







参考资料:吴恩达机器学习视频、吴恩达深度学习视频及作业、百度百科。
一、神经网络概述
1.什么是神经网络?
这里所说的神经网络并不是生物学上的神经网络,这里特指的是机器学习中的人工神经网络,它是一种模仿生物神经网络的结构和功能的数学模型或计算模型。它是指按照一定的规则将多个神经元连接起来的网络。
2.什么是神经元?
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。
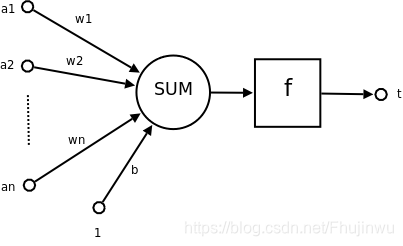
图1.1 神经元
二、最简单的神经网络——逻辑回归
1.搭建简单的神经网络的步骤
1.1 输入模型结构
1.2 初始化模型参数
1.3 循环:①计算当前损失(正向传播)→②计算当前梯度(反向传播)→③更新参数
2.逻辑回归的公式定义
逻辑回归公式:![]() 其中
其中![]() ,
,![]() (我们暂定为这个激活函数)
(我们暂定为这个激活函数)
损失函数: ![]()
代价函数: ![]()
损失函数与代价函数的区别在于,损失函数只适用于单个训练样本,而代价函数是参数的总代价。
3.正向传播与反向传播(单样本)
输入w1 x1 w2 x2 b → ![]() →
→ ![]() → L(a,y)
→ L(a,y)
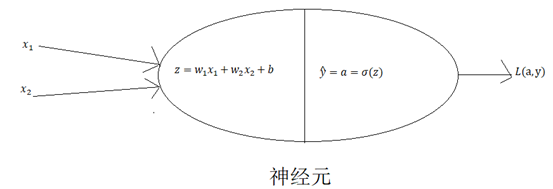
图2.1逻辑回归
3.1正向传播
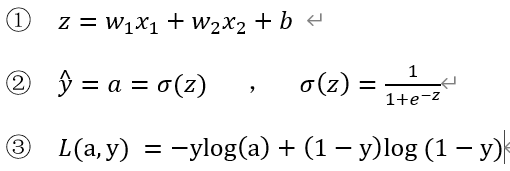
3.2反向传播
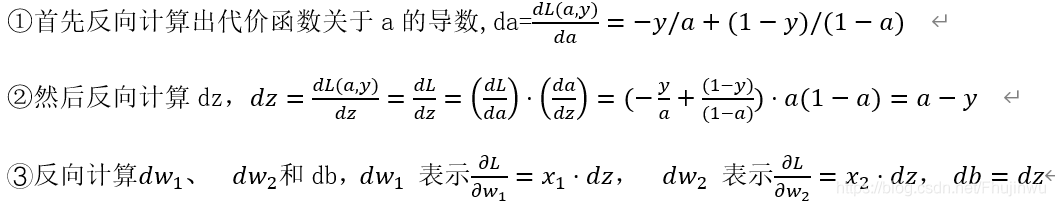
4.正向传播和反向传播(m个样本)
4.1正向传播

4.2反向传播:

4.3正向传播与反向传播的代码实现
def propagate(w, b, X, Y):
"""
实现前向和后向传播的成本函数及其梯度。
参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 矩阵类型为(num_px * num_px * 3,训练数量)
Y - 真正的“标签”矢量
返回:
cost- 逻辑回归的负对数似然成本
dw - 相对于w的损失梯度,因此与w相同的形状
db - 相对于b的损失梯度,因此与b的形状相同
"""
m = X.shape[1]
# 正向传播
A = sigmoid(np.dot(w.T, X) + b)
cost= (-1/m) * np.sum(Y * np.log(A) + (1-Y)*(np.log(1 - A)))
# 反向传播
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A - Y) # 请参考视频中的偏导公式。
# 使用断言确保我的数据是正确的
assert (dw.shape == w.shape)
assert (db.dtype == float)
cost = np.squeeze(cost)
assert (cost.shape == ())
# 创建一个字典,把dw和db保存起来。
grads = {
"dw": dw,
"db": db
}
return (grads, cost)
三、浅层神经网络
1.浅层神经网络概述
我们这里介绍使用一个隐含层和一个输出层的二层神经网络(当我们在计算网络的层数时,我们是不计算输入层的)。其实两层的神经网络就是把两个单个神经网络有机的结合起来,就搭建好了。再多层的神经网络也可依次类推。搭建的神经网络如图所示:
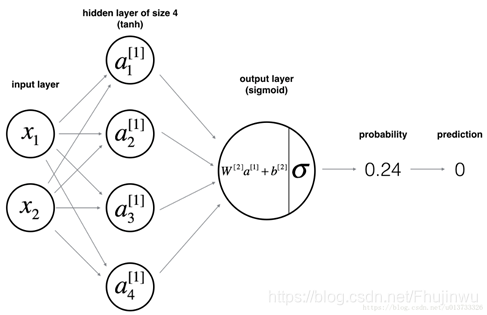
图3.1两层神经网络
2.权重的初始化
当我们训练神经网络的时候,初试化W【l】和b【l】是非常重要的。
首先,我们必须要明确W【l】和b【l】的维度,在神经网络中,W的维度是(下一层的神经元个数,前一层的神经元个数),b的维度是(下一层的神经元个数,1)。在如图3.1所示的神经网络中,W【l】和b【l】的维度如下所示:W【1】=(4,2),W【2】=(1,4),b[1]=(4,1),b[1]=(1,1)
其次,W【l】和b【l】的初始化中,b[l]可以初始化为0,但是W[l]不能初始化为0。因为如果我们把权重或者参数都初始化为0的话,那么梯度下降将无法起作用。
初始化代码如下:
def initialize_parameters(n_x, n_h, n_y):
"""
参数:
n_x - 输入层节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2)
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
# 使用断言确保我的数据格式是正确的
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
3.几种常见的激活函数介绍
3.1 激活函数有许多中,使用哪种激活函数取决于具体的情况,比如是隐函数还是输出层,是二分类问题还是其他问题。
sigmoid函数: ![]()
导数:![]()
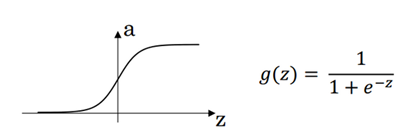
图3.2 sigmoid函数
tanh函数:![]()
导数::

图3.3 tanh函数
ReLU函数:![]()
导数:
Leaky ReLU函数: ![]() (这里可以不是0.01)
(这里可以不是0.01)
导数: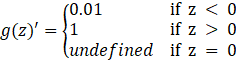

图3.4 ReLU函数和Leaky ReLU函数
3.2不同激活函数的结论
sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
ReLu激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLu。
4.正向传播和反向传播(m个样本)
(注明,这里输出层使用的是sigmoid函数)
4.1正向传播
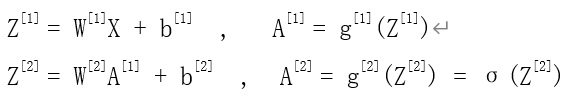
4.2正向传播代码
def forward_propagation(X, parameters):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# 前向传播计算A2
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
# 使用断言确保我的数据格式是正确的
assert (A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
4.3反向传播
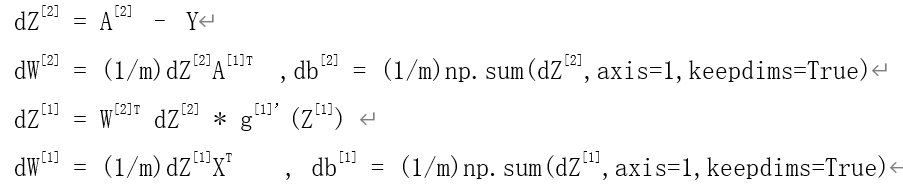
4.4反向传播代码实现:
def backward_propagation(parameters, cache, X, Y):
"""
搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2 = A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
4.5更新参数
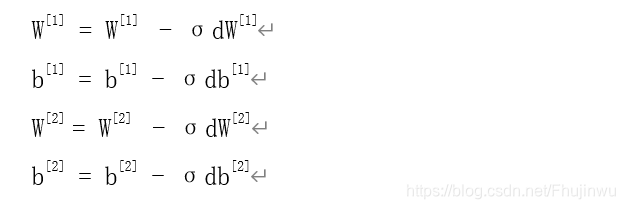
4.6更新参数代码实现:
def update_parameters(parameters, grads, learning_rate=1.2):
"""
更新参数
参数:
parameters - 包含参数的字典类型的变量。
grads - 包含导数值的字典类型的变量。
learning_rate - 学习速率
返回:
parameters - 包含更新参数的字典类型的变量。
"""
W1, W2 = parameters["W1"], parameters["W2"]
b1, b2 = parameters["b1"], parameters["b2"]
dW1, dW2 = grads["dW1"], grads["dW2"]
db1, db2 = grads["db1"], grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters














 3955
3955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









