







sql的基本操作及方法使用
注: 在spark启动的cmd客户端,sc表示(RDD):sparkContext spark(Sql)表示: sparkSession
方法
spark.read:读取指定文件
write.save: 保存文件
format: 保存为指定格式或读取指定格式
show: 进行展示数据
createTempView: 创建临时视图
createOrReplaceTempView:创建临时视图,会替换掉相同名字的视图
createOrReplaceGlobalTempView:创建的临时视图,作用域为Session, 如果想要使用全局的,就需要用此方法创建,访问时需要在表的名字前加上前缀: global_temp.test
DSL语言
介绍:主要是将sql的写法写成使用对象.方法的方式来进行替代
一些简单的方法:
select(): 查询
filter(): 过滤
groupBy(): 分组
count(): 求个数
…等等非常多
注意: 当需要字段进行计算时,需要加上$"age"或者 单引号+字段名 (如:‘age’)的方式来进行计算,但是在idea中,需要先导入sparkSession的隐式转换对象 import spark.implicits._
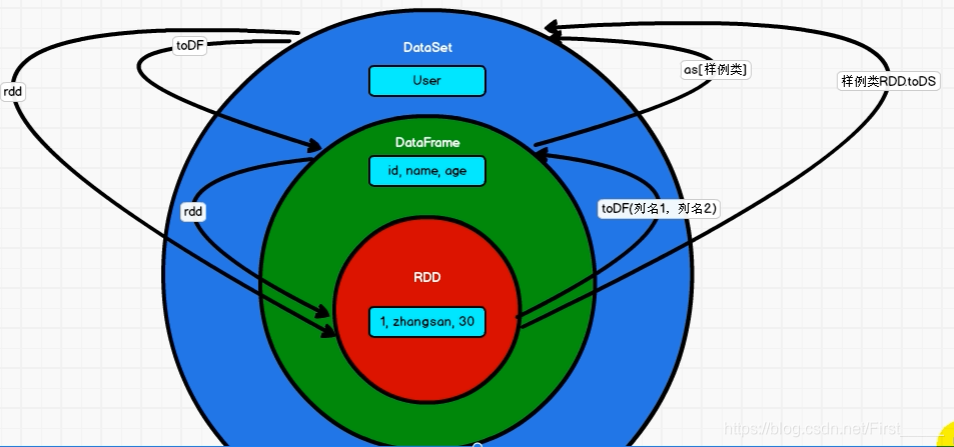
rdd丶DataFrame和DataSet之间的转换
文字关系说明:
rdd: 是spark进行操作的三大数据结构之一
DataFrame: 给数据添加上列名
DataSet : 强类型的, 给数据添加上类型和名字, 调用的时候更加的方便
转换关系图解:
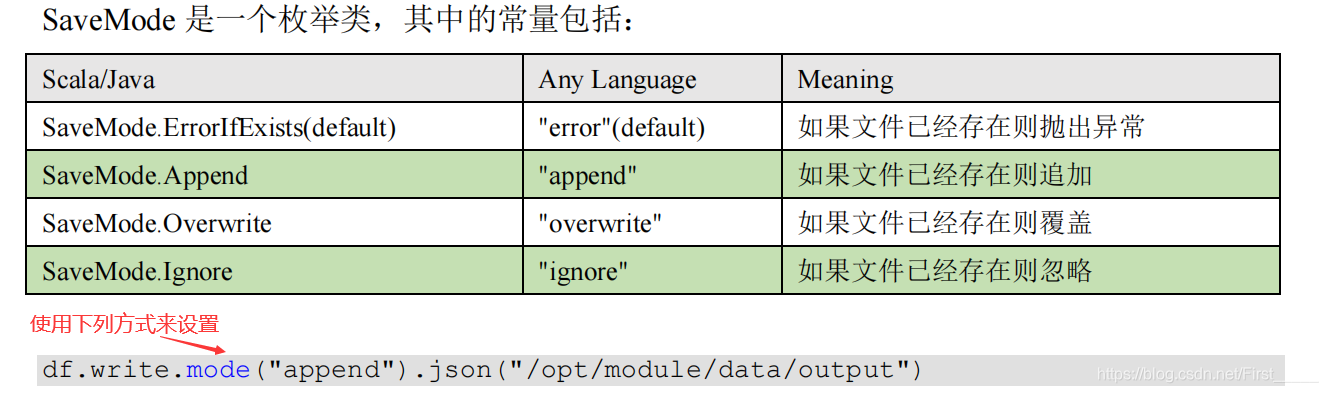
设置保存文件的级别
连接mysql(在idea中)
private val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark_sql")
//创建sql 环境对象
private val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
private val df: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://hadoop202:3306/test")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "testTable1")
.load()
df.show()
//关闭资源
spark.stop()
连接外置hive
在idea中
- 先将hive-site.xml复制到idea中
- 导入依赖
<dependencies>
<!--导入spark core 依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!--yarn集群依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!--Sparksql的依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!--导入hive所需依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!--3.0版本可以,其他的不行-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
- idea中代码
private val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark_sql")
//创建sql 环境对象
private val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("show tables").show()
//关闭资
spark.stop()
注意:
- 在开发工具中创建数据库默认是在本地仓库,
通过参数修改数据库仓库的地址:
config(“spark.sql.warehouse.dir”, “hdfs://linux1:8020/user/hive/warehouse”) - 可能出现权限问题:将
System.setProperty("HADOOP_USER_NAME", "root")放在最前面解决问题
在客户端中连接hive
前提条件:
- Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
- 把 Mysql 的驱动 copy 到 jars/目录下
- 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
- 重启 spark-shell
其他方式直接执行SQL语句(都是直接类似于hive窗口的那种模式):
第一种
bin/spark-sql
第二种
- Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
- 把 Mysql 的驱动 copy 到 jars/目录下
- 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
- 启动 Thrift Server:sbin/start-thriftserver.sh
- 使用 beeline 连接 Thrift Server: bin/beeline -u jdbc:hive2://hadoop202:10000 -n 密码
自定义函数
UDF: 普通函数
spark为SparkSession对象
spark.udf.register("prefix",(name:String) => {
"NAME:"+name
})
UDAF: 自定义聚合函数
package com.dxy.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, Row, SparkSession, functions}
object SparkSql03_UDAF2 extends App {
private val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark_sql")
//创建sql 环境对象
private val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 注册自定义聚合函数 强类型
spark.udf.register("myAvg",functions.udaf(new MyAvg()))
val df: DataFrame = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.sql("select myAvg(age) from user").show()
//关闭资源
spark.stop()
// 创建自定义聚合函数 需求: 求出平均值
//org.apache.spark.sql.expressions.Aggregator
// 样例类
case class Buff(var total:Long, var count:Long)
class MyAvg extends Aggregator[Long,Buff,Long]{
//初始值
override def zero: Buff = {
Buff(0,0)
}
// 缓冲区进行计算
override def reduce(b: Buff, a: Long): Buff = {
b.total+= a
b.count+=1
b
}
//合并
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total+=b2.total
b1.count+=b2.count
b1
}
//最终的运算
override def finish(reduction: Buff): Long = {
reduction.total/reduction.count
}
//固定格式, 自定义的话就使用Encoders.product 不是自定义的话就scala类型
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









