1、Java文件大小
用 file.length()方法。
getTotalSpace, getFreeSpace 查询的是 磁盘(分区)空间。
(磁盘分区大小方法,放在文件File的API里,很容易让人产生歧义)
| File file = new File(filePath);
double fileLength = length(file.length());
double used = length2(file.getTotalSpace() - file.getFreeSpace());
double total = length2(file.getTotalSpace());
double free = length2(file.getFreeSpace());
System.out.println("fileLength=" + fileLength);
System.out.println("used=" + used);
System.out.println("total=" + total);
System.out.println("free=" + free);
private static double length(long length) {
return length;
}
private static double length2(long length) {
return 1.0 * length / (1024 * 1024*1024);
}
|
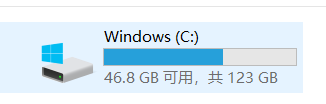
输出:
fileLength=69120.0 (文件大小为69120字节)
used=77.01800537109375
total=123.81933212280273(总大小123G,符合事实)
free=46.801326751708984(可用,46.8G,符合事实)
2、jenkins Maven打包,没更新,加了 clean了。
啥情况呢?
从 打包的jar文件时间来看,不是最新的。初步感受是,代码也不是最新的。
目前不能100%确认。
需要关注下。
3、Fastdfs上传文件,扩展名,文件后缀 必填。
| public String uploadFile(File file) throws IOException {
log.info("one file,length:{},totalSpace:{}",file.length(),file.getTotalSpace());
String extension = FilenameUtils.getExtension(file.getName());
//Fastdf扩展名不能为空,默认为"txt"
if(StringUtils.isEmpty(extension)){
extension="txt";
}
StorePath storePath = storageClient.uploadFile(new FileInputStream(file), file.length(),
extension, null);
return getResAccessUrl(storePath);
}
|
4、文件大小可以为0。
下载文件的时候,判断了大小为0,不下载。
这样是有问题的。
存在文件大小为0的文件。
5、Linux设置时间
date -s '2019-09-11 14:54'
记得带引号
(每次都忘记,记不住啊)
6、springloaded热部署
好处是,普通代码,比如实体类的属性,改完代码保存就生效。
缺点是,代码改动,就“重新加载”,debug时,上下文变量根本看不到。也就是说,如果是debug,还是得重启啊。
这个技术是有很大“局限性”的。
7、fastdfs下载时恢复原始文件名(尚未验证)
| 文件被上传到FastDFS后Storage服务端将返回的文件索引(FID),其中文件名是根据FastDFS自定义规则重新生成的 例如:wKgB-lkdxUmAPb-QAAIbD3CxJDw317.txt,而不是原始文件名,使用http下载时如不加处理,显示给用户的文件名会是这样的wKgB-lkdxUmAPb-QAAIbD3CxJDw317.txt,这样的用户体验很不好。由于FastDFS不会存储原始文件名,也不提供回复原始名的方法,我们需要自己实现
那么就需要我们将原始文件名记录在数据库中,在下载的时候将原文件名传递到服务器,然后用nginx获取到原始文件名,在写入响应头里面
http://192.168.1.124:8000/group2/M00/00/00/wKgB-Vkb2yuAEk80AAAABpDVNbM781.txt?attname=name.txt
if ($arg_attname ~* \.(doc|docx|txt|pdf|zip|rar|txt)$) {
add_header Content-Disposition "attachment;filename=$arg_attname";
}
————————————————
版权声明:本文为CSDN博主「菜鸟里根」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sunqingzhong44/article/details/72852751
|
8、数据库表同步,2种方式
A表和B表,需要同步到A1、B1。
“看似简单”的方式,查询A,再关联A的多个B。
经过加工,保存到A1和多个B1。
又有新需求,B1中有文件下载,增加了C1表。
以此类推,表越来越多,任务越来越多,同步很容易出错。
某个字段变化了,是否需要更新呢?业务要求能更新吗?
怎么防重。
因此有了第2种方式,
A表到A1。
B表到B1。
可以做成2个独立的任务。
A1产生C1 或 B1产生 C1,再单独加任务。
拆分成“流水线”式的,思路清晰,代码简单,事务可控,增加更新也简单,排查问题也方便。
都是泪。






















 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









