






学习时间:9:00——11:00 14:30——16:30
今天先做了一个项目(爬取豆瓣电影top250信息,并保存数据到Excel)为下面的学习提供数据。以下是源代码:
#用的是xpath解析数据,个人认为xpath比bs4和re简便
import requests
import xlwt
from lxml import etree
baseurl = 'https://movie.douban.com/top250'
header = {
'xxx'
}
data_list = []
for i in range(10):
url = baseurl + '?start='+ str(i * 25) + '&filter='
page_text = requests.get(url=url,headers=header).text
tree = etree.HTML(page_text)
movie_list = tree.xpath('//ol[@class="grid_view"]/li')
for movie in movie_list:
title = movie.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
author = movie.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip()
score = movie.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
index = movie.xpath('./div/div[1]/em/text()')[0]
inq = movie.xpath('./div/div[2]/div[2]/p[2]/span/text()')
if inq:
inq = inq[0]
else:
inq = ' '
data_list.append([index,title,score,inq,author])
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('豆瓣top250')
col = ('排名', '电影名', '评分', '简介', '导演主演')
for i in range(0, 5):
sheet.write(0, i, col[i])
for i in range(0, 250):
data = data_list[i]
for j in range(0, 5):
sheet.write(i+1, j, data[j])
book.save('豆瓣top250.xls')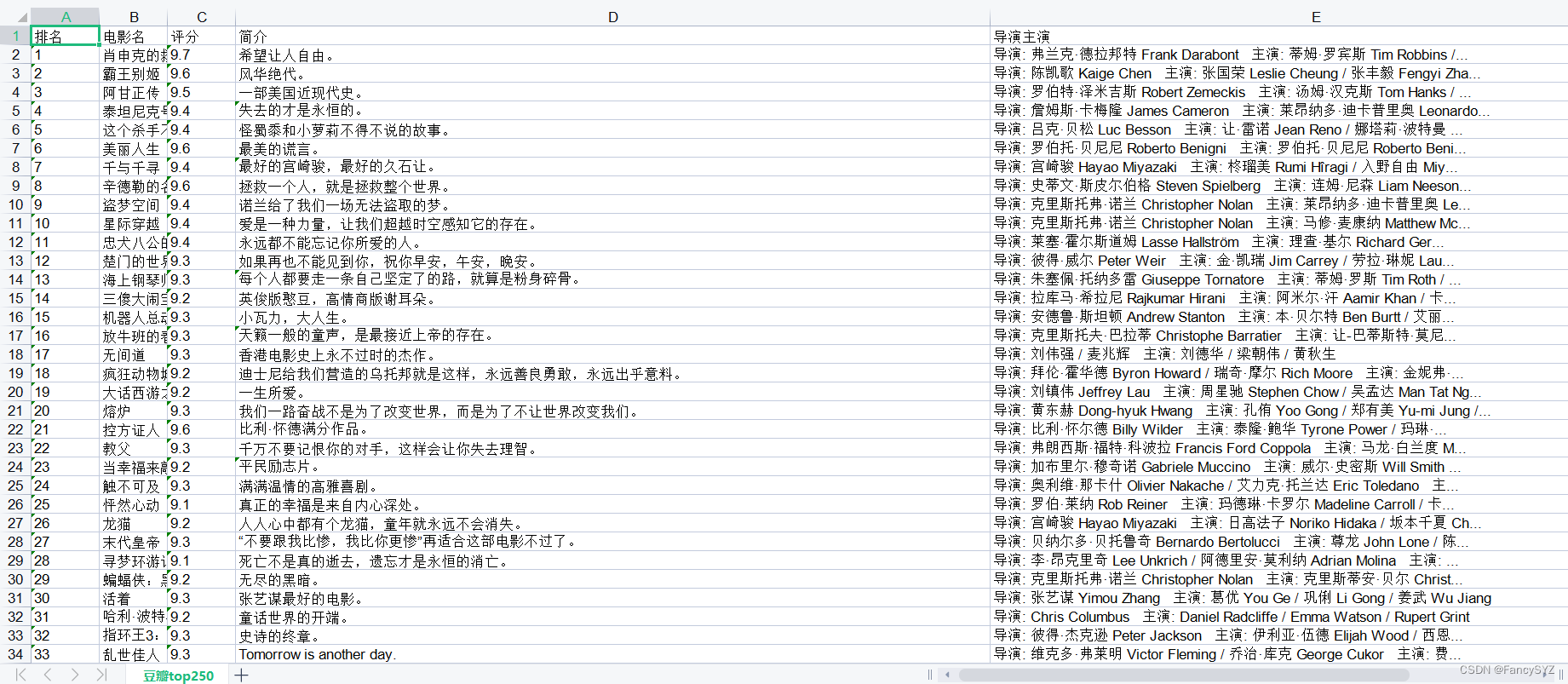















 3491
3491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









