







-
环境介绍
语言:Py,版本3.6
环境:Anaconda3 (64-bit),
编译器:Spyder,Jupyter Notebook等
实现功能:使用BP神经网络实现异或功能
神经网络搭建的思想
一个神经网络的搭建,需要满足三个条件。
- 输入和输出
- 权重(
w)和阈值(b) - 多层感知器的结构
也就是说,需要事先画出上面出现的那张图。
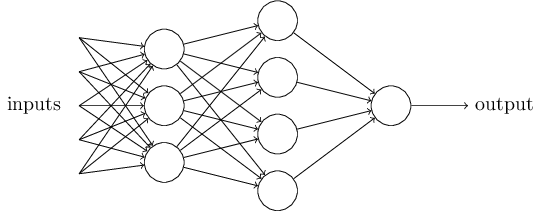
其中,最困难的部分就是确定权重(w)和阈值(b)。目前为止,这两个值都是主观给出的,但现实中很难估计它们的值,必需有一种方法,可以找出答案。
这种方法就是试错法。其他参数都不变,w(或b)的微小变动,记作Δw(或Δb),然后观察输出有什么变化。不断重复这个过程,直至得到对应最精确输出的那组w和b,就是我们要的值。这个过程称为模型的训练。
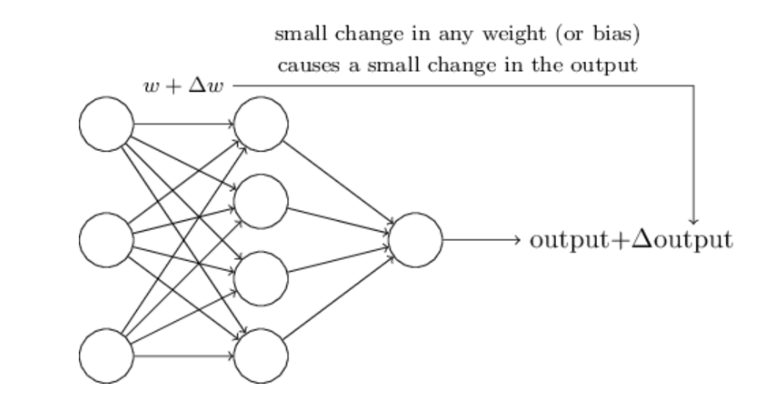
因此,神经网络的运作过程如下。
- 确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算
w和b - 一旦新的数据产生,输入模型,就可以得到结果,同时对
w和b进行校正
这部分内容引用:http://www.ruanyifeng.com/blog/2017/07/neural-network.html
-
什么是异或
| 输入 | 运算符 | 输入 | 结果 |
| 1 | ⊕ | 0 | 1 |
| 1 | ⊕ | 1 | 0 |
| 0 | ⊕ | 0 | 0 |
| 0 | ⊕ | 1 | 1 |
就是在0,1这俩哥们之间进行一种运算,两个数相同为0,不同为1.
神经网络实现异或的思路
输入:两个数:x1,x2,外加一个偏置x0,共有三个数
输出:1个数
训练的时候放多个数据集,一般为矩阵的形式,输出就是向量的形式了。
输入1,0,1,。第一位是偏置,所有的偏置都设置为1.第二、三个数就是我们的训练集。输出是1.
神经网络设计:
- 输入层三个单元
- 隐层4个单元
- 输出层输出一个单元(因为只需要输出计算结果,一个数,要么是0要么是1)
- 输入层到隐层的权值个数:由1,2可以算出权值的个数为3*4=12个。准确的说这12个值里面有4个偏置值,8个权值。
- 隐层到输出层的个数:4*1=4个,准确的说有3个权值,1个偏置值。
代码实现
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 4 15:24:57 2018
@author:高硕
"""
import numpy as np
#输入数据分别:偏置值,x1,x2
X = np.array([[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]])
#标签
Y = np.array([[0,1,1,0]])
#权值初始化,取值范围-1到1
V = np.random.random((3,4))*2-1
W = np.random.random((4,1))*2-1
print(V)
print(W)
#学习率设置
lr = 0.11
def sigmoid(x):
return 1/(1+np.exp(-x))
#这个函数求导
def dsigmoid(x):
return x*(1-x)
def update():
global X,Y,W,V,lr#输入,输出,权值,权值,学习率
# L1:输入层传递给隐藏层的值;输入层3个节点,隐藏层4个节点
# L2:隐藏层传递到输出层的值;输出层1个节点
L1 = sigmoid(np.dot(X,V))#隐藏层输出(4,4)
L2 = sigmoid(np.dot(L1,W))#输出层输出(4,1)
# L2_delta:输出层的误差信号
# L1_delta:隐藏层的误差信号
L2_delta = (Y.T - L2)*dsigmoid(L2)
L1_delta = L2_delta.dot(W.T)*dsigmoid(L1)
# W_C:输出层对隐藏层的权重改变量
# V_C:隐藏层对输入层的权重改变量
W_C = lr*L1.T.dot(L2_delta)
V_C = lr*X.T.dot(L1_delta)
W = W + W_C
V = V + V_C
for i in range(20000):
update()#更新权值
if i%500==0:
L1 = sigmoid(np.dot(X,V))#隐藏层输出(4,4)
L2 = sigmoid(np.dot(L1,W))#输出层输出(4,1)
print('当前误差:',np.mean(np.abs(Y.T-L2)))
L1 = sigmoid(np.dot(X,V))#隐藏层输出(4,4)
L2 = sigmoid(np.dot(L1,W))#输出层输出(4,1)
print(L2)
def judge(x):
if x>=0.5:
return 1
else:
return 0
for i in map(judge,L2):
print(i)
#打乱数据,测试一下,哈哈,测试结果正确
X = np.array([[1,0,1],
[1,1,1],
[1,1,0],
[1,0,0]])
L1 = sigmoid(np.dot(X,V))#隐藏层输出(4,4)
L2 = sigmoid(np.dot(L1,W))#输出层输出(4,1)
def judge(x):
if x>=0.5:
return 1
else:
return 0
#
for i in map(judge,L2):
print(i)
结果:
1.权重

2.误差

3.预测结果
预测数据为
X = np.array([[1,0,1],
[1,1,1],
[1,1,0],
[1,0,0]])这是实际的L2,逼近值。

可以看到经过迭代,误差越来越小,最后逼近的值很接近标签项[1,0,1,0]















 4550
4550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









