







引入
情景:假设我们想要用一个 指标criterion 来衡量一个班学生的身高水平,现在想要选择这样一个具有代表性的指标,如何选取

方法一:假设指标 c (criterion)可代表班级身高水平,那么指标与实际的误差可表示为
为了保证所选择的指标具有代表性,误差需要尽可能小,我们可以对 f(x) 进行求导判断,但是会发现,求导后的数据与 c 无关,误差完全取决于样本数据,这不是我们想要的。
方法二:在方法一的基础上,改变误差的表达式如下,它仍然表示指标与实际值的差距,只不过平方运算将原有差距进一步放大
我们用之前同样的方法,对 f(x) 进行求导,为了找到使误差最小时,指标 c 的表达式,我们令导数为零,可得结果如下
这眼熟的公式便是我们处理数据时常用的 平均值average,也称为 期望expectation。经过上述的推理过程,我们之所以常用它来代表一个数据集的属性,也是因为它与实际数据的误差最小,而这个误差表达式 f(x) 也是我们常用的 方差variance
一维递推最小二乘 one dimension RLS
有了上述的原理之后,我们将它的求取衍生出算法,提高它的实时处理能力。用求均值的方式,写出 t 时刻和 t+1 时刻的估计值
这样,对于实时收集的数据,不用保存所有数据进行计算,只需要根据上一次计算的 估计值estimation 和收集到的当前数据,便可以计算出新的估计值,可以有效的节省内存,提高运算效率。这种根据上次计算结果进行实时更新迭代的算法,称为 递推最小二乘Recursive Least Squares algorithm。中括号内的表达式称为 新息innovation
二维最小二乘
现在,假设我们有一堆数据,是 n 个点的坐标数据(x和y),我们希望通过这些数据,拟合出一条直线,能够尽可能的代表这些点的分布 (即散点图求拟合直线)。用最开始的方法,我们先假定一条最具代表性的直线 y=kx+b,那么现在我们需要做的,就是用最小二乘的方式,求得这条直线 (即两个参数 k 和 b)。
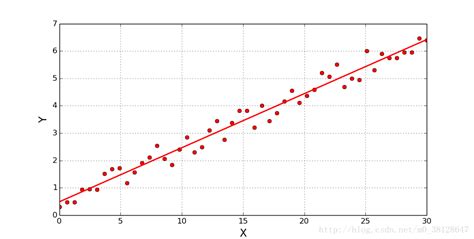
类似于方差的定义,我们自定义函数 J 评判误差 (点到拟合线的距离),并希望它能达到最小 (同样通过求导找极值点)
我们将表达式用矩阵表示,并取掉复杂的求和运算
很显然,H代表横坐标矩阵,Y代表纵坐标矩阵,所以,θ的估计值仅和坐标有关。所以,我们可以通过已有的坐标数据,求出相应的 k 和 b 值
最小二乘估计
针对上述 H 与 Y 的关系,将 H 看作输入,Y 看作输出,则系数矩阵 θ 表示了输入输出之间的关系。我们将这种关系的估算拓展到更高的维度,考虑 多输入多输出(BIBO) 系统,且考虑系统在测得输入输出值时的误差 v (白噪声)
为了计算方便,将上述表达式简化为矩阵形式
接下来,用之前同样的方式写出 误差标准函数(error criterion function)如下
由于此处是矩阵运算,所以,在求导找极值点之前,先引入两个矩阵导数公式:
利用这两个求导公式,上述标准函数 J 对 Θ 求导可得
为了找到最合适的 Θ,需要误差最小,此时 Θ 取极值点
可以发现,此处的结论,与二维算法非常相似,但是此处公式更为通用,阐释了 n 维输入与 m 维输出时,对系统参数的 最小二乘估计(Least Squares Estimation)
LSE的统计特性
期望
根据白噪声的特点,我们设白噪声的统计特性如下
那么,LSE满足如下关系
由于白噪声的期望为零,因此LSE的期望为
可见,LSE属于无偏估计
方差
令 ,不难得其期望为零,其方差为
误差标准函数
对于误差标准函数 J 满足
上述利用矩阵 迹(trace) 的规则进行变换,又
在这里引入 投影矩阵(idempotent matrix) 的概念,即一个矩阵转置后仍然是它本身,则该矩阵称为投影矩阵。不难得,此处的 Q 就是一个投影矩阵,则














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









