






摘要
在现实环境中应用半监督学习的一个基本限制是假设未标记的测试数据只包含以前在标记的训练数据中遇到的类。然而,这种假设很少适用于野外数据,在野外数据中,属于新类的实例可能在测试时出现。在这里,我们引入了一种新颖的开放世界半监督学习设置,该设置形式化了新类可能出现在未标记的测试数据中的概念。在这个新颖的设置中,目标是解决标记和未标记数据之间的类分布不匹配,在测试时,每个输入实例要么需要被分类到一个现有的类中,要么需要初始化一个新的不可见的类。为了解决这个具有挑战性的问题,我们提出了ORCA,这是一种端到端深度学习方法,它引入了不确定性自适应边际机制,以避免由于学习已知类的判别特征比学习新类更快而导致对已知类的偏见。通过这种方式,ORCA减少了类内方差与新类之间的差距。在图像分类数据集和单细胞注释数据集上的实验表明,ORCA始终优于其他基线,在图像分类数据集上实现了25%的改进,在ImageNet数据集的新类别上实现了96%的改进。
Introduction
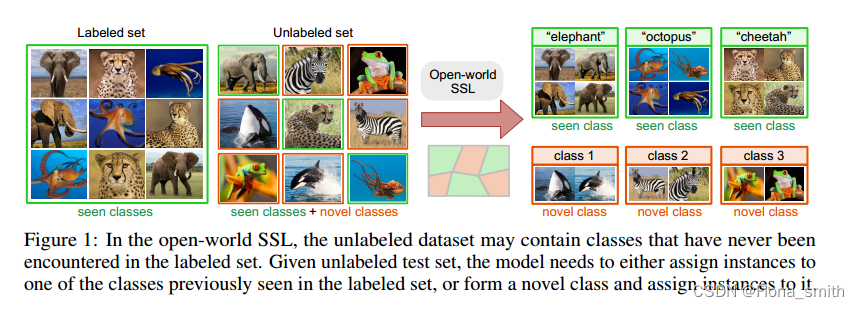
随着深度学习的出现,已经取得了显著的突破,当前的机器学习系统在具有大量标记数据的任务上表现出色(LeCun等人,2015;Silver等人,2016;Esteva et al, 2017)。尽管有这些优势,但绝大多数模型都是为封闭世界环境设计的,基于训练和测试数据来自同一组预定义类的假设(Bendale & Boult, 2015;Boult et al, 2019)。然而,这种假设很少适用于野外数据,因为标记数据依赖于对给定领域的完整了解。例如,生物学家可能预先标记已知的细胞类型(见类),然后希望将该模型应用于新的组织,以识别已知的细胞类型,同时也发现以前未知的新细胞类型(见类)。类似地,在社交网络中,人们可能希望将用户划分为预定义的兴趣组,同时发现新的未知/未标记的用户兴趣。因此,与通常假设的封闭世界相反,许多现实世界的问题本质上是开放世界——在训练期间从未见过(和标记过)的测试数据中可能出现新的类。
在这里,我们引入了开放世界半监督学习(开放世界SSL)设置,它推广了半监督学习和新类发现。在开放世界SSL下,我们有一个带标签的训练数据集和一个未带标签的数据集。标记的数据集包含属于一组已见类的实例,而未标记/测试数据集中的实例既属于已见类,也属于未知数量的未见类(图1)。在这种设置下,模型需要将实例分类为先前看到的类之一,或者发现新类并将实例分配给它们。换句话说,开放世界SSL是在类分布不匹配的情况下的转换学习设置,其中未标记的测试集可能包含在训练期间从未标记的类,即不属于标记的训练集。开放世界SSL从根本上是不同的,但与最近的两项工作密切相关:健壮的半监督学习(SSL)和新颖的类发现。健壮的SSL (Oliver等人,2018;郭等人,2020;Chen等,2020b;郭等,2020;Yu et al, 2020)假设标记和未标记数据之间的类分布不匹配,但在这种设置下,模型只需要能够识别(拒绝)属于未标记数据中新类的实例作为分布外实例。相反,开放世界SSL不是拒绝属于新类的实例,而是旨在发现单个新类,然后为它们分配实例。新类发现(Hsu et al, 2018;2019;Han等人,2019;2020;Zhong等人,2021)是一个聚类问题,其中假设未标记的数据仅由新类别组成。相比之下,开放世界的SSL更为通用,因为未标记数据中的实例既可以来自已知类,也可以来自新类。要将健壮的SSL和新颖的类发现方法应用于开放世界的SSL,原则上可以采用多步骤方法,首先使用健壮的SSL拒绝来自新类的实例,然后在被拒绝的实例上应用新颖的类发现方法来发现新类。另一种选择是,可以将所有类视为“新颖的”,应用新颖的类发现方法,然后将一些类与标记数据集中看到的类进行匹配。然而,我们的实验表明,这种特别的方法在实践中表现不佳。因此,有必要设计一种在端到端框架中解决这一实际问题的方法。
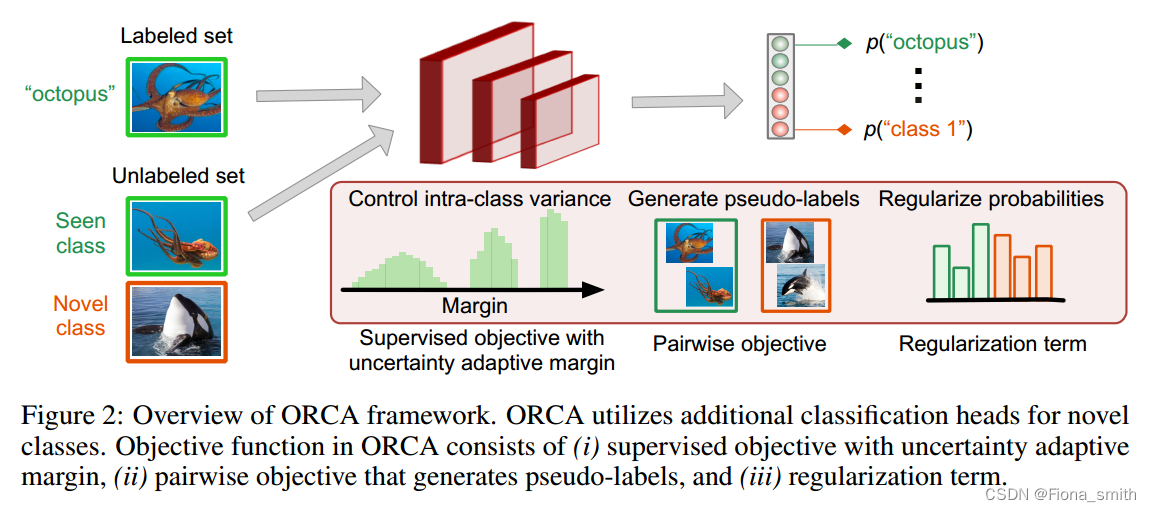
在本文中,我们提出了在新的开放世界SSL设置下运行的ORCA(基于不确定性自适应边际的开放世界)。ORCA有效地将未标记数据中的示例分配给以前见过的类,或者通过分组相似的实例形成新的类。ORCA是一个端到端深度学习框架,其中我们方法的关键是一种新的不确定性自适应边际机制,该机制在训练过程中逐渐降低了模型的可塑性,增加了模型的可辨别性。这种机制有效地减少了由于学习视觉类比学习新类更快而导致的视觉类与新类之间的类内方差之间的不希望的差距,我们认为这是这种设置中的一个关键困难。然后,我们开发了一个特殊的模型训练过程,学习将数据点分类到一组以前见过的类中,同时还学习为每个新发现的类使用额外的分类头。已见类的分类头用于将未标记的示例分配给标记集中的类,而激活额外的分类头允许ORCA形成一个新类。ORCA不需要提前知道新类的数量,可以在部署时自动发现它们。
我们在三个适用于开放世界SSL设置的基准图像分类数据集和一个来自生物学领域的单细胞注释数据集上评估了ORCA。由于没有现有的方法可以在开放世界SSL设置下运行,我们将现有的最先进的SSL、开放集识别和新颖的类发现方法扩展到开放世界SSL,并将它们与ORCA进行比较。实验结果表明,ORCA有效地解决了开放世界SSL设置的挑战,并且始终优于所有基线。具体来说,ORCA在ImageNet数据集的已知类和新类上分别实现了25%和96%的改进。此外,我们还证明了ORCA对未知数量的新类、已知类和新类的不同分布、不平衡数据分布、预训练策略和少量标记样例具有鲁棒性。
相关工作
我们在表1中总结了开放世界SSL和相关设置之间的异同。其他相关工作见附录A。
新的类别发现。在新颖的类发现(Hsu et al, 2018;Han et al ., 2020;Brbic等,2020;Zhong等人,2021),任务是聚类由类似但完全不相交的类别组成的未标记数据集,而不是标记数据集中存在的类别,用于学习更好的聚类表示。这些方法假定在测试时所有的类都是新的。虽然这些方法能够发现新的类,但它们不能识别已见/已知的类。相反,我们的开放世界SSL更通用,因为未标记的测试集包括新类,但也包括以前在标记数据中看到的需要标识的类。原则上,可以通过在测试时将所有类视为“新颖”,然后将其中一些类与标记数据集中的已知类进行匹配,从而扩展新类发现方法。我们采用这样的方法作为我们的基线,但我们的实验表明,它们在实践中表现不佳。
半监督学习(SSL)。SSL方法(Chapelle et al, 2009;Kingma et al ., 2014;Laine & Aila, 2017;翟等人,2019;李,2013;谢等,2020;Berthelot et al, 2019;2020;Sohn等人,2020)假设封闭世界设置,其中标记和未标记的数据来自同一组类。健壮的SSL方法(Oliver等人,2018;Chen等,2020b;郭等,2020;Yu et al, 2020)通过假设来自新类的实例可能出现在未标记的测试集中来放宽SSL假设。健壮SSL的目标是拒绝来自新类的实例,这些新类被视为分布外实例。在开放世界SSL中,我们的目标不是拒绝来自新类的实例,而是发现单个新类,然后为它们分配实例。要将健壮的SSL扩展到开放世界的SSL,可以对丢弃的实例应用集群/新颖的类发现方法。早期的工作(Miller & Browning, 2003)考虑使用EM算法的扩展以这种方式解决问题。然而,我们的实验表明,通过丢弃这些方法学习的嵌入不能准确地发现新的类。
开放集和开放世界识别。开放集识别(Scheirer等,2012;耿等,2020;Bendale & Boult, 2016;Ge等,2017;Sun et al ., 2020a)考虑了在测试过程中可能出现新颖类的归纳设置,模型需要拒绝来自新颖类的实例。为了将这些方法扩展到开放世界设置,我们包含了一个基线,用于在被拒绝的实例上发现类。然而,结果表明,这种方法不能有效地解决开放世界SSL的挑战。类似地,开放世界识别方法(Bendale & Boult, 2015;Rudd et al ., 2017;Boult等人,2019)要求系统增量学习并用新类扩展已知类集。这些方法通过human-in-the-loop对新类进行增量标记。相比之下,开放世界SSL在学习阶段利用未标记的数据,不需要人工参与。
广义零学习(GZSL)。与开放世界SSL一样,GZSL (Xian et al ., 2017;Liu et al ., 2018;Chao et al ., 2016)假设在标记集中看到的类和新类在测试时存在。然而,GZSL对先验知识的可用性施加了额外的假设,作为唯一描述每个单独类(包括新类)的辅助属性。这种限制性假设严重限制了GZSL方法在实践中的应用。相比之下,开放世界的SSL更为通用,因为它不假定任何关于类的先验信息。
提出的方法
在本节中,我们首先定义开放世界SSL设置。我们将对ORCA框架进行概述,然后详细介绍我们框架的每个组件。
开放世界半监督学习设置
在开放世界半监督学习中,我们假设转换学习设置,数据集的标记部分
D
l
=
{
(
x
i
,
y
i
)
}
i
=
1
n
\mathcal{D}_{l}=\{(x_{i},y_{i})\}_{i=1}^{n}
Dl={(xi,yi)}i=1n和数据集未标记部分
D
u
=
{
(
x
i
}
i
=
1
m
\mathcal{D}_{u}=\{(x_{i}\}_{i=1}^{m}
Du={(xi}i=1m作为输入。我们将标记数据中的类集表示为
C
l
C_l
Cl,将未标记测试数据中的类集表示为
C
u
C_u
Cu。我们假设类别/类别移位,即
C
l
∩
C
u
≠
∅
a
n
d
C
l
≠
C
u
.
\mathcal{C}_{l}\cap\mathcal{C}_{u}\neq\emptyset\mathrm{~and~}\mathcal{C}_{l}\neq\mathcal{C}_{u}.
Cl∩Cu=∅ and Cl=Cu.。我们认为
C
s
=
C
l
∩
C
u
\mathcal{C}_{s} = \mathcal{C}_{l}\cap\mathcal{C}_{u}
Cs=Cl∩Cu是一个已知类的集合,
C
n
=
C
u
\
C
l
\mathcal{C}_{n} = \mathcal{C}_{u}\backslash\mathcal{C}_{l}
Cn=Cu\Cl是一个新类的集合。
定义1(开放世界SSL)。在开放世界的SSL中,模型需要将
D
u
D_u
Du中的实例分配给以前看到的类
C
s
C_s
Cs,或者形成一个新的类
c
∈
C
n
c\in\mathcal{C}_{n}
c∈Cn并将实例分配给它。
注意,开放世界SSL概括了新颖的类发现和传统的(封闭世界)SSL。新颖的类发现假设标记数据和未标记数据中的类是不相交的,即
C
l
\
C
u
=
∅
\mathcal{C}_{l} \backslash \mathcal{C}_{u} =\emptyset
Cl\Cu=∅;,而(封闭世界)SSL假设标记数据和未标记数据中的类相同,即
C
l
=
C
u
.
\mathcal{C}_l=\mathcal{C}_u.
Cl=Cu.。
ORCA概述
解决开放世界SSL的关键挑战是既要从可见/标记的类中学习,也要从不可见/未标记的类中学习。这是具有挑战性的,因为与新类相比,模型在已知类上学习判别表示的速度更快。这导致与新类相比,已见类的类内方差较小。为了解决这个问题,我们提出了ORCA,一种利用不确定性自适应边界在训练过程中减小已知类和新类之间的类内方差差距的方法。ORCA的关键是使用未标记数据的不确定性来控制已见类的类内方差:如果未标记数据的不确定性很高,我们将强制较大的已见类的类内方差,以减少已见类和新类的方差之间的差距,而如果不确定性很低,我们将强制较小的已见类的类内方差,以鼓励模型充分利用标记数据。通过这种方式,使用不确定性自适应边界,我们控制了已知类的类内方差,并确保与新类相比,已知类的判别表示不会学习得太快。
给定标记实例
X
l
=
{
x
i
∈
R
N
}
i
=
1
n
\mathcal{X}_{l} = \{x_{i} \in \mathbb{R}^{N}\}_{i=1}^{n}
Xl={xi∈RN}i=1n和未标记实例
X
u
=
{
x
i
∈
R
N
}
i
=
1
m
\mathcal{X}_{u} = \{x_{i} \in \mathbb{R}^{N}\}_{i=1}^{m}
Xu={xi∈RN}i=1m ORCA首先应用嵌入函数
f
θ
:
R
N
→
R
D
f_\theta:\mathbb{R}^N\to\mathbb{R}^D
fθ:RN→RD分别得到标记数据和未标记数据的特征表示
Z
l
=
{
z
i
∈
R
D
}
i
=
1
n
\mathcal{Z}_{l}=\{z_{i}\in{\mathbb{R}^{D}}\}_{i=1}^{n}
Zl={zi∈RD}i=1n和
Z
u
=
{
z
i
∈
R
D
}
i
=
1
m
\mathcal{Z}_{u}=\{z_{i}\in{\mathbb{R^{D}}}\}_{i=1}^{m}
Zu={zi∈RD}i=1m。这里,
z
i
=
f
θ
(
x
i
)
z_i = f_θ(x_i)
zi=fθ(xi)对于每个实例
x
i
∈
X
l
∪
X
u
x_{i}\in\mathcal{X}_{l}\cup\mathcal{X}_{u}
xi∈Xl∪Xu。在主干网的顶部,我们添加了一个由权重矩阵
W
:
R
D
→
R
∣
C
l
∪
C
u
∣
W:\mathbb{R}^{D}\to\mathbb{R}^{|\mathcal{C}_{l}\cup\mathcal{C}_{u}|}
W:RD→R∣Cl∪Cu∣参数化的单一线性层组成的分类头,后面是一个softmax层。注意,分类头的数量被设置为以前见过的类的数量和期望的新类的数量。因此,第一个
∣
C
l
∣
|C_l|
∣Cl∣头将实例分类为前面看到的类之一,而其余的头将实例分配给新的类。最终的类/聚类预测计算为
c
i
=
argmax
(
W
T
⋅
z
i
)
∈
R
.
c_{i}=\operatorname{argmax}(W^{T}\cdot z_{i})\in\mathbb{R}.
ci=argmax(WT⋅zi)∈R.。如果
c
i
∉
C
l
c_{i}\notin\mathcal{C_l}
ci∈/Cl,则
x
i
x_i
xi属于新类。新类的数量
∣
C
u
∣
|C_u|
∣Cu∣可以已知并作为算法的输入,这是聚类和新类发现方法的典型假设。但是,如果事先不知道新类的数量,则可以使用大量的预测头像/新的类别来初始化ORCA。ORCA目标函数然后通过不将任何实例分配给不需要的预测头来推断类的数量,因此这些头永远不会激活。
ORCA中的目标函数由三个部分组成(图2)(i)带不确定性自适应边界的监督目标,(ii)成对目标,(iii)正则化项:
L
=
L
S
+
η
1
L
P
+
η
2
R
,
(
1
)
\mathcal{L}=\mathcal{L}_{\mathrm{S}}+\eta_{1}\mathcal{L}_{\mathrm{P}}+\eta_{2}\mathcal{R},\quad(1)
L=LS+η1LP+η2R,(1)其中
L
S
L_S
LS为监督目标,
L
P
L_P
LP为成对目标,
R
R
R为正则化。
η
1
η_1
η1和
η
2
η_2
η2是我们所有实验中设为1的正则化参数。该算法的伪代码在附录B的算法1中进行了总结。我们在附录C中报告了对正则化参数的敏感性分析,然后讨论了每个目标项的细节。
具有不确定自适应边界的监督目标
首先,具有不确定性自适应边界的监督目标迫使网络正确地将实例分配给以前见过的类,但控制学习该任务的速度,以便同时学习形成新的类。我们对
{
y
i
}
i
=
1
n
\{y_i\}_{i=1}^n
{yi}i=1n的标记数据使用分类注释,优化权重
W
W
W和骨干
θ
θ
θ。分类注释可以通过使用标准交叉熵(CE)损失作为监督目标来利用:
L
S
=
1
n
∑
z
i
∈
Z
l
−
log
e
W
y
i
T
⋅
z
i
e
W
y
i
T
⋅
z
i
+
∑
j
≠
i
e
W
y
j
T
⋅
z
i
,
(
2
)
\mathcal{L}_{\mathrm{S}}=\frac{1}{n}\sum_{z_{i}\in\mathcal{Z}_{l}}-\log\frac{e^{W_{y_{i}}^{T}\cdot z_{i}}}{e^{W_{y_{i}}^{T}\cdot z_{i}}+\sum_{j\neq i}e^{W_{y_{j}}^{T}\cdot z_{i}}},\quad(2)
LS=n1zi∈Zl∑−logeWyiT⋅zi+∑j=ieWyjT⋅zieWyiT⋅zi,(2)然而,在标记数据上使用标准交叉熵损失会在已知类和新类之间产生不平衡问题,即,已知类
C
s
C_s
Cs更新梯度,而新类
C
n
C_n
Cn不更新梯度。这可能导致为看到的类学习一个更大的分类器(Kang等人,2019),导致整个模型偏向于看到的类。为了克服这个问题,我们引入了一种不确定性自适应边界机制,并提出了一种归一化逻辑的方法。
一个关键的挑战是,由于有监督目标,已知类的学习速度更快,因此与新类相比,它们往往具有更小的类内方差(Liu et al, 2020)。成对目标通过对特征空间中的距离排序来生成未标记数据的伪标签,因此类间类内方差的不平衡将导致容易出错的伪标签。换句话说,来自新类的实例将被分配给已知类。为了减轻这种偏见,我们建议使用自适应边界机制来减小已知类别和新类别之间的类内方差差距。直观地说,在训练开始时,我们想要强制一个更大的负边际,以鼓励相对于新类,已知类的类内方差同样大。在接近训练结束时,当为新类形成聚类时,我们将边际项调整为接近0,以便模型可以充分利用标记数据,即目标归结为Eq.(2)中定义的标准交叉熵。我们建议使用不确定性捕获类内方差。因此,我们使用不确定性估计来调整边界,从而达到期望的行为——在早期的训练时期,不确定性很大,导致边界很大,而随着训练的进行,不确定性变小,导致边界变小。
其中,具有不确定性自适应边界机制的监督目标定义为:
L
S
=
1
n
∑
z
i
∈
Z
l
−
log
e
s
(
W
y
i
T
⋅
z
i
+
λ
u
ˉ
)
e
s
(
W
y
i
T
⋅
z
i
+
λ
u
ˉ
)
+
∑
j
≠
i
e
s
W
y
j
T
⋅
z
i
,
(3)
\mathcal{L}_{\mathrm{S}}=\frac{1}{n}\sum_{z_{i}\in\mathcal{Z}_{l}}-\log\frac{e^{s(W_{y_{i}}^{T}\cdot z_{i}+\lambda\bar{u})}}{e^{s(W_{y_{i}}^{T}\cdot z_{i}+\lambda\bar{u})}+\sum_{j\neq i}e^{sW_{y_{j}}^{T}\cdot z_{i}}},\text{(3)}
LS=n1zi∈Zl∑−loges(WyiT⋅zi+λuˉ)+∑j=iesWyjT⋅zies(WyiT⋅zi+λuˉ),(3)其中
u
ˉ
\bar{u}
uˉ是不确定性,
λ
λ
λ是定义其强度的正则化器。参数
s
s
s是控制交叉熵损失温度的附加缩放参数(Wang et al ., 2018)。为了估计不确定性
u
ˉ
\bar{u}
uˉ,我们依赖于从softmax函数的输出计算的未标记实例的置信度。在二进制设置中,
u
ˉ
=
1
∣
D
u
∣
∑
x
∈
D
u
V
a
r
(
Y
∣
X
=
x
)
=
1
∣
D
u
∣
∑
x
∈
D
u
P
r
(
Y
=
1
∣
X
)
⋅
P
r
(
Y
=
0
∣
X
)
{\bar{u}}={\frac{1}{|{\mathcal{D}}_{u}|}}\sum_{x\in{\mathcal{D}}_{u}}{\mathrm{Var}}(Y|X=x)={\frac{1}{|{\mathcal{D}}_{u}|}}\sum_{x\in{\mathcal{D}}_{u}}{\mathrm{Pr}}(Y=1|X)\cdot\mathrm{Pr}(Y=0|X)
uˉ=∣Du∣1∑x∈DuVar(Y∣X=x)=∣Du∣1∑x∈DuPr(Y=1∣X)⋅Pr(Y=0∣X),可以进一步近似为:
u
ˉ
=
1
∣
D
u
∣
∑
x
i
∈
D
u
1
−
max
k
Pr
(
Y
=
k
∣
X
=
x
i
)
,
(
4
)
\bar{u}=\frac{1}{|\mathcal{D}_{u}|}\sum_{x_{i}\in\mathcal{D}_{u}}1-\max_{k}\Pr(Y=k|X=x_{i}),\quad(4)
uˉ=∣Du∣1xi∈Du∑1−kmaxPr(Y=k∣X=xi),(4)最多是2的因数。这里,k遍历所有类。我们使用相同的公式作为多类别设置中群体不确定性的近似值,类似于(Cao等人,2020b)。
为了适当地调整边界,我们需要约束分类器的大小,因为分类器的不受约束的大小会对边界的调整产生负面影响。为了避免这个问题,我们对线性分类器的输入和权值进行归一化,即
z
i
=
z
i
∣
z
i
∣
z_{i}=\frac{z_{i}}{|z_{i}|}
zi=∣zi∣zi和
W
j
=
W
j
∣
W
j
∣
W_{j}=\frac{W_{j}}{|W_{j}|}
Wj=∣Wj∣Wj。
成对目标
成对目标学习预测成对实例之间的相似性,以便将来自同一类的实例分组在一起。这部分目标为未标记的数据生成伪标签来指导训练。ORCA通过不确定性自适应边界控制已知类和新类的类内方差,提高了伪标签的质量。
特别地,我们将聚类学习问题转化为两两相似性预测任务(Hsu et al, 2018;Chang et al, 2017)。给定标记的数据集
X
l
X_l
Xl和未标记的数据集
X
u
X_u
Xu,我们的目标是微调我们的主干
f
θ
f_θ
fθ,并学习一个由线性分类器
W
W
W参数化的相似性预测函数,以便来自同一类的实例被分组在一起。为了实现这一点,我们依赖于来自标记集和未标记集上生成的伪标签的基真注释。具体来说,对于有标签的集合,我们已经知道哪些对应该属于同一个类,因此我们可以使用真实标签。为了获得未标记集的伪标签,我们计算了一个小批量中所有对的特征表示
z
i
z_i
zi之间的余弦距离。然后我们对计算的距离进行排序,并为每个实例生成最相似邻居的伪标签。因此,对于mini-batch中的每个实例,我们只从最自信的正对中生成伪标签。对于小批量中的特征表示
Z
l
∪
Z
u
\mathcal{Z}_l\cup\mathcal{Z}_u
Zl∪Zu,我们将其最近的集合表示为
Z
l
′
∪
Z
u
′
\mathcal{Z}_l^{\prime}\cup\mathcal{Z}_u^{\prime}
Zl′∪Zu′。注意,
Z
l
′
\mathcal{Z}_l^{\prime}
Zl′总是正确的,因为它是使用真值标签生成的。ORCA中的成对目标定义为二元交叉熵损失(BCE)的一种修正形式:
L
P
=
1
m
+
n
∑
z
i
,
z
i
′
∈
−
log
⟨
σ
(
W
T
⋅
z
i
)
,
σ
(
W
T
⋅
z
i
′
)
⟩
.
(5)
\mathcal{L}_{\mathrm{P}}=\frac{1}{m+n}\sum_{z_{i},z_{i}^{\prime}\in}-\log\langle\sigma(W^{T}\cdot z_{i}),\sigma(W^{T}\cdot z_{i}^{\prime})\rangle.\text{(5)}
LP=m+n1zi,zi′∈∑−log⟨σ(WT⋅zi),σ(WT⋅zi′)⟩.(5)这里,
σ
σ
σ表示softmax函数,它将实例分配给一个已知的或新的类。对于标记的实例,我们使用真值注释来计算目标。对于未标记的实例,我们基于生成的伪标签计算目标。我们只考虑最自信的对来生成伪标签,因为我们发现伪标签中增加的噪声不利于聚类学习。不像(Hsu et al, 2018;Han et al ., 2020;Chang等人,2017)我们只考虑积极的配对,因为我们发现在我们的目标中包括消极的配对对学习没有好处(消极的配对很容易识别)。我们只有正配对的成对目标与(Van Gansbeke et al, 2020)有关。然而,我们以在线方式更新距离以及正对,从而在训练过程中受益于改进的特征表示。
正则项
最后,正则化项避免了将所有实例分配给同一个类的平凡解决方案。在训练的早期阶段,网络可能退化为一个平凡的解决方案,其中所有实例被分配到单个类,即 ∣ C u ∣ = 1 |C_u| = 1 ∣Cu∣=1。我们通过引入一个KullbackLeibler (KL)散度项来阻止这种解决方案,该散度项使 P r ( y ∣ x ∈ D l ∪ D u ) \mathrm{Pr}(y|x\in{\mathcal{D}}_{l}\cup\mathcal{D}_{u}) Pr(y∣x∈Dl∪Du)正则化,使其接近标记 y y y的先验概率分布 P P P: R = K L ( 1 m + n ∑ z i ∈ Z l ∪ Z u σ ( W T ⋅ z i ) ∥ P ( y ) ) , ( 6 ) \mathcal{R}=KL\Big(\frac{1}{m+n}\sum_{z_{i}\in\mathcal{Z}_{l}\cup\mathcal{Z}_{u}}\sigma(W^{T}\cdot z_{i})\parallel\mathcal{P}(y)\Big),\quad(6) R=KL(m+n1zi∈Zl∪Zu∑σ(WT⋅zi)∥P(y)),(6)式中 σ σ σ为softmax函数。由于知道先验分布在大多数应用中是一个强有力的假设,我们在所有的实验中都用最大熵正则化来正则化模型。最大熵正则化已用于基于伪标记的SSL (Arazo等人,2020)、深度聚类方法(Van Gansbeke等人,2020)和噪声标签训练(Tanaka等人,2018),以防止类分布过于平坦。在实验中,我们表明,即使在数据分布不平衡的情况下,该项也不会对ORCA的性能产生负面影响。
自监督预训练
我们考虑有和没有自我监督预训练的ORCA(以及所有基线)。在图像数据集上,我们使用自监督学习预训练ORCA和基线。自监督学习制定了一个借口/辅助任务,不需要任何人工管理,可以很容易地应用于标记和未标记的数据。借口任务引导模型以完全无监督的方式学习有意义的表征。特别是,我们依赖于SimCLR方法(Chen等人,2020a)。我们用一个借口目标在整个数据集 D l ∪ D u D_{l}\cup\mathcal{D}_{u} Dl∪Du上预训练主干 f θ f_θ fθ。在训练过程中,我们冻结骨干 f θ f_θ fθ的第一层,并更新其最后一层和分类器 w w w。我们对所有基线采用相同的SimCLR预训练协议。我们还考虑了一个没有预训练的设置,其中对于单元格类型注释任务,我们不使用任何借口任务,ORCA从随机初始化的权重开始。此外,我们在附录C中报告了不同预训练策略的结果,包括仅在数据 D l D_l Dl的标记子集上进行预训练以及用RotationNet替换SimCLR (Kanezaki et al ., 2018)。
参考
Cao, Kaidi et al. “Open-World Semi-Supervised Learning.” ArXiv abs/2102.03526 (2021): n. pag.















 2113
2113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









