








常量类型
在 Tensorflow 中任何变量都需要转换为 Tensorflow 可以识别的类型,当然作为变量的特殊形式(不可改变)常量需要使用 tf.constant 存储或转换为张量类型 tf.Tensor ,当然可能不太贴切,所以Tensorflow 也创建了函数 tf.convert_to_tensor 实现了一样的功能,以常见的类型为例:
tf.constant(1) # 标量 shape 为 []
tf.constant(1.2) # 标量 shape 为 []
tf.constant(True) # 标量 shape 为 []
tf.constant("Hello World !") # 标量 shape 为 []
tf.constant([1,2,3,1,2,3]) # 向量 shape 为 [1]
tf.constant([[1,2,3],[1,2,3]]) # 矩阵 shape 为 [n,m]
tf.constant([[[1,2,3],[1,2,3]],[[1,2,3],[1,2,3]]]) # 张量 shape 为 [n,m,k,...]
变量类型
相比于常量类型,变量类型 tf.Variable 支持梯度信息的记录,其是一种待优化张量,在普通的张量类型基础上添加了 name,trainable 等属性来支持计算图的构建。由于梯度运算会消耗大量的计算资源,而且会自动更新相关参数,对于需要计算梯度并优化的张量,如神经网络层的 W 和 𝒃,需要通过 tf.Variable 包裹以便 TensorFlow 跟踪相关梯度信息。
var = tf.Variable(tf.constant([-1, 0, 1, 2]))
var.name,var.trainable
其中 trainable 表征当前张量是否需要被优化,创建 Variable 对象是默认启用优化标志,可以设置trainable=False 来设置张量不需要优化。
类型转换
这里所说的类型转换,实际上是精度的改变(不适用于将数值类型转换为字符串类型),比如从 bool 型转换为整型:
var = tf.constant([True, False])
tf.cast(var , tf.int32)
张量数据类型(data type)可以通过 .dtype 属性进行查看,同时 Tensorflow 也为(待优化和普通)张量类型提供了 .numpy() 接口便于转换为 numpy 类型。
常用张量生成
创建统一填充的张量
tf.zeros(shape) # 创建形状为 shape 的张量, 全为0的张量
tf.ones(shape) # 创建形状为 shape 的张量, 全为1的张量
tf.fill(shape, value = -1) # 创建形状为 shape 的张量, 全为value 的张量
创建形状为 shape 的张量,其数值服从正态分布 N ( mean, stddev 2 ) \mathcal { N } \left( \text {mean, stddev} ^ { 2 } \right) N(mean, stddev2) ,mean 为均值,stddev 为标准差:
tf.random.normal(shape, mean=0.0, stddev=1.0)
创建形状为 shape 的张量,其数值在区间 [minval,maxval] 区间上均匀分布
tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32)
创建 [start,limit) 之间,步长为 delta 的递增整形序列张量
tf.range(start, limit, delta=1)
索引与切片
当然在Tensorflow中,支持使用索引与切片操作提取张量的部分数据。在 TensorFlow 中,支持基本的[𝑗][𝑘]…标准索引方式,也支持通过逗号分隔索引号 [𝑗, 𝑘, …] 的索引方式。通过 [start : end : step] 的切片方式可以方便地提取一段数据,其中 start 为开始读取位置的索引,end 为结束读取位置的索引(不包含 end 位),step 为读取步长。当然为了避免 [:, :, :, n] 这样的情况可以使用 ... 表示取多个维度
上所有的数据,即除却以提供索引的维度的其他维度的所有数据。那么 [:, :, :, n] 可以表示为 […, n]。
形状改变
通过 tf.reshape(x, new_shape),可以对张量的视图进行任意的合法改变
x=tf.range(96)
x=tf.reshape(x,[2,4,4,3])
增删维度
增加维度:增加一个长度为 1 的维度相当于给原有的数据增加一个新维度的概念,维度长度为 1,故数据并不需要改变,仅仅是改变数据的理解方式,因此它其实可以理解为改变视图的一种特殊方式。通过 tf.expand_dims(x, axis) 可在指定的 axis 轴前可以插入一个新的维度:
x = tf.random.uniform([28,28],maxval=10,dtype=tf.int32)
x = tf.expand_dims(x,axis=2)
删除维度:是增加维度的逆操作,与增加维度一样,删除维度只能删除长度为 1 的维度,也不会改变张量的存储。如果希望将图片数量维度删除,可以通过 tf.squeeze(x, axis) 函数,axis 参数为待删除的维度的索引号。
x = tf.random.uniform([1,28,28,1],maxval=10,dtype=tf.int32)
tf.squeeze(x,axis=0)
当 axis = None 时,代表删除任意长度为 1 的维度。
交换维度
改变视图、增删维度都不会影响张量的存储。在实现算法逻辑时,在保持维度顺序不变的条件下,仅仅改变张量的理解方式是不够的,有时需要直接调整的存储顺序,即交换维度(Transpose)。通过交换维度,改变了张量的存储顺序,同时也改变了张量的视图。使用 tf.transpose(x, perm) 函数完成维度交换操作,其中 perm 表示新维度的顺序 List。
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,2,1,3])
数据复制
通过 tf.tile(x, multiples) 函数可以指定数据在指定维度上的复制操作,multiples 为每个维度上面的复制倍数的 List,对应位置为 1 表明不复制,为 n 表示复制为原来的 n 倍,也就是该维度长度会变为原来的 n 倍。
x = tf.range(4)
x = tf.reshape(x,[2,2])
x = tf.tile(x,multiples=[3,2])
不规则张量
一个张量的各个轴(维度)的元素个数不同叫做不规则(ragged),在 Tensorflow 中提出一种张量类型 tf.ragged.RaggedTensor 用于存储不规则数据。
ragged_list = [
[[0, 1, 2, 3]],
[[4], [5]],
[[6, 7], [8]],
[[9, 10, 11]]]
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
print(ragged_tensor.shape)
结果如下,观察可以看出该张量包含未知的维度即长度不统一:
<tf.RaggedTensor [[[0, 1, 2, 3]], [[4], [5]], [[6, 7], [8]], [[9, 10, 11]]]>
(4, None, None)
值得注意的是,tf.constant 是无法存储这种类型的张量的,可以使用以下语句尝试:
try:
tensor = tf.constant(ragged_list)
except Exception as e:
print(f"{type(e).__name__}: {e}")
可以获得所抛出的异常:
ValueError: Can't convert non-rectangular Python sequence to Tensor.
字符串张量
本节详细介绍一下字符串张量的一些特性。
字符串张量的声明:
# Tensors can be strings, too here is a scalar string.
scalar_string_tensor = tf.constant("Gray wolf")
print(scalar_string_tensor)
# If we have two string tensors of different lengths, this is OK.
tensor_of_strings = tf.constant(["Gray wolf",
"Quick brown fox",
"Lazy dog"])
# Note that the shape is (2,), indicating that it is 2 x unknown.
print(tensor_of_strings)
输出为:
tf.Tensor(b'Gray wolf', shape=(), dtype=string)
tf.Tensor([b'Gray wolf' b'Quick brown fox' b'Lazy dog'], shape=(3,), dtype=string)
当输入 unicode 字符时,将使用 utf-8 编码格式存储:
tf.constant("🥳👍")
输出为:
<tf.Tensor: shape=(), dtype=string, numpy=b'\xf0\x9f\xa5\xb3\xf0\x9f\x91\x8d'>
对于字符串张量可以使用字符串操作模块 tf.strings , 其中就包括 tf.strings.split。
# We can use split to split a string into a set of tensors
# ...but it turns into a `RaggedTensor` if we split up a tensor of strings,
# as each string might be split into a different number of parts.
print(tf.strings.split(scalar_string_tensor, sep=" "))
print(tf.strings.split(tensor_of_strings, sep=" "))
输出为:
tf.Tensor([b'Gray' b'wolf'], shape=(2,), dtype=string)
<tf.RaggedTensor [[b'Gray', b'wolf'], [b'Quick', b'brown', b'fox'], [b'Lazy', b'dog']]>
对于分割后长度不规则情况,将生成不规则张量进行存储:

同时字符串转换数字 tf.string.to_number 也很常用:
text = tf.constant("1 10 100")
print(tf.strings.to_number(tf.strings.split(text, " ")))
输出为:
tf.Tensor([ 1. 10. 100.], shape=(3,), dtype=float32)
虽然不能直接使用 tf.cast 直接将一个字符串张量转换为数字,但是可以将其转换为字节张量后再解码为数字张量.
byte_strings = tf.strings.bytes_split(tf.constant("Duck"))
byte_ints = tf.io.decode_raw(tf.constant("Duck"), tf.uint8)
print("Byte strings:", byte_strings)
print("Bytes:", byte_ints)
输出为:
Byte strings: tf.Tensor([b'D' b'u' b'c' b'k'], shape=(4,), dtype=string)
Bytes: tf.Tensor([ 68 117 99 107], shape=(4,), dtype=uint8)
当然也可以将其通过 Unicode 编码格式解码:
# Or split it up as unicode and then decode it
unicode_bytes = tf.constant("アヒル 🦆")
unicode_char_bytes = tf.strings.unicode_split(unicode_bytes, "UTF-8")
unicode_values = tf.strings.unicode_decode(unicode_bytes, "UTF-8")
print("Unicode bytes:", unicode_bytes)
print("\nUnicode chars:", unicode_char_bytes)
print("\nUnicode values:", unicode_values)
输出为:
Unicode bytes: tf.Tensor(b'\xe3\x82\xa2\xe3\x83\x92\xe3\x83\xab \xf0\x9f\xa6\x86', shape=(), dtype=string)
Unicode chars: tf.Tensor([b'\xe3\x82\xa2' b'\xe3\x83\x92' b'\xe3\x83\xab' b' ' b'\xf0\x9f\xa6\x86'], shape=(5,), dtype=string)
Unicode values: tf.Tensor([ 12450 12498 12523 32 129414], shape=(5,), dtype=int32)
稀疏张量
对于如下二维张量:
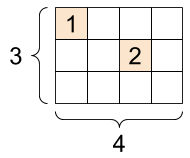
只有很少的元素不为零。那么可以使用以下语句进行存储和使用稀疏张量:
# Sparse tensors store values by index in a memory-efficient manner
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0],[0, 5], [1, 2]],
values=[1, 2, 3],
dense_shape=[3, 6])
print(sparse_tensor, "\n")
# We can convert sparse tensors to dense
print(tf.sparse.to_dense(sparse_tensor))
输出为:
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 5]
[1 2]], shape=(3, 2), dtype=int64), values=tf.Tensor([1 2 3], shape=(3,), dtype=int32), dense_shape=tf.Tensor([3 6], shape=(2,), dtype=int64))
tf.Tensor(
[[1 0 0 0 0 2]
[0 0 3 0 0 0]
[0 0 0 0 0 0]], shape=(3, 6), dtype=int32)














 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









