







概述
Spark为结构化数据处理提供 的模块Spark sql的编程模块
通过DataFrame来操作数据,操作方式是同过SQL语句
sparkSql有哪些优势?
- 内存列存储
DataFrame(数据框,数据表)
DataFrame本质是一个RDD,底层是通过转化RDD来操作的,所以可以分布式Sql查询
SQLContext
- 上下文的对象,与SparkContext类似
数据转变DataFrame的方式: - RDD转变为DataFrame
// RDD转化DataFrame伪代码
val sqc = new SqlContext(sc)
val r1 = sc.makeRDD(List((1, "tom", 23), (2, "rose", 18), (3, "jim", 25), (4, "jary", 30)), 2)
//将RDD转化为 DataFrame
val df1 = sqc.createDataFrame(r1)
//列名与RDD元组一一对应
val df = df1.toDF("id","name","age") //--此步骤还可以
/*import sqc.implicits._
//
导入sqc的隐式转换模块之后,会隐式的将RDD转变为DataFrame,即省略的createDataFrame(rdd)
val df1=r1.toDF("id","name","age")
*/
//如果将DataFrame的结果存储,先需要转变为RDD再进行存储
val resultRDD=df1.toJavaRDD
resultRDD.saveAsTextFile("d://data/sql-result")
- 结构化文件数据转变DataFrame
- 将Json格式文件导入DataFrame
val tb= sqc.read.json("/home/word.json")
- 将MySQL数据表转化为DataFrame

//需要将mysql-Connect驱动导入spqrk的jars目录下
import org.apache.spark.sql.SQLContext
val sqc = new SQLContext(sc);
val prop = new java.util.Properties
prop.put("user","root")
prop.put("password","root")
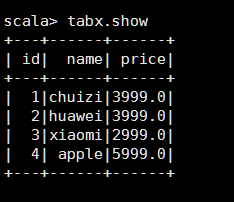
val tabx=sqc.read.jdbc("jdbc:mysql://hadoop01:3306/test","products",prop)
tabx.show()

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









