






方法
目标是解决单域泛化问题:模型仅在一个源域
S
S
S中训练,但要求在许多未见过的目标域
T
T
T上泛化良好。受到许多最近成就的启发[36,56,24],这个具有挑战性的问题的一个有希望的解决方案是利用对抗训练[11,49]。关键思想是学习一个抗分布外扰动的鲁棒模型。更具体地说,我们可以通过解决最坏情况问题来学习模型[44]:
min
θ
sup
T
:
D
(
S
,
T
)
≤
ρ
E
[
L
t
a
s
k
(
θ
;
T
)
]
,
(
1
)
\min_{\theta}\sup_{\mathcal{T}:D(\mathcal{S},\mathcal{T})\leq\rho}\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{T})], (1)
θminT:D(S,T)≤ρsupE[Ltask(θ;T)],(1)其中
D
D
D是测量域距离的相似性度量,
ρ
ρ
ρ表示
S
S
S和
T
T
T之间的最大域差异。θ是根据任务特定目标函数
L
t
a
s
k
L_{task}
Ltask优化的模型参数。理解:(
min
θ
\min_{\theta}
minθ) 表示我们要最小化的是关于参数 (
θ
\theta
θ) 的某个函数。(
sup
T
:
D
(
S
,
T
)
≤
ρ
\sup_{\mathcal{T}:D(\mathcal{S},\mathcal{T})\leq\rho}
supT:D(S,T)≤ρ) 表示在所有满足某个条件的训练集 (
T
\mathcal{T}
T) 上取最大值。这里的(
D
(
S
,
T
)
D(\mathcal{S},\mathcal{T})
D(S,T)) 表示两个数据分布之间的距离,而 (
ρ
\rho
ρ) 是一个给定的阈值。(
E
[
L
t
a
s
k
(
θ
;
T
)
]
\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{T})]
E[Ltask(θ;T)]) 表示在训练集 (
T
\mathcal{T}
T) 上关于参数 (
θ
\theta
θ) 的某个损失函数的期望值。总的来说这个公式的意义是:要找到能够最小化在所有满足某种数据分布距离约束条件下的训练集上的某个损失函数的期望值的参数 (
θ
\theta
θ)。这种形式的优化问题在对抗性训练或者用于泛化保证时可能会经常出现。在这里,我们关注使用交叉熵损失的分类问题:
L
t
a
s
k
(
y
,
y
^
)
=
−
∑
i
y
i
log
(
y
^
i
)
,
(
2
)
\mathcal{L}_{\mathrm{task}}(\mathbf{y},\hat{\mathbf{y}})=-\sum_{i}y_{i}\log(\hat{y}_{i}), (2)
Ltask(y,y^)=−i∑yilog(y^i),(2)其中
y
^
\mathbf{\hat{y}}
y^为模型的softmax输出;
y
\mathbf{y}
y是表示真类的one-hot向量;
y
i
y_i
yi和
y
^
i
\hat{y}_i
y^i分别表示
y
y
y和
y
^
\hat{y}
y^的第
i
i
i维。
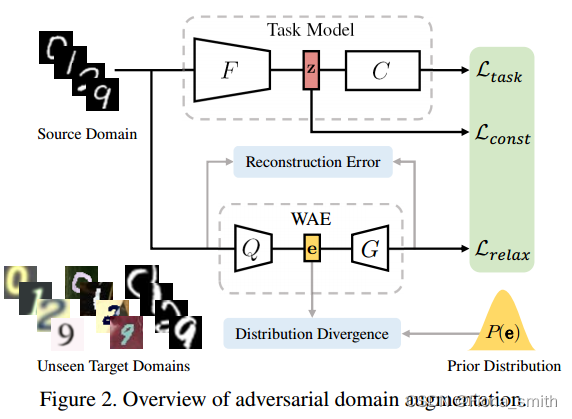
根据最坏情况公式(1),我们提出了一种新的方法,基于元学习的对抗域增强(M-ADA),用于单域泛化。图2概述了我们的方法。在第3.1节中,我们通过利用对抗性训练来增强源域,创建了“虚构”但“具有挑战性”的域。在Wasserstein自动编码器(WAE)的帮助下,任务模型从域增强中学习,这放宽了第3.2节中的最坏情况约束。我们在如3.3节所述的学会学习的框架下组织任务模型和WAE的联合训练,以及领域增强过程。最后,在第四节给出了最坏情况保证的理论证明。
对抗性域增强
我们的目标是从源域创建读个增强域。增强域要求与源域在分布上不同,以模拟不可见的域。此外,为避免增强域发散,还应满足式(1)中定义的最坏情况保证。为了实现这一目标,我们提出了对抗性域增强。
为了实现这一目标,我们提出了对抗性域增强。我们的模型由任务模型和WAE组成,如图2所示。在图2中,任务模型由特征提取器
F
:
X
→
Z
F: X →Z
F:X→Z映射图像从输入空间到嵌入空间,和一个分类器
C
:
Z
→
Y
C: Z →Y
C:Z→Y用于从嵌入空间预测标签。设
z
z
z表示由
z
=
F
(
x
)
z = F(x)
z=F(x)得到的
x
x
x的潜在表示。总体损失函数的表达式为:
L
A
D
A
=
L
t
a
s
k
(
θ
;
x
)
⏟
Classification
−
α
L
c
o
n
s
t
(
θ
;
z
)
⏟
Constraint
+
β
L
r
e
l
a
x
(
ψ
;
x
)
⏟
Relaxation
,
(
3
)
\mathcal{L}_{\mathrm{ADA}}=\underbrace{\mathcal{L}_{\mathrm{task}}(\theta;\mathbf{x})}_{\text{Classification}}-\alpha\underbrace{\mathcal{L}_{\mathrm{const}}(\theta;\mathbf{z})}_{\text{Constraint}}+\beta\underbrace{\mathcal{L}_{\mathrm{relax}}(\psi;\mathbf{x})}_{\text{Relaxation}}, (3)
LADA=Classification
Ltask(θ;x)−αConstraint
Lconst(θ;z)+βRelaxation
Lrelax(ψ;x),(3)其中
L
t
a
s
k
\mathcal{L}_{\mathrm{task}}
Ltask为Eq.(2)中定义的分类损失,
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst为Eq.(1)中定义的最坏情况保证,
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax为Eq.(7)中定义的大域传输保证,
ψ
\psi
ψ为WAE参数。
α
α
α和
β
β
β是平衡
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst和
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax的两个超参数。
给定目标函数
L
A
D
A
\mathcal{L}_{\mathrm{ADA}}
LADA,我们采用迭代方法在增强域
S
+
S ^+
S+中生成对抗样本
x
+
x ^+
x+:
x
t
+
1
+
←
x
t
+
+
γ
∇
x
t
+
L
A
D
A
(
θ
,
ψ
;
x
t
+
,
z
t
+
)
,
(
4
)
\mathbf{x}_{t+1}^+\leftarrow\mathbf{x}_t^++\gamma\nabla_{\mathbf{x}_t^+}\mathcal{L}_{\mathrm{ADA}}(\theta,\psi;\mathbf{x}_t^+,\mathbf{z}_t^+), (4)
xt+1+←xt++γ∇xt+LADA(θ,ψ;xt+,zt+),(4)式中,
γ
γ
γ为梯度上升的学习率。需要少量的迭代来产生足够的扰动并创建理想的对抗样本。
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst对对抗样本施加语义一致性约束,使得
S
+
S^ +
S+满足
D
(
S
;
S
+
)
≤
ρ
D (S;S ^+)≤ρ
D(S;S+)≤ρ。特别地,我们根据[56]测量嵌入空间中
S
+
S ^+
S+与
S
S
S之间的Wasserstein距离:
L
c
o
n
s
t
=
1
2
∥
z
−
z
+
∥
2
2
+
∞
⋅
1
{
y
≠
y
+
}
,
(
5
)
\mathcal{L}_{\mathrm{const}}=\frac{1}{2}\|\mathbf{z}-\mathbf{z}^{+}\|_{2}^{2}+\infty\cdot\mathbf{1}\left\{\mathbf{y}\neq\mathbf{y}^{+}\right\}, (5)
Lconst=21∥z−z+∥22+∞⋅1{y=y+},(5)其中
1
{
⋅
}
1\{·\}
1{⋅}为0-1指示函数,如果
x
+
x^+
x+的类标号不同于
x
x
x,则
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst为1。直观上,
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst控制着以Wasserstein距离度量的源域外的泛化能力[54]。然而,
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst产生有限的域迁移,因为它严重限制了样本和它们的扰动之间的语义距离。因此,提出
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax来放松语义一致性约束,创建大域传输。
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax的实现将在第3.2节中讨论。
Wasserstein距离约束的松弛
直观地说,我们期望增强域
S
+
S^+
S+与源域
S
S
S有很大的不同。换句话说,我们希望最大化
S
+
S^+
S+与
S
S
S之间的域差异。然而,语义一致性约束
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst将严重限制从
S
S
S到$
S
+
S^+
S+的域传输,这对生成理想的
S
+
S^+
S+提出了新的挑战。为了解决这个问题,我们使用
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
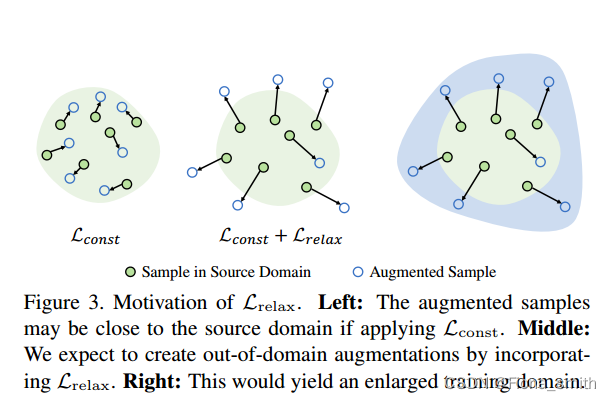
Lrelax来鼓励分布外域扩展。我们在图3中说明了这个想法。
具体来说,我们使用Wasserstein自动编码器(WAEs)[52]来实现 L r e l a x {\mathcal{L}_{\mathrm{relax}}} Lrelax。设 V V V表示 ψ \psi ψ参数化的WAE。 V V V由编码器 Q ( e ∣ x ) Q(e|x) Q(e∣x)和解码器 G ( x ∣ e ) G(x|e) G(x∣e)组成,其中 x x x和 e e e分别表示输入和瓶颈嵌入。此外,我们使用距离度量 D e D_e De来测量 Q ( x ) Q(x) Q(x)与先验分布 P ( e ) P(e) P(e)之间的散度,这可以实现为最大平均差异(MMD)或GAN[10]。我们可以通过优化来学习 V V V:
min
ψ
[
∥
G
(
Q
(
x
)
)
−
x
∥
2
+
λ
D
e
(
Q
(
x
)
,
P
(
e
)
)
]
,
(
6
)
\min_\psi[\|G(Q(\mathbf{x}))-\mathbf{x}\|^2+\lambda\mathcal{D}_\mathbf{e}(Q(\mathbf{x}),P(\mathbf{e}))], (6)
ψmin[∥G(Q(x))−x∥2+λDe(Q(x),P(e))],(6)其中
λ
λ
λ是超参数。在源域
S
S
S上离线预训练
V
V
V后,我们将其冻结并最大化域增强重建误差
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax:
L
r
e
l
a
x
=
∥
x
+
−
V
(
x
+
)
∥
2
.
(
7
)
\mathcal{L}_{\mathrm{relax}}=\|\mathbf{x}^+-V(\mathbf{x}^+)\|^2. (7)
Lrelax=∥x+−V(x+)∥2.(7)与Vanilla或Variation Auto-Encoders不同[45],WAEs使用Wasserstein度量来度量输入和重建之间的分布距离。因此,预训练的
V
V
V可以更好地捕获源域的分布,最大化
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax会产生大的域传输。在附录中还提供了不同
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax的比较。
在这项工作中,
V
V
V作为一个one-class鉴别器来区分增强是否在源域之外,这与传统gan的鉴别器有很大的不同[10]。它也不同于领域自适应中广泛使用的领域分类器[24],因为只有一个源领域可用。因此,使用
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax和
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst一起在输入空间“推走”
S
+
S^+
S+,同时在嵌入空间“拉回”
S
+
S^+
S+。在第4节中,我们展示了
L
r
e
l
a
x
{\mathcal{L}_{\mathrm{relax}}}
Lrelax和
L
c
o
n
s
t
\mathcal{L}_{\mathrm{const}}
Lconst分别是在输入空间和嵌入空间中定义的两个Wasserstein距离度量的派生。
元学习单域泛化
为了有效地组织源域
S
S
S和增强域
S
+
S^+
S+上的模型训练,我们利用元学习方案来训练单个模型。为了模拟源域
S
S
S和目标域
T
T
T之间的真实域位移,在每次学习迭代中,我们对源域
S
S
S进行元训练,并对所有增强域
S
+
S^+
S+进行元测试。因此,在多次迭代之后,该模型在评估过程中有望在最终目标域
T
T
T上实现良好的泛化。
正式地,提出的基于元学习的对抗领域增强(M-ADA)方法在训练过程中的每次迭代中由三个部分组成:元训练、元测试和元更新。在元训练中,
L
t
a
s
k
\mathcal{L}_{\mathrm{task}}
Ltask在源域
S
S
S的样本上计算,模型参数
θ
θ
θ通过一个或多个梯度步更新,学习率为
η
η
η:
θ
^
←
θ
−
η
∇
θ
L
t
a
s
k
(
θ
;
S
)
.
(
8
)
\hat{\theta}\leftarrow\theta-\eta\nabla_{\theta}\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{S}). (8)
θ^←θ−η∇θLtask(θ;S).(8)然后计算
L
t
a
s
k
(
θ
^
;
S
+
k
)
\mathcal{L}_{\mathrm{task}}(\hat{\theta};\mathcal{S+k})
Ltask(θ^;S+k)在元测试中每个增强域
S
+
k
S + k
S+k上。最后,在meta-update中,我们通过同时优化meta-train和meta-test的组合损失计算的梯度来更新
θ
θ
θ:
θ
←
θ
−
η
∇
θ
[
L
t
a
s
k
(
θ
;
S
)
+
∑
k
=
1
K
L
t
a
s
k
(
θ
^
;
S
k
+
)
]
,
(
9
)
\theta\leftarrow\theta-\eta\nabla_\theta[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{S})+\sum_{k=1}^K\mathcal{L}_{\mathrm{task}}(\hat{\theta};\mathcal{S}_k^+)], (9)
θ←θ−η∇θ[Ltask(θ;S)+k=1∑KLtask(θ^;Sk+)],(9)
K
K
K是增广域的个数

整个训练流程如表1所示。我们的方法有以下优点。首先,与之前学习一系列集成模型的工作[56]相比,我们的方法实现了单个模型的效率。在第5.4节中,我们证明M-ADA在内存、速度和准确性方面略微优于[56]。其次,元学习方案为学习模型的快速适应做好准备:一个或少量的梯度步骤将在新的目标域上产生改进的行为。这使M-ADA能够进行第5.5节所示的少量域适应。
理论的理解
我们提供了一个详细的理论分析所提出的对抗域增强。具体地说,我们证明了Eq.(3)中定义的整体损失函数是一个松弛的最坏情况问题的直接推导。
让
c
:
Z
×
Z
→
R
+
∪
{
∞
}
c : \mathcal{Z}\times\mathcal{Z} \to \mathbb{R}_{+} \cup \{\infty\}
c:Z×Z→R+∪{∞}为对手在嵌入空间中将
z
z
z扰动到
z
+
z^+
z+的“代价”。让
d
:
X
×
X
→
R
+
∪
{
∞
}
d : \mathcal{X} \times \mathcal{X} \to \mathbb{R}_{+} \cup \{\infty\}
d:X×X→R+∪{∞}是对手在输入空间中将
x
x
x扰动为
x
+
x^+
x+的“代价”。
S
S
S和
S
+
S^+
S+之间的Wasserstein距离可以表示为:
W
c
(
S
,
S
+
)
:
=
inf
M
z
∈
Π
(
S
,
S
+
)
E
M
z
[
c
(
z
,
z
+
)
]
W_{c}(\mathcal{S},\mathcal{S}^{+}):=\operatorname*{inf}_{M_{\mathbf{z}}\in\Pi(\mathcal{S},\mathcal{S}^{+})}\mathbb{E}_{M_{\mathbf{z}}}\left[c\left(\mathbf{z},\mathbf{z}^{+}\right)\right]
Wc(S,S+):=infMz∈Π(S,S+)EMz[c(z,z+)]和
W
d
(
S
,
S
+
)
:
=
inf
M
x
∈
Π
(
S
,
S
+
)
E
M
x
[
d
(
x
,
x
+
)
]
W_{d}(\mathcal{S},\mathcal{S}^{+}):=\operatorname*{inf}_{M_{\mathbf{x}}\in\Pi(\mathcal{S},\mathcal{S}^{+})}\mathbb{E}_{M_{\mathbf{x}}}\left[d\left(\mathbf{x},\mathbf{x}^{+}\right)\right]
Wd(S,S+):=infMx∈Π(S,S+)EMx[d(x,x+)],其中
M
z
M_z
Mz和
M
x
M_x
Mx分别是嵌入空间和输入空间的测度;
Π
(
S
,
S
+
)
\Pi(\mathcal{S},\mathcal{S}^{+})
Π(S,S+)是
S
S
S和
S
+
S^+
S+的联合分布。则松弛最坏情况问题可表示为:
θ
∗
=
min
θ
sup
S
+
∈
D
E
[
L
t
a
s
k
(
θ
;
S
+
)
]
,
(
10
)
\theta^*=\min_\theta\sup_{\mathcal{S}^+\in\mathcal{D}}\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathcal{S}^+)], (10)
θ∗=θminS+∈DsupE[Ltask(θ;S+)],(10)
式中
D
=
{
S
+
:
W
c
(
S
,
S
+
)
≤
ρ
,
W
d
(
S
,
S
+
)
≥
η
}
\mathcal{D}=\{\mathcal{S}^{+}:W_{c}(\mathcal{S},\mathcal{S}^{+})\leq\rho,W_{d}(\mathcal{S},\mathcal{S}^{+})\geq\eta\}
D={S+:Wc(S,S+)≤ρ,Wd(S,S+)≥η}。我们注意到,在Wasserstein距离测度
W
c
W_c
Wc和
W
d
W_d
Wd下,
D
D
D覆盖了一个鲁棒区域,该区域在嵌入空间中距离
S
S
S的
ρ
ρ
ρ距离内,在输入空间中距离
S
S
S的
η
η
η距离内。
对于深度神经网络,Eq.(10)是难以处理的任意
ρ
ρ
ρ和
η
η
η。因此,我们考虑其定罚参数
α
≥
0
α≥0
α≥0和
β
≥
0
β≥0
β≥0时的拉格朗日松弛:
min
θ
{
sup
S
+
{
E
[
L
t
a
s
k
(
θ
;
x
+
)
]
−
W
c
,
d
}
=
E
[
ϕ
α
,
β
(
θ
,
ψ
;
x
)
]
}
,
\min_\theta\{\sup_{\mathcal{S}^+}\left\{\mathbb{E}[\mathcal{L}_{\mathrm{task}}(\theta;\mathbf{x}^+)]-W_{c,d}\right\}=\mathbb{E}[\phi_{\alpha,\beta}(\theta,\psi;\mathbf{x})]\},
θmin{S+sup{E[Ltask(θ;x+)]−Wc,d}=E[ϕα,β(θ,ψ;x)]},
我们有
W
c
,
d
(
S
,
S
+
)
=
α
W
c
(
S
,
S
+
)
−
β
W
d
(
S
,
S
+
)
,
ϕ
α
,
β
(
θ
,
ψ
;
x
)
=
sup
x
+
{
L
t
a
s
k
(
θ
;
x
+
)
−
L
c
,
d
}
W_{c,d}(\mathcal{S},\mathcal{S}^{+})=\alpha W_{c}(\mathcal{S},\mathcal{S}^{+})-\beta W_{d}(\mathcal{S},\mathcal{S}^{+}),\phi_{\alpha,\beta}(\theta,\psi;\mathbf{x})=\sup_{\mathbf{x}^{+}}\{\mathcal{L}_{\mathrm{task}}(\theta;\mathbf{x}^{+})-\mathcal{L}_{c,d}\}
Wc,d(S,S+)=αWc(S,S+)−βWd(S,S+),ϕα,β(θ,ψ;x)=supx+{Ltask(θ;x+)−Lc,d}和
L
c
,
d
=
α
c
(
z
,
z
+
)
−
β
d
(
x
,
x
+
)
\mathcal{L}_{c,d}=\alpha c (\mathbf{z},\mathbf{z}^{+})-\beta d (\mathbf{x},\mathbf{x}^{+})
Lc,d=αc(z,z+)−βd(x,x+)。因此,将Eq.(10)中的问题转化为最小化稳健代理
ϕ
α
,
β
\phi_{α,β}
ϕα,β。
根据[44],
ϕ
α
\phi_{α}
ϕα关于
θ
θ
θ是光滑的,如果
α
α
α足够大,且Lipschitzian光滑假设成立,则
ϕ
α
\phi_{α}
ϕα是光滑的。由于
ψ
\psi
ψ和
θ
θ
θ相互独立,
ϕ
α
,
β
\phi_{α,β}
ϕα,β仍然关于
θ
θ
θ是光滑的。梯度可以计算为:
∇
θ
ϕ
α
,
β
(
θ
,
ψ
;
x
)
=
∇
θ
L
t
a
s
k
(
θ
;
x
⋆
(
x
,
θ
,
ψ
)
)
,
\nabla_\theta\phi_{\alpha,\beta}(\theta,\psi;\mathbf{x})=\nabla_\theta\mathcal{L}_\mathrm{task}(\theta;\mathbf{x}^\star(\mathbf{x},\theta,\psi)),
∇θϕα,β(θ,ψ;x)=∇θLtask(θ;x⋆(x,θ,ψ)),
其中
x
⋆
(
x
,
θ
,
ψ
)
=
arg
max
x
+
[
L
t
a
s
k
(
θ
;
x
+
)
−
L
c
,
d
]
=
arg
max
x
+
L
A
D
A
(
θ
,
ψ
;
x
+
,
z
+
)
\mathbf{x}^{\star}(\mathbf{x},\theta,\psi) = \arg\operatorname*{max}_{\mathbf{x}^{+}}[\mathcal{L}_{\mathrm{task}}(\theta;\mathbf{x}^{+})-\mathcal{L}_{c,d}] =\arg\max_{\mathbf{x}^{+}}\mathcal{L}_{\mathrm{ADA}}(\theta,\psi;\mathbf{x}^{+},\mathbf{z}^{+})
x⋆(x,θ,ψ)=argmaxx+[Ltask(θ;x+)−Lc,d]=argmaxx+LADA(θ,ψ;x+,z+)
,即公式(3)中定义的对抗性扰动。















 5010
5010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









