






学习时间:9:00——12:00 15:00——18:30
昨天并不是没学,而是鸽了一天,因为没有学过数据库,所以后续操作无法完成,于是今天打算先补一补数据库,然后把项目肝完
sqlite3:
import sqlite3
conn = sqlite3.connect('test.db') #打开或创建数据库文件
print('opened database successfully.')首次操作创建db文件需要下载sql驱动,点击右侧的数据库(database),点击加号下的数据源,找到所用的数据库(我用的SQLite),点击测试连接(test connection),首次会提示缺少驱动文件,点击下载即可完成,再点击文件右侧的加号找到db文件路径,替换即可
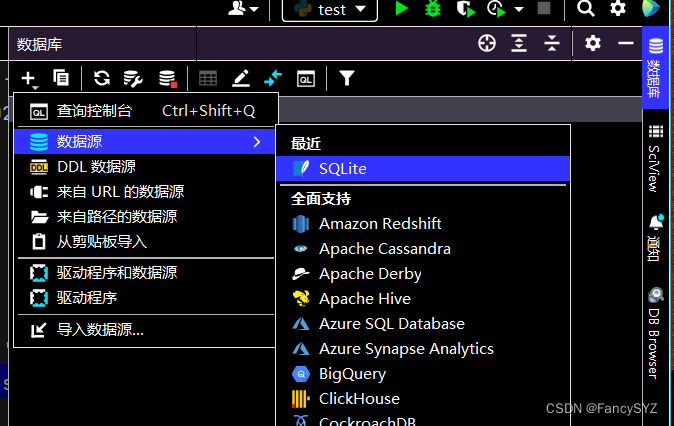
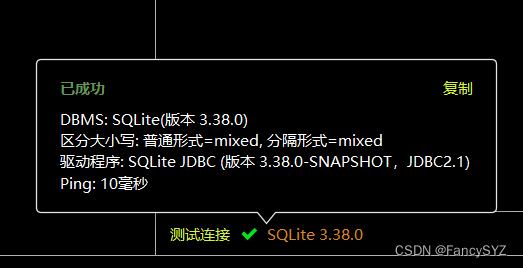
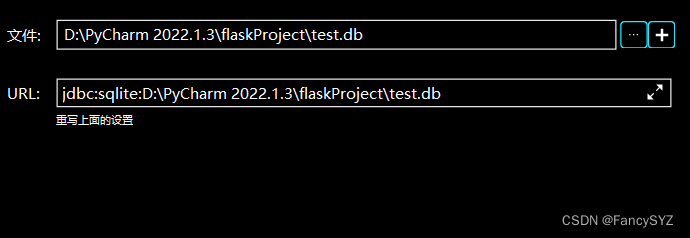
连接成功后就开始搭建数据库:
import sqlite3
conn = sqlite3.connect('test.db') #打开或创建数据库文件
print('成功打开数据库')
c = conn.cursor() #获取游标
sql = '''
create table company
(id int primary key not null,
name text not null,
age int not null,
address char(50),
salary real);
'''
c.execute(sql) #执行sql语句
conn.commit() #提交数据库操作
conn.close() #关闭数据库链接
print('成功建表')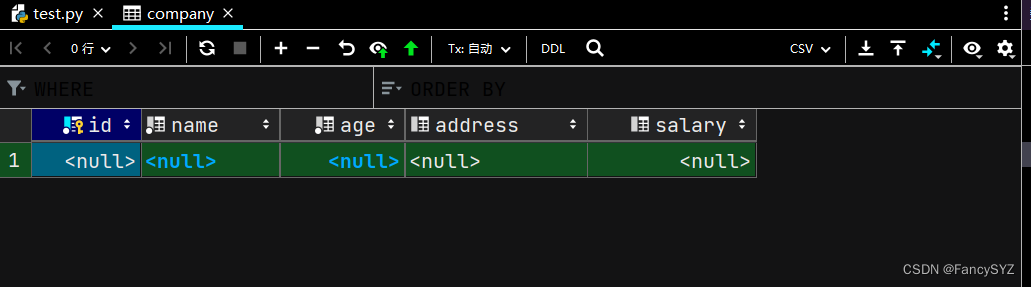
PS:游标(cursor)是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果。每个游标区都有一个名字,用户可以用SQL语句逐一从游标中获取记录,并赋给主变量,交由主语言进一步处理。
游标是处理结果集的一种机制吧,它可以定位到结果集中的某一行,多数据进行读写,也可以移动游标定位到你所需要的行中进行操作数据。一般复杂的存储过程,都会有游标的出现,他的用处主要有:
- 定位到结果集中的某一行。
- 对当前位置的数据进行读写。
- 可以对结果集中的数据单独操作,而不是整行执行相同的操作。
- 是面向集合的数据库管理系统和面向行的程序设计之间的桥梁。
插入数据:
import sqlite3
conn = sqlite3.connect('test.db') #打开或创建数据库文件
print('成功打开数据库')
c = conn.cursor() #获取游标
sql1 = '''
insert into company(id,name,age,address,salary)
values(1,'张三',32,'深圳',15000)
'''
sql2 = '''
insert into company(id,name,age,address,salary)
values(2,'李四',30,'深圳',30000)
'''
c.execute(sql1) #执行sql语句
c.execute(sql2)
conn.commit() #提交数据库操作
conn.close() #关闭数据库链接
print('插入数据完毕')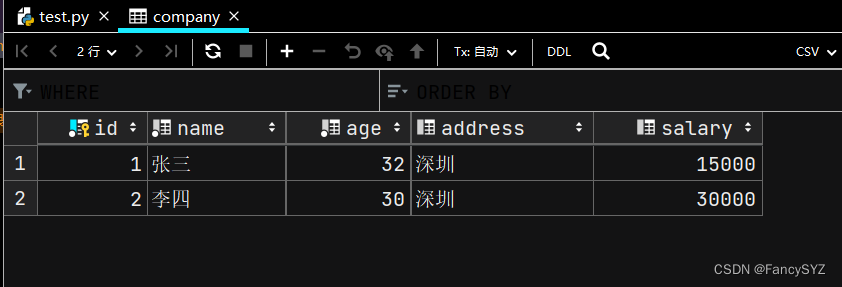
查询数据:
import sqlite3
conn = sqlite3.connect('test.db') #打开或创建数据库文件
print('成功打开数据库')
c = conn.cursor() #获取游标
sql = "select id,name,age,address,salary from company"
cursor = c.execute(sql) #执行sql语句
for row in cursor: #将每行都当做是一个列表
print("id = ",row[0])
print("name = ", row[1])
print("age = ",row[2])
print("address = ", row[3])
print("salary = ", row[4],"\n")
#conn.commit() #提交数据库操作
conn.close() #关闭数据库链接
print('查询完毕')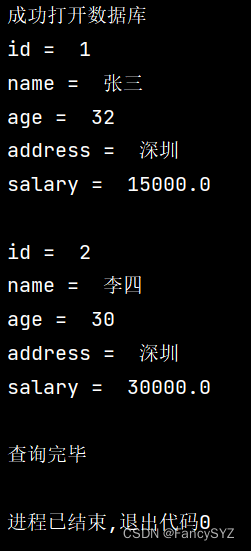
也可以用fetchall(),只不过返回的是以元组(行为单位)为元素的列表:
import sqlite3
conn = sqlite3.connect('test.db') #打开或创建数据库文件
print('成功打开数据库')
c = conn.cursor() #获取游标
sql = "select id,name,age,address,salary from company"
cursor = c.execute(sql) #执行sql语句
# for row in cursor:
# print("id = ",row[0])
# print("name = ", row[1])
# print("age = ",row[2])
# print("address = ", row[3])
# print("salary = ", row[4],"\n")
print(cursor.fetchall())
#conn.commit() #提交数据库操作
conn.close() #关闭数据库链接
print('查询完毕')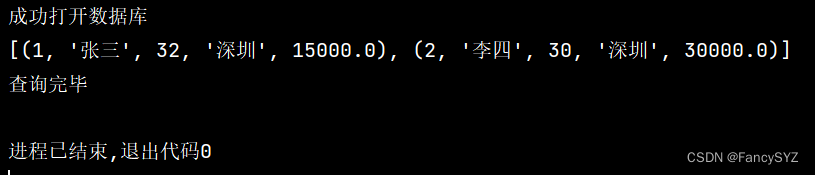
这下就完成了数据库的保存,接下来完成豆瓣电影top250存储到sqlite3的操作,源码如下:
import requests
from lxml import etree
import sqlite3
baseurl = 'https://movie.douban.com/top250'
header = {
'user-agent': 'xxx'
}
data_list = []
#获取并访问响应数据
for i in range(10):
url = baseurl + '?start='+ str(i * 25) + '&filter='
page_text = requests.get(url=url,headers=header).text.replace(' ','') #防止出现NBSP
tree = etree.HTML(page_text)
movie_list = tree.xpath('//ol[@class="grid_view"]/li')
for movie in movie_list:
info_link = movie.xpath('./div/div[1]/a/@href')[0]
rating_num = movie.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
title = movie.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
author = movie.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip()
score = movie.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
rank = movie.xpath('./div/div[1]/em/text()')[0]
inq = movie.xpath('./div/div[2]/div[2]/p[2]/span/text()')
if inq:
inq = inq[0]
else:
inq = ' '
data_list.append([rank,title,info_link,score,rating_num,inq,author])
#存储到sqlite3中
dbpath = 'movie.db'
sql = '''
create table movie250
(id integer primary key autoincrement,
rank numeric,
title varchar,
info_link text,
score numeric,
rating_num numeric,
inq text,
author text
);
'''
conn = sqlite3.connect(dbpath)
c = conn.cursor()
c.execute(sql)
conn.commit()
for data in data_list:
for index in range(len(data)):
if index == 0 or index == 3:
continue
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250(
rank,title,info_link,score,rating_num,inq,author)
values(%s)'''%",".join(data)
c.execute(sql)
conn.commit()
c.close()
conn.close()
print('保存完毕!')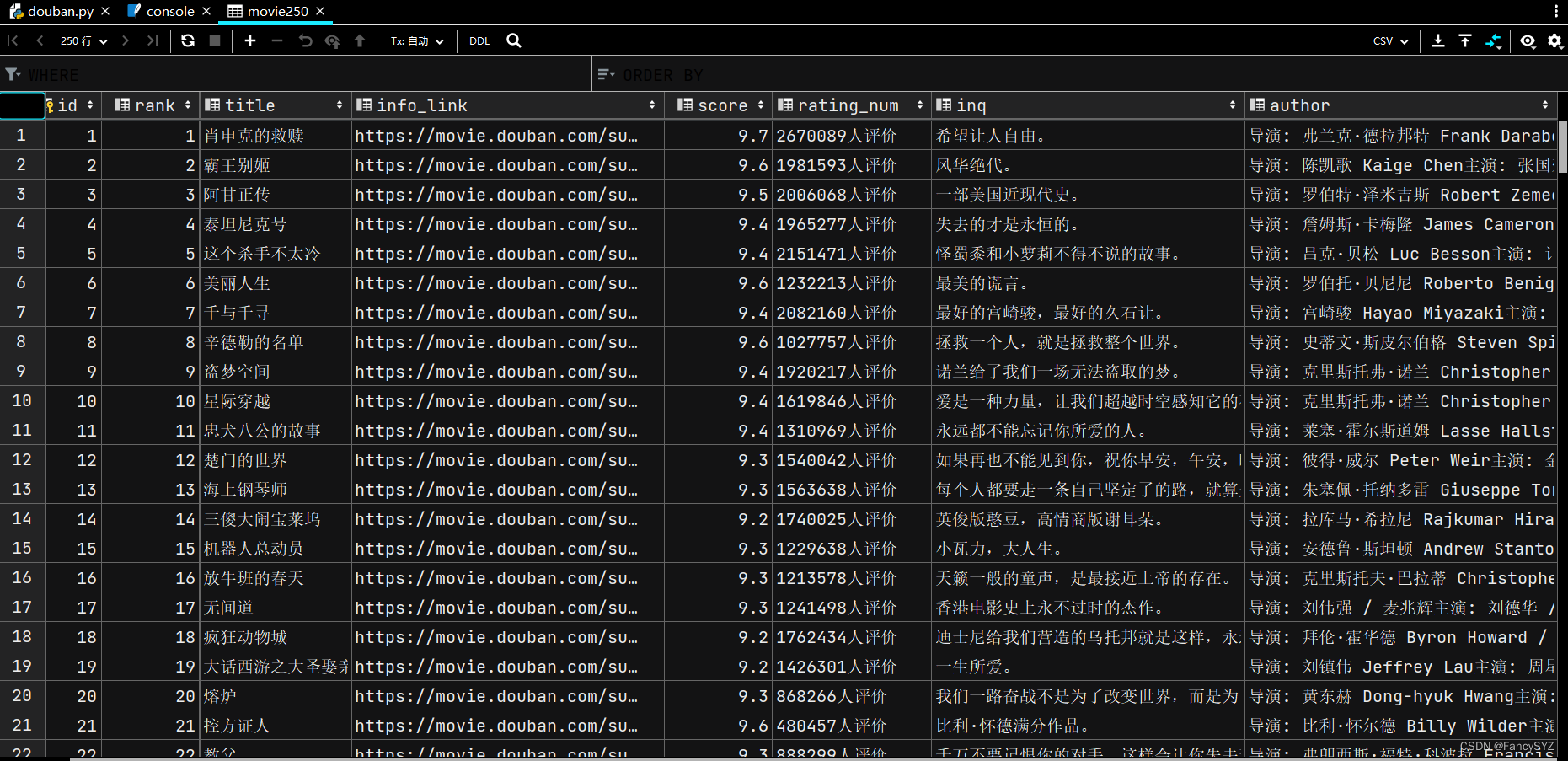
项目可视化完成(源码如下):
app.py:
from flask import Flask,render_template
import sqlite3
app = Flask(__name__)
@app.route('/')
def index():
return render_template("index.html")
@app.route('/index')
def home():
# return render_template("index.html")
return index()
@app.route('/movie')
def movie():
datalist = []
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
return render_template("movie.html",movies = datalist)
@app.route('/score')
def score():
score = [] #评分
num = [] #评分对应人数
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select score,count(score) from movie250 group by score"
data = cur.execute(sql)
for item in data:
score.append(str(item[0]))
num.append(item[1])
cur.close()
con.close()
return render_template("score.html",score=score,num=num)
@app.route('/word')
def word():
return render_template("word.html")
@app.route('/team')
def team():
return render_template("team.html")
if __name__ == '__main__':
app.run()testCloud.py:
import jieba #分词
import sqlite3 #数据库
from matplotlib import pyplot as plt #绘图,数据可视化
from wordcloud import WordCloud #词云
from PIL import Image #图片处理
import numpy as np #矩阵运算
#准备词云所需的文字(词)
con = sqlite3.connect('movie.db')
cur = con.cursor()
sql = 'select inq from movie250'
data = cur.execute(sql)
text = ''
for item in data:
text = text + item[0]
# print(text)
cur.close()
con.close()
#分词
cut = jieba.cut(text)
string = ' '.join(cut)
print(len(string))
stopwords = {'的','你','都','是','了','人'}
#设置好遮罩图片
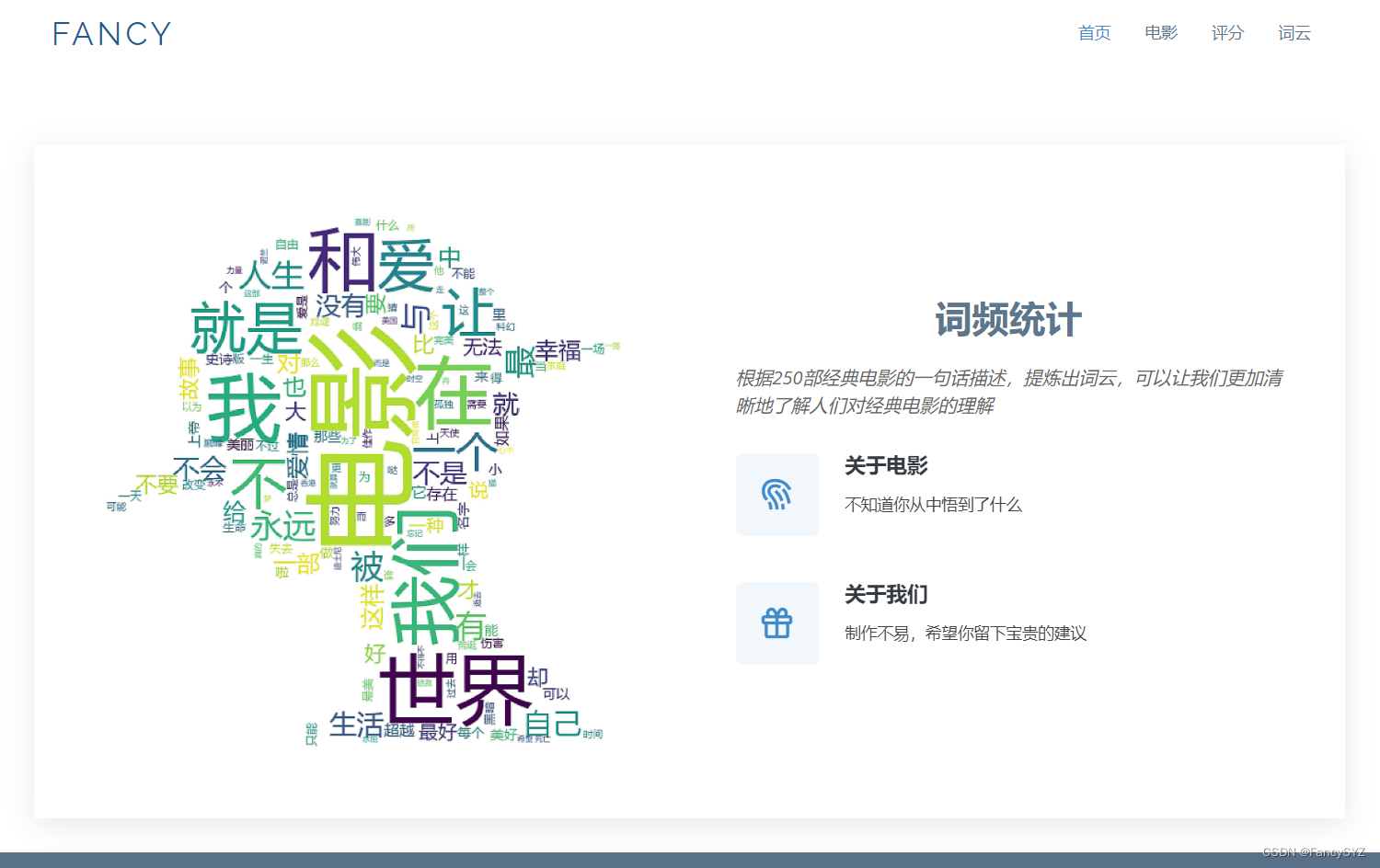
img = Image.open(r'.\static\assets\img\lufei.jpg') #打开遮罩图片
img_array = np.array(img) #将图片转换为数组
wc = WordCloud(
background_color='white',
mask=img_array,
font_path="msyh.ttc",
stopwords=stopwords,
scale=2
)
wc.generate_from_text(string)
#绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') #是否显示坐标轴
#plt.show() #show 和 savefig不能同时执行,否则图片无法保存
#输出词云图片到文件
plt.savefig(r'.\static\assets\img\word.jpg',dpi = 1500)index页和word页没什么,只是在原码上稍作修改,所以放一下movie页和score页的部分代码:
<table class="table table-striped">
<tr>
<td>排名</td>
<td>电影名称</td>
<td>评分</td>
<td>评价人数</td>
<td>简介</td>
<td>导演主演</td>
</tr>
{% for movie in movies %}
<tr>
<td>{{ movie[1] }}</td>
<td>
<a href="{{ movie[3] }}" target="_blank">
{{ movie[2] }}
</a>
</td>
<td>{{ movie[4] }}</td>
<td>{{ movie[5] }}</td>
<td>{{ movie[6] }}</td>
<td>{{ movie[7] }}</td>
</tr>
{% endfor %}
</table><div class="container">
<!-- 为 ECharts 准备一个定义了宽高的 DOM -->
<div id="main" style="width: 100%;height:400px;margin: auto"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
tooltip: {},
xAxis: {
name: '评分',
data: {{ score | tojson}}
},
yAxis: {
name: '个数',
},
series: [
{
name: '个数',
type: 'bar',
data: {{ num }}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</div>网页效果如下:
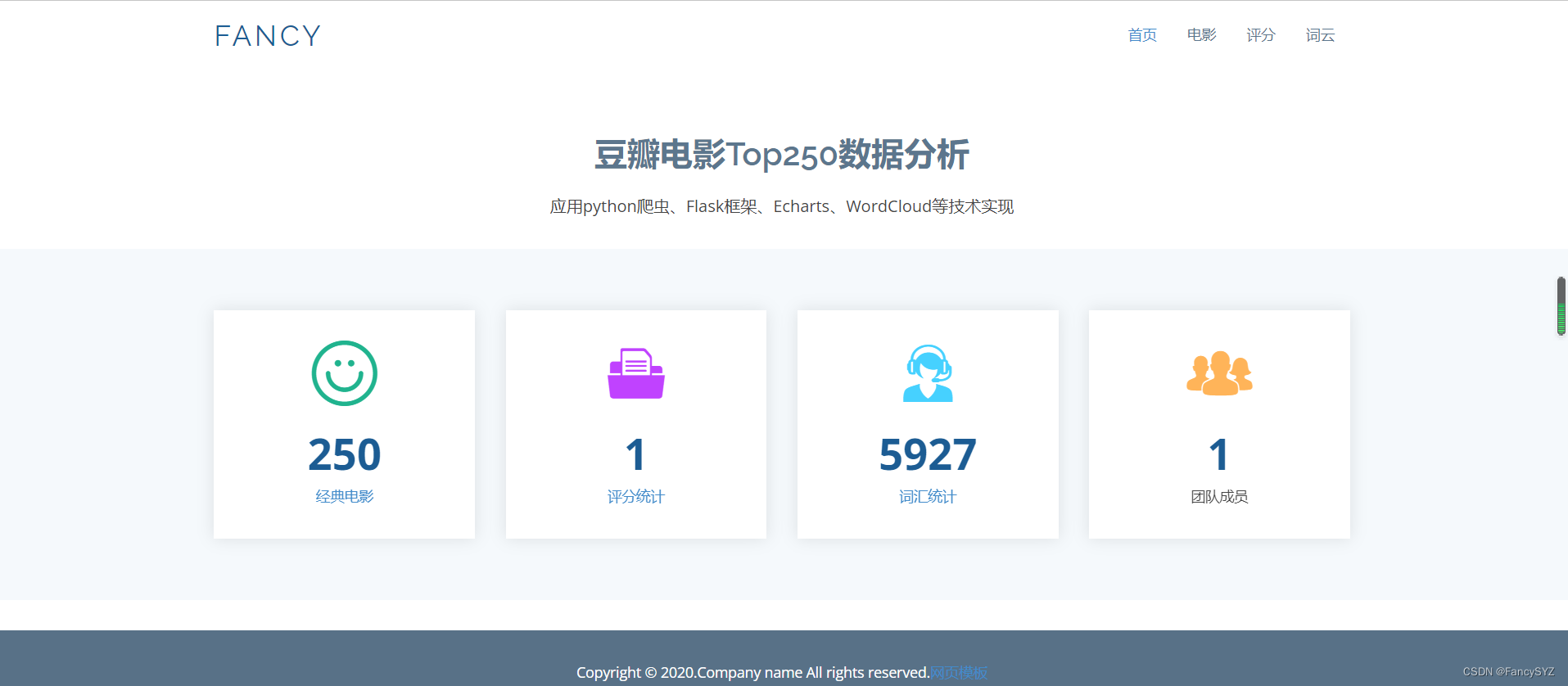
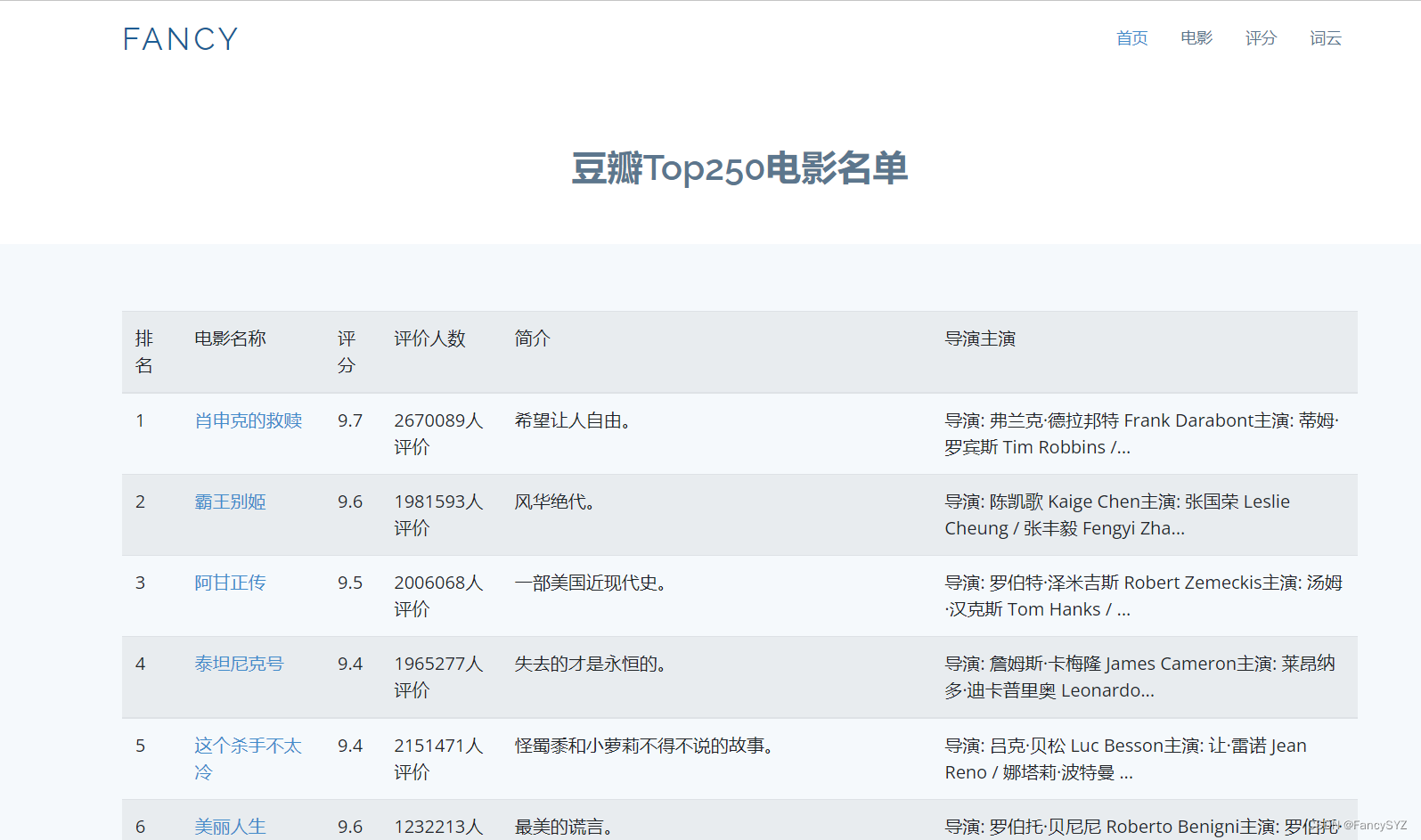
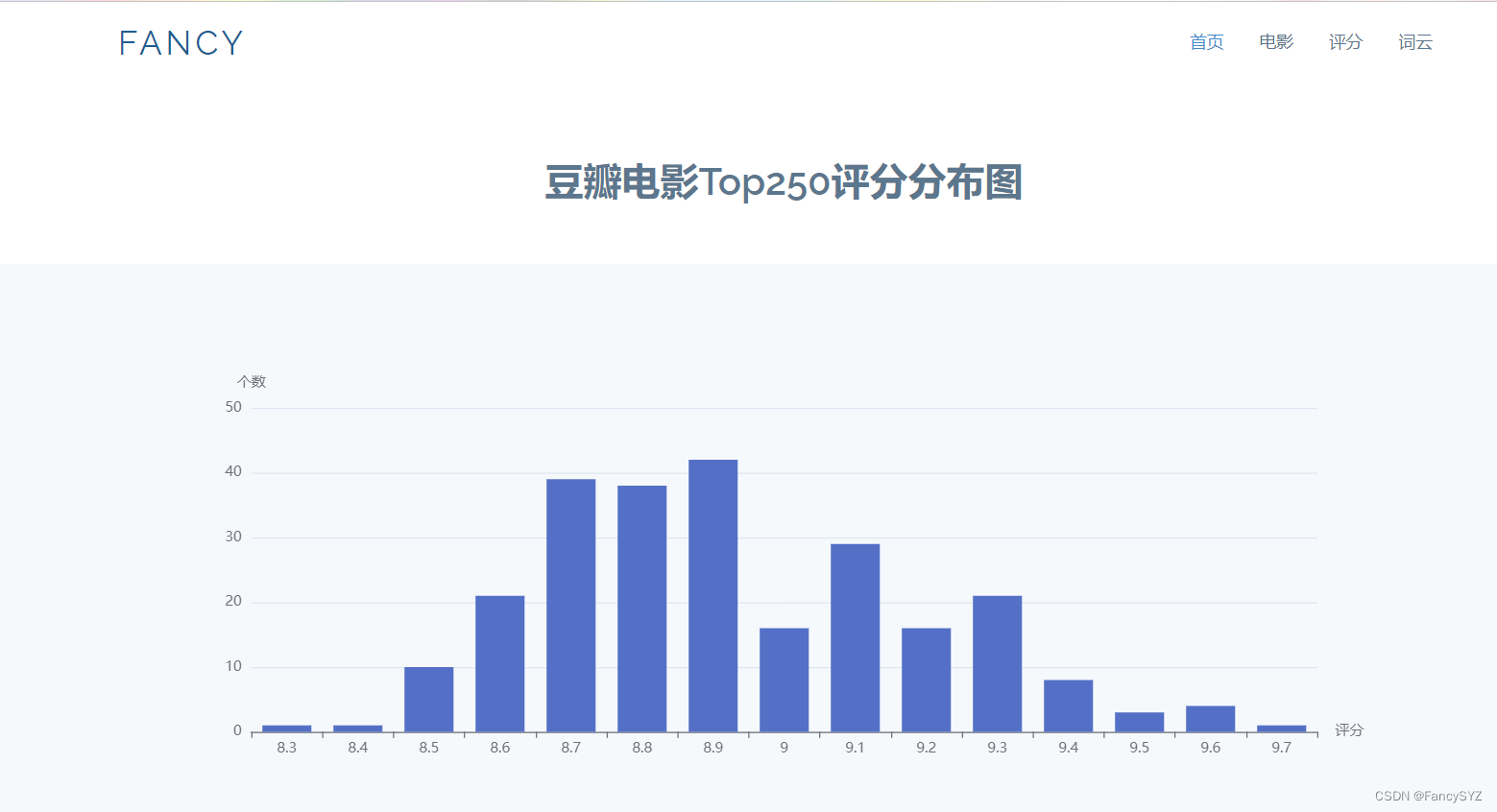















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









