






一、Selenium简介
Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
适用于自动化测试,js动态爬虫(破解反爬虫)等领域。
二、Selenium组成
1)Selenium IDE:嵌入到Firefox浏览器中的一个插件,实现简单的浏览器操作录制与回放功能,主要用于快速创建BUG及重现脚本,可转化为多种语言
2)Selenium RC: 核心组件,支持多种不同语言编写自动化测试脚本,通过其服务器作为代理服务器去访问应用,达到测试的目的
3)Selenium WebDriver(重点):一个浏览器自动化框架,它接受命令并将它们发送到浏览器。它是通过特定于浏览器的驱动程序实现的。它直接与浏览器通信并对其进行控制。Selenium WebDriver支持各种编程语言,如Java、C# 、PHP、Python、Perl、Ruby
4)Selenium grid:测试辅助工具,用于做分布式测试,可以并行执行多个测试任务,提升测试效率。

三、Selenium特点
1)开源、免费
2)多浏览器支持:FireFox、Chrome、IE、Opera、Edge;
3)多平台支持:Linux、Windows、MAC;
4)多语言支持:Java、Python、Ruby、C#、JavaScript、C++;
5)对Web页面有良好的支持;
6)简单(API 简单)、灵活(用开发语言驱动);
7)支持分布式测试用例执行。
四、案例演示
一. java爬虫入门
1.找到本地谷歌版本,下载驱动包
找到谷歌页面的右上角的三个点->帮助->关于Google Chrome,然后就可以看到版本,作者的版本是101.0.4951.67,如图所示
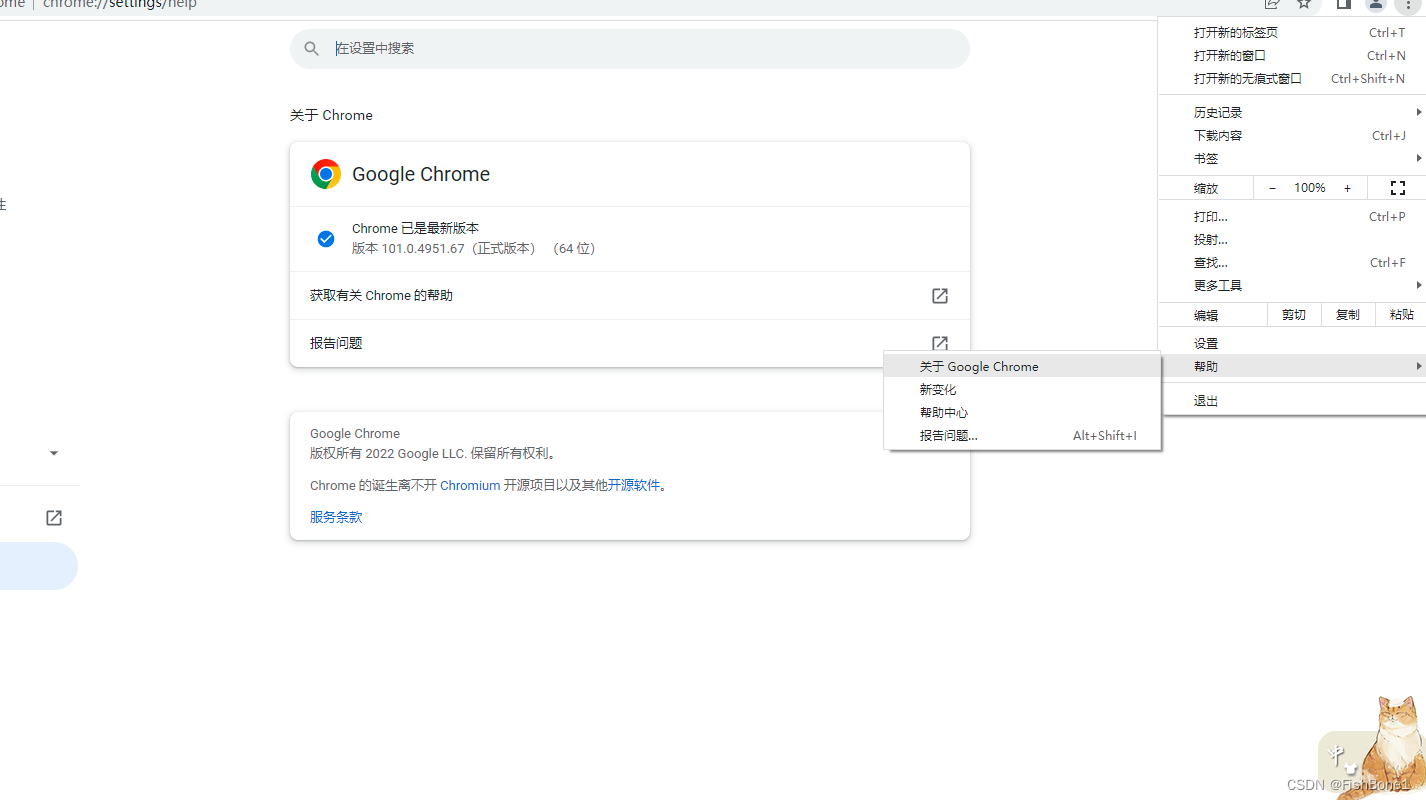
根据版本号到这个网站找到驱动包下载
http://chromedriver.storage.googleapis.com/index.html

点击所需的版本
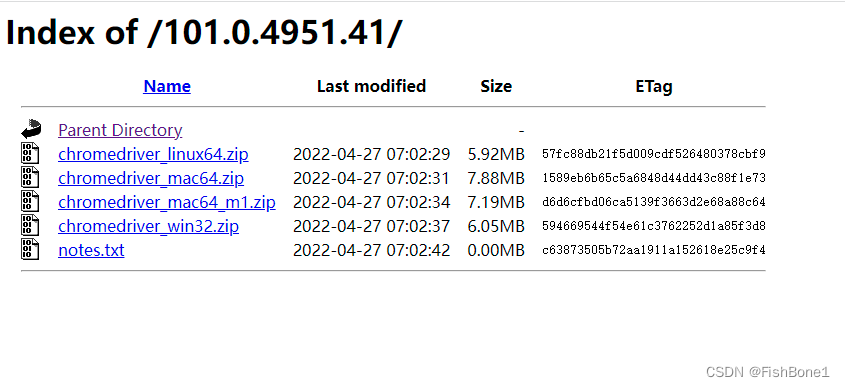
最后点击所需的驱动下载
2.用idea创建项目并导入依赖
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
3.入门
重点代码
//设置驱动
System.setProperty(“webdriver.chrome.driver”,“D:\chromedriver.exe”);
//创建驱动
WebDriver driver=new ChromeDriver();
//与将要爬取的网站建立连接
driver.get(“https://www.baidu.com”);
//关闭浏览器
driver.close();
//释放资源
driver.quit();
案例爬取资料的方式
1.元素选择方式
1)Class选择:driver.findElement(By.className("s_ipt"));
2)ID选择: driver.findElement(By.id("kw"));
3)name选择: driver.findElement(By.name("wd"));
4)tag选择: driver.findElements(By.tagName("input"));
5)link选择: driver.findElement(By.linkText("地图"));
6)Partial link选择(a标签文本内容模糊匹配):driver.findElement(By.partialLinkText("使用百"));
7)css选择器:driver.findElement(By.cssSelector("#kw"));
8)xpath选择:driver.findElement(By.xpath("//*[@id=\"kw\"]"));
2.获取单个元素:driver.findElement
3.获取多个元素:driver.findElements
4.输入内容:input.sendKeys("java");
5.元素点击:element.click();
6.获取元素属性:nextPageEle.getAttribute("class")
7.获取标签文本内容:titleEle.getText()
注:需要在前端页面控制台中找到相关的属性,然后爬取
案例代码
package com.zking;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class Demo1 {
public static void main(String[] args) {
//设置驱动
System.setProperty("webdriver.chrome.driver","D:\\Y1\\课堂代码和录屏\\VUE\\01.Selenium之入门\\chromedriver.exe");
//创建驱动
WebDriver driver=new ChromeDriver();
//与将要爬取的网站建立连接
driver.get("https://www.baidu.com");
//关闭浏览器
//driver.close();
//释放资源
//driver.quit();
// 示例一:Class选择:driver.findElement(By.className("s_ipt"));
/* List<WebElement> elements = driver.findElements(By.className("title-content-title"));
for (WebElement element : elements) {
System.out.println(element.getText());
}*/
// 示例二:ID选择: driver.findElement(By.id("kw"));
/*WebElement kw = driver.findElement(By.id("kw"));
System.out.println(kw.getAttribute("name"));*/
// 示例三:name选择: driver.findElement(By.name("wd"));
/*WebElement tn = driver.findElement(By.name("tn"));
System.out.println(tn.getAttribute("value"));*/
// 示例四:tag选择: driver.findElements(By.tagName("input"));
/*List<WebElement> input = driver.findElements(By.tagName("input"));
for (WebElement webElement : input) {
String value = webElement.getAttribute("value");
System.out.println(value);
}*/
// 示例五:link选择: driver.findElement(By.linkText("地图"));
/*List<WebElement> elements = driver.findElements(By.linkText("地图"));
for (WebElement element : elements) {
String text = element.getText();
System.out.println(text);
}*/
// 示例六:Partial link选择(a标签文本内容模糊匹配):driver.findElement(By.partialLinkText("使用百"));
// List<WebElement> elements = driver.findElements(By.partialLinkText("粉"));
// for (WebElement element : elements) {
// System.out.println(element.getText());
// }
// 示例七:css选择器:driver.findElement(By.cssSelector("#kw")); #hotsearch-content-wrapper > li:nth-child(2)
// List<WebElement> elements = driver.findElements(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(2)"));
for (WebElement element : elements) {
System.out.println(element.getText());
}
// 示例八:xpath选择:driver.findElement(By.xpath("//*[@id=\"kw\"]"));
// WebElement element = driver.findElement(By.xpath("//*[@id=\"kw\"]"));
// System.out.println(element.getAttribute("class"));
// 2.获取单个元素:driver.findElement
//
// 3.获取多个元素:driver.findElements
//
// 4.输入内容:input.sendKeys("java");
// WebElement kw = driver.findElement(By.id("kw"));
// kw.sendKeys("java");
// WebElement element = driver.findElement(By.id("su"));
// element.click();
}
}
4、Selenium爬取JD商品信息
案例代码(以爬取京东商品信息为案例)
package com.zking;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.util.List;
public class Demo2 {
public static void main(String[] args) {
//将驱动加载到Java的JVM虚拟机中
System.setProperty("webdriver.chrome.driver","D:\\Y1\\课堂代码和录屏\\VUE\\01.Selenium之入门\\chromedriver.exe");
/************************** 方式一:不打开浏览器 **************************/
//定义浏览器参数
// ChromeOptions chromeOptions = new ChromeOptions();
//设置不打开浏览器
// chromeOptions.addArguments("--headless");
//初始化驱动
// WebDriver driver = new ChromeDriver(chromeOptions);
/************************** 方式二:打开浏览器 **************************/
//初始化驱动
WebDriver driver = new ChromeDriver();
driver.get("https://www.jd.com/");
//查找jd网站中的首页搜索栏
WebElement key = driver.findElement(By.id("key"));
key.sendKeys("戒指");
//获取jd网站的查询按钮并且完成点击事件
WebElement element = driver.findElement(By.cssSelector("button.button"));
element.click();
//休眠3秒
sleep(3);
//设置滚动条移动到最下面
((JavascriptExecutor) driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
sleep(2);
//查询页面中的所有商品li标签
List<WebElement> elements = driver.findElements(By.xpath("//*[@id=\"J_goodsList\"]/ul/li"));
for (WebElement webElement : elements) {
String price = webElement.findElement(By.className("p-price")).getText();
String name = webElement.findElement(By.className("p-name")).getText();
System.out.println("【"+price+"】-"+name);
}
}
public static void sleep(int num){
try {
Thread.sleep(num*1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
爬取数据的效果图

5、Selenium爬取图片
案例代码
package com.zking;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.*;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class Demo3 {
//定义驱动
public static WebDriver driver=null;
//定义list集合,用于储存爬取数据中的图片路径
public static List<String> imgs=new ArrayList<>();
static {
//将驱动加载到Java的JVM虚拟机中
System.setProperty("webdriver.chrome.driver","D:\\Y1\\课堂代码和录屏\\VUE\\01.Selenium之入门\\chromedriver.exe");
//初始化驱动
driver = new ChromeDriver();
}
public static void getImg(){
driver.get("http://www.gaoimg.com/");
//定义爬取的节点
List<WebElement> elements = driver.findElements(By.xpath("/html/body/div[4]/div/div/div[2]/dl/dt/a/img"));
for (WebElement element:elements) {
String src = element.getAttribute("src");
imgs.add(src);
}
}
public static void saveImg(){
try {
for (String img : imgs) {
//创建URL对象,并设置图片的下载路径
URL url=new URL(img);
//打开图片数据输入流
InputStream is=url.openStream();
//定义图片存储路径
String path="D:\\Y1\\课堂代码和录屏\\VUE\\02.Selenium之实战案例\\图片\\"+ UUID.randomUUID().toString().replace("-","")+".png";
//定义图片输出流
OutputStream out=new FileOutputStream(new File(path));
//定义读取长度
int len=0;
//定义byte数组每次读取多少字节
byte[] bytes=new byte[1024];
//循环读取
while ((len=is.read(bytes))!=-1){
//写流
out.write(bytes);
}
//关闭流
is.close();
out.close();
sleep(2);
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void sleep(int num){
try {
Thread.sleep(num*1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
//爬取图片路径
getImg();
//循环打印图片路径
for (String img : imgs) {
System.out.println(img);
}
//保存图片
saveImg();
} catch (Exception e) {
e.printStackTrace();
} finally {
//一定要记得下载完图片之后释放资源
if(null!=driver)
driver.quit();
}
}
}
效果图
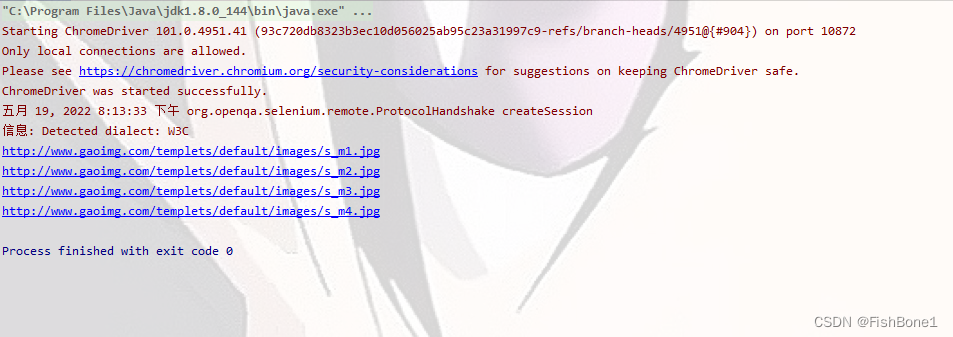 爬取的图片
爬取的图片
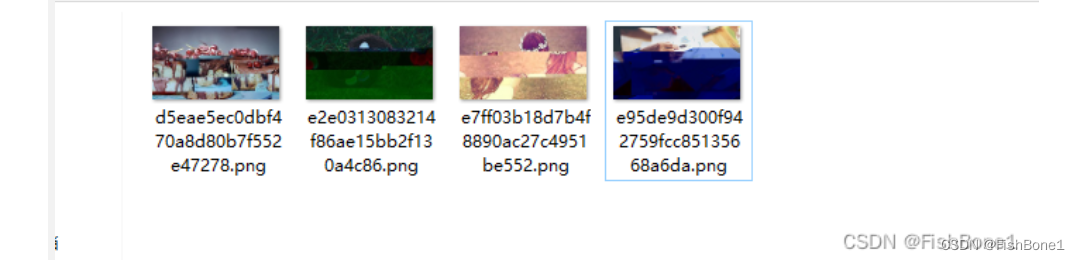
在这里插入图片描述
注意看作者在代码中写的注释,有的网站不能爬取图片,但是基本上都能爬取文字,这篇文章主要是入门,想要深入学习的同学可以去查找其他的相关资料,感谢同学们的阅读(* ̄︶ ̄)















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}