cnf
vim /data/docker/slave/cnf/my.cnf
- 配置如下内容, 每台server-id不一样, 其他配置一样
[mysqld]
# 必须唯一
server-id = 100
#开启及设置二进制日志文件名称
log_bin = mysql-bin
binlog_format = MIXED
sync_binlog = 1
#二进制日志自动删除/过期的天数。默认值为0,表示不自动删除。
expire_logs_days =7
#binlog_cache_size = 128m
#max_binlog_cache_size = 512m
#max_binlog_size = 256M
#要同步的数据库
#binlog-do-db = test
#不需要同步的数据库
binlog-ignore-db = mysql
binlog_ignore_db = information_schema
binlog_ignore_db = performation_schema
binlog_ignore_db = sys
relay_log=mysql-relay-bin
log_slave_updates=1
- 进入master1, master2两台互为主从的数据库, 创建slave用户
# 创建slave用户
CREATE USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY 'slave@123456';
# 分配权限
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
# 刷新权限
flush privileges;
- 分别查询master状态并技术file和position

- 分别完成在master1中配置同步master2配置, 在master2中配置同步master1配置
# 进入容器内部
docker exec -it 容器id /bin/bash
# 登录mysql
mysql -uroot -padmin@123
# 设置连接
# MASTER_HOST 填写主库实际host地址
# MASTER_LOG_FILE='mysql-bin.000001', 填写上一步查询出来的二进制文件的名称
# MASTER_LOG_POS=828; 填写上一步查询出来的二进制文件的位置
CHANGE MASTER TO
MASTER_HOST='172.16.201.171',
MASTER_USER='slave',
MASTER_PASSWORD='slave@123456',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=1031;
start slave;
# 查看slave状态
show slave status\G;
- 重启MySQL容器
docker restart master1
docker restart master2 - 设置slave为master1从库
binlog格式说明:
- binlog_format=STATEMENT:日志记录的是主机数据库的
写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。 - binlog_format=ROW(默认):日志记录的是主机数据库的
写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。 - binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT,但是无法识别系统变量
binlog-ignore-db和binlog-do-db的优先级问题:

step3:使用命令行登录MySQL主服务器:
# 进入容器内部
docker exec -it 容器id /bin/bash
第四章 ShardingSphere-JDBC
1、读写分离
1.1 添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.sunnyfe</groupId>
<artifactId>shardingsphere-read-write-separation</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingsphere-read-write-separation</name>
<description>shardingsphere-read-write-separation</description>
<properties>
<java.version>1.8</java.version>
<shardingsphere.version>5.1.2</shardingsphere.version>
<mybatis-plus.version>3.5.2</mybatis-plus.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1.2 创建实体类
@TableName("t_user")
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
1.3 创建Mapper
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
1.4 配置读写分离(application.properties)
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第1个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://172.16.201.69:3306/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=admin@123
# 配置第2个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://172.16.201.170:3307/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=admin@123
# 配置第3个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://172.16.201.171:3307/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=admin@123
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称 更换负载均衡算法, 更换算法名 42行, 44行, 45行, 46行四种
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
#
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1.0
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2.0
# 打印SQl
spring.shardingsphere.props.sql-show=true
1.5 测试
package com.sunnyfe.shardingsphere.readwriteseparation;
import com.sunnyfe.shardingsphere.readwriteseparation.entity.User;
import com.sunnyfe.shardingsphere.readwriteseparation.mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class ShardingsphereReadWriteSeparationApplicationTests {
@Autowired
private UserMapper userMapper;
/**
* 写入数据的测试
* 日志打印写入主库
*/
@Test
public void testInsert(){
User user = new User();
user.setUname("张三");
userMapper.insert(user);
}
/**
* 读数据测试
* 轮巡两个从库
*/
@Test
public void testSelectAll(){
List<User> usersOne = userMapper.selectList(null);
//执行第二次测试负载均衡
List<User> usersTwo = userMapper.selectList(null);
}
}
为了保证主从库间的事务一致性,避免跨服务的分布式事务,ShardingSphere-JDBC的
主从模型中,事务中的数据读写均用主库。
- 不添加@Transactional:insert对主库操作,select对从库操作
- 添加@Transactional:则insert和select均对主库操作
- 注意:在JUnit环境下的@Transactional注解,默认情况下就会对事务进行回滚(即使在没加注解@Rollback,也会对事务回滚)
2、垂直分片
服务器规划:使用docker方式创建如下容器:
- 服务器:容器名
server-user,端口3301 - 服务器:容器名
server-order,端口3302
2.1 创建两个数据库容器user, order
user
CREATE DATABASE db_user;
USE db_user;
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30),
PRIMARY KEY (id)
);
order
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order (
id BIGINT AUTO_INCREMENT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
2.3 程序实现
- 创建Order实体类
package com.sunnyfe.shardingsphereverticalfragmentation.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
@TableName("t_order")
@Data
public class Order {
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal amount;
}
- 创建Mapper:
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
step3:配置垂直分片:
# 应用名称
spring.application.name=shardingsphere-vertical-fragmentation
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order
# 配置第 1 个数据源
spring.shardingsphere.datasource.order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.order.jdbc-url=jdbc:mysql://172.16.201.170:3301/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.order.username=root
spring.shardingsphere.datasource.order.password=admin@123
# 配置第 2 个数据源 同一个数据库连接 不同库
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://172.16.201.170:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=admin@123
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order.t_order
- 测试垂直分片
package com.sunnyfe.shardingsphereverticalfragmentation;
import com.sunnyfe.shardingsphereverticalfragmentation.entity.Order;
import com.sunnyfe.shardingsphereverticalfragmentation.entity.User;
import com.sunnyfe.shardingsphereverticalfragmentation.mapper.OrderMapper;
import com.sunnyfe.shardingsphereverticalfragmentation.mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.math.BigDecimal;
@SpringBootTest
class ShardingsphereVerticalFragmentationApplicationTests {
@Autowired
private OrderMapper orderMapper;
@Autowired
private UserMapper userMapper;
/**
* 垂直分片:插入数据, 插入到不同数据库中
*/
@Test
public void testInsertOrderAndUser(){
User user = new User();
user.setUname("张三");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("ORDER01");
order.setUserId(user.getId());
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
/**
* 垂直分片:查询数据, 日志显示从不同数据源中读取
*/
@Test
public void testSelectFromOrderAndUser(){
User user = userMapper.selectById(1L);
Order order = orderMapper.selectById(1L);
}
}
3、水平分片, 多表关联, 绑定表, 广播表
服务器规划:
- 保留上一步创建的两个容器
- 在order容器中,创建两个数据库, db_order0, db_order1
- 在order
3.3 基本水平分片配置
- 基本配置
#========================基本配置
# 应用名称
spring.application.name=shardingsphere-horizontal-fragmentation
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#========================数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=user,order0,order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.user.jdbc-url=jdbc:mysql://172.16.201.170:3302/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.user.username=root
spring.shardingsphere.datasource.user.password=admin@123
# 配置第 2 个数据源
spring.shardingsphere.datasource.order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.order0.jdbc-url=jdbc:mysql://172.16.201.170:3301/db_order0?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.order0.username=root
spring.shardingsphere.datasource.order0.password=admin@123
# 配置第 3 个数据源
spring.shardingsphere.datasource.order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.order1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.order1.jdbc-url=jdbc:mysql://172.16.201.170:3301/db_order1?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.order1.username=root
spring.shardingsphere.datasource.order1.password=admin@123
#========================标准分片表配置(数据节点配置)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=user.t_user
# 使用行表达式进行配置
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=order$->{0..1}.t_order$->{0..1}
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片算法配置
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=order$->{user_id % 2}
#------------------------分表策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 哈希取模分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#------------------------标准分片表配置(数据节点配置)
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=order$->{0..1}.t_order_item$->{0..1}
#------------------------分库策略
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_id
# 分片算法名称 用order表的算法
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片算法配置
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_no
# 分片算法名称 用order表的算法
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分布式序列策略配置
# 分布式序列列名称 实体类id类型设置 @TableId(type = IdType.AUTO)
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
#------------------------绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
# 数据节点可不配置,默认情况下,向所有数据源广播
spring.shardingsphere.rules.sharding.tables.t_dict.actual-data-nodes=user.t_dict,order$->{0..1}.t_dict
# 广播表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=t_dict
3.4 测试水平分片
package com.example.shardingspherehorizontalfragmentation;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.example.shardingspherehorizontalfragmentation.entity.Dict;
import com.example.shardingspherehorizontalfragmentation.entity.Order;
import com.example.shardingspherehorizontalfragmentation.entity.OrderItem;
import com.example.shardingspherehorizontalfragmentation.mapper.DictMapper;
import com.example.shardingspherehorizontalfragmentation.mapper.OrderItemMapper;
import com.example.shardingspherehorizontalfragmentation.mapper.OrderMapper;
import com.example.shardingspherehorizontalfragmentation.vo.OrderVo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.math.BigDecimal;
import java.util.List;
@SpringBootTest
class ShardingsphereHorizontalFragmentationApplicationTests {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderItemMapper orderItemMapper;
@Autowired
private DictMapper dictMapper;
/**
* 水平分片:分表插入数据测试
*/
@Test
public void testInsertOrderTableStrategy(){
for (long i = 1; i < 5; i++) {
Order order = new Order();
order.setOrderNo("Sharding" + i);
order.setUserId(1L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
for (long i = 5; i < 9; i++) {
Order order = new Order();
order.setOrderNo("Sharding" + i);
order.setUserId(2L);
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
}
/**
* 水平分片:查询所有记录
* 查询了两个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectAll(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
/**
* 水平分片:根据user_id查询记录
* 查询了一个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectByUserId(){
QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>();
orderQueryWrapper.eq("user_id", 1L);
List<Order> orders = orderMapper.selectList(orderQueryWrapper);
orders.forEach(System.out::println);
}
/**
* 测试关联表插入
*/
@Test
public void testInsertOrderAndOrderItem(){
for (long i = 1; i < 3; i++) {
Order order = new Order();
order.setOrderNo("Sharding" + i);
order.setUserId(1L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("Sharding" + i);
orderItem.setUserId(1L);
orderItem.setPrice(new BigDecimal(10));
orderItem.setCount(2);
orderItemMapper.insert(orderItem);
}
}
for (long i = 5; i < 7; i++) {
Order order = new Order();
order.setOrderNo("Sharding" + i);
order.setUserId(2L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("Sharding" + i);
orderItem.setUserId(2L);
orderItem.setPrice(new BigDecimal(1));
orderItem.setCount(3);
orderItemMapper.insert(orderItem);
}
}
}
/**
* 测试关联表查询
* 配置关联表之后重新测试
*/
@Test
public void testGetOrderAmount(){
List<OrderVo> orderAmountList = orderMapper.getOrderAmount();
orderAmountList.forEach(System.out::println);
}
/**
* 广播表:每个服务器中的t_dict同时添加了新数据
*/
@Test
public void testBroadcast(){
Dict dict = new Dict();
dict.setDictType("type1");
dictMapper.insert(dict);
}
/**
* 查询操作,只从一个节点获取数据
* 随机负载均衡规则
*/
@Test
public void testSelectBroadcast(){
Dict dict = new Dict();
dict.setDictType("1");
dictMapper.insert(dict);
List<Dict> dicts0 = dictMapper.selectList(null);
List<Dict> dicts1 = dictMapper.selectList(null);
List<Dict> dicts2 = dictMapper.selectList(null);
}
}
3.5 分布式序列算法
雪花算法: https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/key-generator/
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。
这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
基于MyBatisPlus的id策略:将Order类的id设置成如下形式:
@TableId(type = IdType.ASSIGN_ID)
private Long id;
设置t_order_item的主键(key)id的生成方式为alg_snowflake算法, alg_snowflake算法的实现类型为SNOWFLAKE
#------------------------分布式序列策略配置
# 分布式序列列名称 实体类id类型设置 @TableId(type = IdType.AUTO)
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
此时,需要将实体类中的id策略修改成以下形式:
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
@TableId(type = IdType.AUTO)
第五章 ShardingSphere-Proxy
1、安装
目前 ShardingSphere-Proxy 提供了 3 种安装方式:
本文使用Docker安装做为案例:
1.1 启动Docker容器
docker run -d \
-v /data/docker/shardingsphere/proxy-a/conf:/opt/shardingsphere-proxy/conf \
-v /data/docker/shardingsphere/proxy-a/ext-lib:/opt/shardingsphere-proxy/ext-lib \
-v /data/docker/shardingsphere/proxy-a/logs:/opt/sharding-proxy/logs \
-e PORT=3308 \
-e ES_JAVA_OPTS="-Xmx256m -Xms256m -Xmn128m" \
-p 13308:3308 \
--name shardingsphere-proxy \
apache/shardingsphere-proxy:5.1.2
1.2 可以随便创建一个apache/shardingsphere-proxy:5.1.2进入容器复制配置文件到挂载目录
# 创建一个临时容器
docker run -d --name shardingsphere-proxy-temp apache/shardingsphere-proxy:5.1.2
# 复制容器内的的配置文件目录到挂载的配置文件目录
docker cp shardingsphere-proxy-temp:/opt/shardingsphere-proxy/conf/ /data/docker/shardingsphere/shardingsphere-proxy
docker stop shardingsphere-proxy-temp
docker rm shardingsphere-proxy-temp
1.3 在maven仓库中, 将mysql驱动mysql-connect-java-version.jar 放到/data/docker/shardingsphere/proxy-a/ext-lib
1.4 修改server.yaml
rules:
- !AUTHORITY
users:
# 登录shardingsphere用户名:密码
- root@%:root
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
sql-show: true
1.5 重启shardingsphere-proxy
docker restart shardingsphere-proxy
1.6 登录shardingsphere-proxy
# shardingsphere的host, 端口, 用户(root), 密码(root)
mysql -h 172.16.201.170 -P13308 -uroot -p
2、读写分离
2.1 修改config-readwrite-splitting.yaml
# 逻辑表明, 映射url中配置的表名, 建议改成同名
# databaseName: readwrite_splitting_db 默认名
databaseName: db_user
dataSources:
write_ds:
url: jdbc:mysql://172.16.201.69:3306/db_user?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: admin@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_0:
url: jdbc:mysql://172.16.201.170:3307/db_user?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: admin@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_1:
url: jdbc:mysql://172.16.201.171:3307/db_user?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: admin@123
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
type: Static
props:
write-data-source-name: write_ds
read-data-source-names: read_ds_0,read_ds_1
loadBalancerName: random
loadBalancers:
random:
2.2 重启shardingsphere-proxy生效
3 、 垂直分片
3.1 修改配置config-sharding.yaml
databaseName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
scalingName: default_scaling
scaling:
default_scaling:
input:
workerThread: 40
batchSize: 1000
output:
workerThread: 40
batchSize: 1000
streamChannel:
type: MEMORY
props:
block-queue-size: 10000
completionDetector:
type: IDLE
props:
incremental-task-idle-seconds-threshold: 1800
dataConsistencyChecker:
type: DATA_MATCH
props:
chunk-size: 1000
4、 水平分片
修改config-sharding.yaml配置文件
schemaName: sharding_db
dataSources:
ds_user:
url: jdbc:mysql://192.168.26.134:3301/db_user?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_order0:
url: jdbc:mysql://192.168.26.134:3310/db_order?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_order1:
url: jdbc:mysql://192.168.26.134:3311/db_order?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: ds_user.t_user
t_order:
actualDataNodes: ds_order${0..1}.t_order${0..1}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: alg_mod
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: alg_hash_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_order${0..1}.t_order_item${0..1}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: alg_mod
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: alg_hash_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_dict
shardingAlgorithms:
alg_inline_userid:
type: INLINE
props:
algorithm-expression: server-order$->{user_id % 2}
alg_mod:
type: MOD
props:
sharding-count: 2
alg_hash_mod:
type: HASH_MOD
props:
sharding-count: 2
keyGenerators:
snowflake:
type: SNOWFLAKE
5、应用
- 把shardingsphere-proxy当做数据库一样使用
- shardingsphere-jdbc是代码配置层面, proxy是程序代理层面
#mysql数据库连接(proxy)
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://172.16.201.170:13308/readwrite_splitting_db?serverTimezone=GMT%2B8&useSSL=false
spring.datasource.username=root
spring.datasource.password=root

















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









