







二.爬虫基础知识
1爬虫简介
网络爬虫,是按照一定的规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取政策。
爬虫本质:模拟浏览器打开网页,获取网页中我们想要的那部分数据。
在代码中第一行加入
#coding = utf-8或者#—*— coding:utf-8 —*—这样可以在代码中包含中文PYTHON 文件中可以加入main函数用于测试程序
if name == “main”:
2 基本流程
-
准备工作
通过浏览器查看分析目标网页,学习编程技术规范。
-
获取数据
通过HTML库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容
-
解析内容
得到内容可能是HTML,JSON等格式,可以使用页面解析库,正则表达式等进行解析,
-
保存数据
保存数据形式多样,可以保存为文本,也可以保存为数据库,或者保存为特定格式的文件。
2.1准备工作
2.1.1分析页面
借助charome开发工具来分析页面(F12),在Elements下找到需要的数据位置。
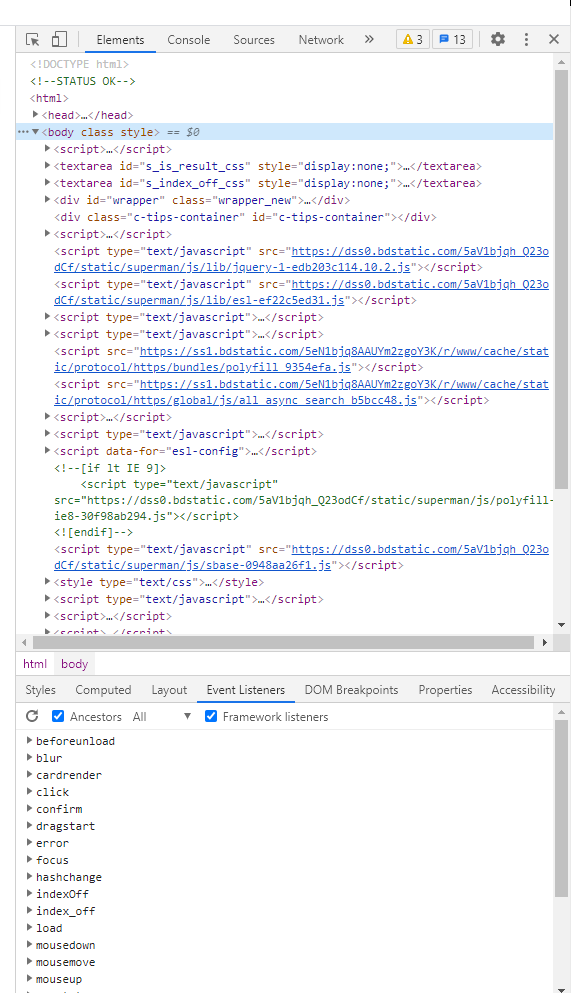
通过借助charome开发工具来分析页面(F12),在Network下要发送的数据。
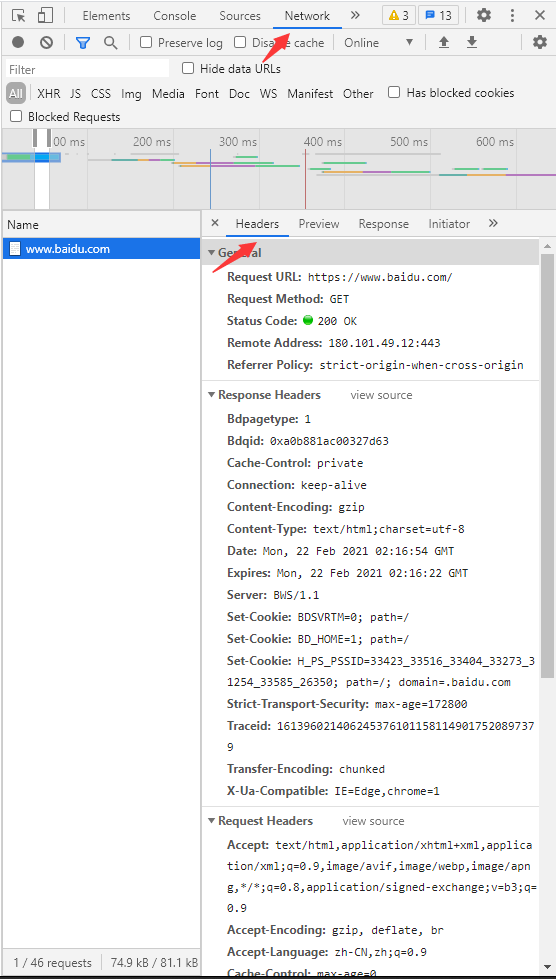
2.1.2 编码规范
在代码中第一行加入
#coding = utf-8或者#—*— coding:utf-8 —*—这样可以在代码中包含中文。PYTHON 文件中可以加入main函数用于测试程序。
if __name__ == “__main__”:
#添加注释进行代码说明。
2.1.3 模块引入
模块(module):用来从逻辑上组织的python 代码(变量,函数,类),本质上就是py文件,提高代码的可维护性。python使用import来导入模块。
# 导入指定模块
from 路径 import 模块名
#使用模块中的函数
模块名.函数名()
常用包:
from bs4 import beaufulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #指定url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
2.2获取数据
python 一般用
urllib库来获取数据
2.2.1 get请求
#引入urllib库中的request包
import urllib.request
#使用变量接受返回值 变量名 = urllib.request.urlopen("网址",timeout = 设定时间)
response = urllib.request.urlopen("http://www.baidu.com",timeout = 设定时间) #单位秒,超时报urllib.error.URLError错误
#打印网址源码 read()读取内容--decode('utf-8')解码
print(response.read().decode('utf-8'))
2.2.2 post请求
- 简单的请求方式
#引入urllib库中的request,parse包
import urllib.request,urllib.parse
#封装一个二进制数据 二进制变量名 = bytes(urllib.parse.urlencode({存储设定数据的字典}),encoding="utf-8")
data = bytes(urllib.parse.urlencoding({"键":"值"},{"键":"值"}),encoding="utf-8")
#使用变量接受返回值 变量名 = urllib.request.urlopen("网址",data = 二进制变量名)
response = urllib.request.urlopen("http://www.baidu.com",data = data)
#打印网址源码 read()读取内容--decode('utf-8')解码
print(response.read().decode('utf-8'))
- 稍微伪装的请求方式
#引入urllib库中的request,parse包
import urllib.request,urllib.parse
#封装一个二进制数据 二进制变量名 = bytes(urllib.parse.urlencode({存储设定数据的字典}),encoding="utf-8")
data = bytes(urllib.parse.urlencoding({"键":"值"},{"键":"值"}),encoding="utf-8")
#从网页上找到Request Header找到要使用的信息,以字典的方式封装
headers = {"User-Agent":"信息":"":""}
#使用urllib.request.Request()方法封装
封装变量 = urllib.request.Request(url="网址",data=data,headers=headers,mothon="POST")
#使用变量接受返回值 变量名 = urllib.request.urlopen(封装变量)
response = urllib.request.urlopen(req)
#打印网址源码 read()读取内容--decode('utf-8')解码
print(response.read().decode('utf-8'))
例子:
爬取bilibili排行榜源码:
import urllib.request,urllib.parse
try:
url="https://www.bilibili.com/v/popular/rank/all"
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"} #用户代理,告诉指定网址使用机器具体信息(伪装,告诉网站本机器可以接受什么水平的文件内容)
#封装二进制对象
data = bytes(urllib.parse.urlencode({"awsl":"awsl"}),encoding="utf-8") ##此句无实际效果
#封装url对象
re = urllib.request.Request(url=url,headers=header)
#获取网页源码
res = urllib.request.urlopen(re,timeout=1)
#打印源码
print(res.read().decode("utf-8"))
except urllib.error.URLError as e:
print("访问超时")
2.3解析数据
#打开指定文件
file = open("要打开文件的路径","打开模式")
#读取文件内容
html = file.read()
#解析文件 BeautifulSoup(解析内容,"解析类型")
bs = BeautifulSoup(html,"html.parser")
#获取标签内容 解析完变量.标签
print(bs.a)
1.获得需求内容的标签
1.bs4.element.Tag 类型
标签及其内容
默认拿到第一个
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#获得标签与内容 解析完变量.标签
print(pyte(bs.a) #bs4.element.Tag 类型
2.bs4.element.NavigableString 类型
标签内容(字符串)
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#获得内容 解析完变量.标签.string
print(pyte(bs.a.string) #bs4.element.NavigableString 类型
3.bs4.NeautifulSoup 类型
整个文档
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#获得整个文档内容
print(pyte(bs)) #bs4.NeautifulSoup 类型
4.bs4.element.Commeny 类型
注释类型
当解析标签中存在注释时
一个特殊的bs4.element.NavigableString,输出内容不包含注释符号
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#获得标签内容 !!!第一个a标签中存在注释
print(pyte(bs.a.string)) #bs4.element.Commeny 类型
1.bs4遍历文档树
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用方法获得特定内容
print(bs.a.方法)
| 方法 | 描述 | 备注 |
|---|---|---|
| .children | 子节点,子孙节点 | 迭代器 |
| .contents | 子节点,子孙节点 | 列表 |
| .descendants | 所有子孙结点 | 迭代器 |
| .parent | 直接父节点 | 列表 |
| .parents | 祖先节点 | 迭代器 |
| .next_sibling | 下一个兄弟节点 | 列表 |
| .next_siblings | 下面的兄弟节点 | 迭代器 |
| .previous_sibling | 上一个兄弟节点 | 列表 |
| .previous_siblings | 下面的兄弟节点 | 迭代器 |
| .next_element | 不分层次的前元素 | 列表 |
| .next_elements | 不分层次的前所有元素 | 迭代器 |
| .previous_element | 不分层次的后元素 | 列表 |
| .previous_elements | 不分层次的后所有元素 | 迭代器 |
2.文档的搜索
find_all
字符串过滤:会查找与字符串完全匹配标签的内容
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用 find_all("查询字符串")方法获得特定标签的内容
list = bs.find_all("查询字符串")
print(list)
参数过滤:查找含有指定参数的内容
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用 find_all(参数="")
list = bs.find_all(id="指定") #list = bs.find_all(class_="指定")
print(list)
文本过滤
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用 find_all(text="")
list = bs.find_all(text="指定文本") ##可以使用正则表达式 list = bs.find_all( text=re.compile("正则表达式") )
print(list)
limit参数
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用 find_all("查询字符串",limit=次数) 方法获得特定数量标签的内容
list = bs.find_all("查询字符串",limit=3)
print(list)
2.获得标签内的内容
正则表达式
使用正则表达式中,被比较的字符串前加 r ,不用担心转义字符
使用search()方法来匹配内容
#引入正则表达式的库
import re
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#使用 find_all("查询字符串")方法获得特定内容 re.compile("指定字符串")
list = bs.find_all(re.compile("指定字符"))
pat = re.compile(正则表达式)
m = pat.search(html)
#简写:
m = re.search("正则表达式","检验字符串") #查询是否存在,存在位置
使用findall来匹配内容
#引入正则表达式的库
import re
#re.fandall("正则表达式","检验的字符串")
print( re.fandall("正则表达式","检验的字符串") ) #每匹配成功输出一个列表元素
使用sub来替换内容
import re
#从第三个字符串中找到第一个字符串用第二个字符串替换
re.sub("正则表达式","替换元素","被替换掉字符串")
常用操作符:
| 操作符 | 说明 | 实列 |
|---|---|---|
| . | 表示任何一个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [abc] 表示a,b,c [a-z] 表示a到z的单个字符 |
| [^] | 非字符集,对单个字符给出排除范围 | [^abc] 表示非a非b非c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc* 表示 ab,abc,abcc,abccc |
| + | 前一个字符1次或者无限次扩展 | abc+ 表示abc,abcc,abccc |
| ? | 前一个字符0次或者1次扩展 | abc? 表示ab,abc |
| | | 左右表达式任意一个 | abc|cdf 表示abc或者cdf |
| {m} | 扩展前一个字符m次 | ab{2}c 表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c 表示abc,abbc |
| ^ | 匹配字符串开头 | ^abc 表示abc且在字符串开头 |
| $ | 匹配字符串结尾 | $abc 表示abc且在字符串结尾 |
| () | 分组标记,内部只能用|操作符 | (abc)表示abc (abc|def)表示abc,def |
| \d | 数字,等价[1-9] | |
| \w | 单词字符,等价[A-Za-z0-9_] | |
| \s |
主要函数:
| 函数 | 说明 | 备注 |
|---|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 | |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 | |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 | |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 | |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素都是match对象 | |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的字串,返回替换后的字符串 |
可选的标志修饰符:
| 修饰符 | 描述 | 备注 |
|---|---|---|
| re.l | 是匹配大小写不敏感 | |
| re.L | 做本地化识别匹配 | |
| re.M | 多行匹配,影响^和$ | |
| re.S | 使 . 匹配换行在内的所有字符 | |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b,\B | |
| re.X | 该标志通过给与你更灵活的格式以便你将正则表达式写的更易于理解。 |
css选择器
通过标签查找:
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找固定的标签
list = bs.select("a") #<a class="选定class" id="选定id"></a>
通过类名查找
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找固定类名的标签
list = bs.select(".选定class") #<a class="选定class" id="选定id"></a>
通过id来查找
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找固定id的标签
list = bs.select("#选定id") #<a class="选定class" id="选定id"></a>
通过属性来查找
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找固定属性的标签
list = bs.select("a[class='选定class']") #<a class="选定class" id="选定id"></a>
通过子标签查找
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找标签d的子父关系查找 # <head>
list = bs.select("head > title") # <title>查找内容</title> # </head>
通过兄弟标签查找
file = open("要打开文件的路径","打开模式")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
#查找固定属性的标签 # <muav></muav>
list = bs.select(".muav ~ .bri") # <bri>要查找内容<bri>
2.4保存数据
1.Excel 表存储数据
l利用python库将抽取的数据写入Excel表格
以utf-8编码创建一个excel表格 -> 创建一个sheet表 -> 往单元格写入内容 -> 保存表格
#引入模块
import xlwt
#以utf-8编码创建一个excel表格 表格变量 = xlwt.Workbook(decoding="utf-8")
workbook = xlwt.Workbook(decoding="utf-8")
#创建一个sheet表 工作表变量 = workbook.add_sheet('工作表名')
worksheet = workbook.add_sheet('sheet1',cell_overwrite_ok=True) ##是否可以覆盖内容
#往单元格写入内容 工作表变量.write(横坐标, 纵坐标, "要写入字符")
worksheet.write(0, 0, "存储字符")
#保存表格
workbook.save("xxxx.xls") 表格变量.save("表格名.xls")
2.数据库存储数据
利用python库将抽取的数据写入sqliee数据库
打开或者创建数据库 -> 获取游标 -> 执行sql语句 -> 提交数据库操作 -> 关闭数据库
# 引入模块
import sqlite3
#1.打开或者创建数据库,默认在当前目录下 数据库变量 = sqlite.connect("文件名")
conn = sqlite.connect("文件名")
#2.获取游标 游标变量 = 数据库变量.cursor()
c = conn.cursor()
#编写sql语句
sql = "sql语句"
#3.执行sql语句 游标变量.execute("sql语句")
c.execute(sql) #如果有返回值: cursor = c.execute(sql)
#4.提交数据库操作 数据库变量.commit()
conn.commit()
#5.关闭数据库 数据库变量.close
conn.close()
例子:
# -*- codeing = utf-8 -*-
#@Time: 2021/2/22 19:33
#@Name: 凡诚
#@File:bilibili
#@Software PyCharm
import urllib.request,urllib.parse
import re
from bs4 import BeautifulSoup
import xlwt
#爬取网页地址
url = "https://www.bilibili.com/v/popular/rank/all"
#获得排名
findpm = re.compile(r'data-rank="(\d*)"><div')
#获得名字
findName = re.compile(r'href=".*" target="_blank">(.*)</a> <!-- --> ')
#获得番号
findfh = re.compile(r'li class="rank-item" data-id="(.*)" data-rank')
#获得播放地址
finddz = re.compile(r'a href="//(.*)" target="_blank"><img')
#获得播放量
findbfl = re.compile(r'<i class="b-icon play"></i>\n(.*)</span> <span class="data-box">',re.S)
#获得弹幕数
finddms = re.compile(r'</span> <span class="data-box"><i class="b-icon view"></i>(.*)</span> <a',re.S)
#获得制作方
findzzf = re.compile(r'<span class="data-box up-name"><i class="b-icon author"></i>(.*)</span></a></div> <div class="pts">',re.S)
#获得综合分数
findfs = re.compile(r'<div>(\d*)</div>综合得分')
#获得指定标签内的内容
def getText(html):
#返回内容的列表
list_s = []
# 使用BeautifulSoup解析源码
bs = BeautifulSoup(html, "html.parser")
#依次解析获得内容
for item in bs.find_all('li',class_='rank-item'):
data = []
item = str(item)
#获得排名
pm = re.findall(findpm, item)[0]
data.append(pm)
# 获得名字
name = re.findall(findName,item)[0]
data.append(name)
# 获得番号
fh = re.findall(findfh, item)[0]
data.append(fh)
#获得播放地址
dz = re.findall(finddz, item)[0]
data.append(dz)
# 获得播放量
bfl = re.findall(findbfl, item)[0]
bfl = re.sub(r"\n","",bfl)
bfl = re.sub(" ", "", bfl)
data.append(bfl)
# 获得弹幕数
dms = re.findall(finddms, item)[0]
dms = re.sub(" ","",dms)
dms = re.sub(r"\n", "",dms)
data.append(dms)
# 获得制作方
zzf = re.findall(findzzf, item)[0]
zzf = re.sub(" ", "", zzf)
zzf = re.sub(r"\n", "", zzf)
data.append(zzf)
# 获得综合分数
fs = re.findall(findfs, item)[0]
data.append(fs)
list_s.append(data)
return list_s
#获取指定网页源码
def getHtml(url):
try:
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"}
# 封装二进制对象
data = bytes(urllib.parse.urlencode({"awsl": "awsl"}), encoding="utf-8")
# 封装url对象
re = urllib.request.Request(url=url, headers=header)
# 获取网页源码
res = urllib.request.urlopen(re, timeout=1)
# 打印源码
# print(res.read().decode("utf-8"))
except urllib.error.URLError as e:
print("访问超时")
return res.read().decode("utf-8")
#将爬取内容保存到excel表格中
def getExcel(list):
list_b = ['排名','视频名称','视频番号','播放地址','观看次数','弹幕数量','制作者','综合分数']
list_n = list
#创建一个表格
workbook = xlwt.Workbook(encoding="utf-8")
#创建一个工作表
worksheet = workbook.add_sheet("哔哩哔哩排行榜")
#写入数据
for i in range(0,8):
#写入表头
worksheet.write(0,i,list_b[i])
for i in range(0, 100):
for j in range(0, 8):
#写入内容
worksheet.write(i+1,j, list_n[i][j])
#关闭并保存
workbook.save("bilibili每日排行.xls")
if __name__ == "__main__":
list = []
#获取网页源码
html = getHtml(url)
#获取标签内容
list = getText(html)
#将获取数据写入excel表格
getExcel(list)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









